 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCornserve: A Distributed Serving System for Any-to-Any Multimodal Models
Mar 12, 2026Any-to-Any models are an emerging class of multimodal models that accept combinations of multimodal data (e.g., text, image, video, audio) as input and generate them as output. Serving these models are challenging; different requests with different input and output modalities traverse different paths through the model computation graph, and each component of the model have different scaling characteristics. We present Cornserve, a distributed serving system for generic Any-to-Any models. Cornserve provides a flexible task abstraction for expressing Any-to-Any model computation graphs, enabling component disaggregation and independent scaling. The distributed runtime dispatches compute to the data plane via an efficient record-and-replay execution model that keeps track of data dependencies, and forwards tensor data between components directly from the producer to the consumer. Built on Kubernetes with approximately 23K new lines of Python, Cornserve supports diverse Any-to-Any models and delivers up to 3.81$\times$ higher throughput and 5.79$\times$ lower tail latency. Cornserve is open-source, and the demo video is available on YouTube.
FedMOA: Federated GRPO for Personalized Reasoning LLMs under Heterogeneous Rewards
Jan 31, 2026Group Relative Policy Optimization (GRPO) has recently emerged as an effective approach for improving the reasoning capabilities of large language models through online multi-objective reinforcement learning. While personalization on private data is increasingly vital, traditional Reinforcement Learning (RL) alignment is often memory-prohibitive for on-device federated learning due to the overhead of maintaining a separate critic network. GRPO's critic-free architecture enables feasible on-device training, yet transitioning to a federated setting introduces systemic challenges: heterogeneous reward definitions, imbalanced multi-objective optimization, and high training costs. We propose FedMOA, a federated GRPO framework for multi-objective alignment under heterogeneous rewards. FedMOA stabilizes local training through an online adaptive weighting mechanism via hypergradient descent, which prioritizes primary reasoning as auxiliary objectives saturate. On the server side, it utilizes a task- and accuracy-aware aggregation strategy to prioritize high-quality updates. Experiments on mathematical reasoning and code generation benchmarks demonstrate that FedMOA consistently outperforms federated averaging, achieving accuracy gains of up to 2.2% while improving global performance, personalization, and multi-objective balance.
Erasing Your Voice Before It's Heard: Training-free Speaker Unlearning for Zero-shot Text-to-Speech
Jan 28, 2026Modern zero-shot text-to-speech (TTS) models offer unprecedented expressivity but also pose serious crime risks, as they can synthesize voices of individuals who never consented. In this context, speaker unlearning aims to prevent the generation of specific speaker identities upon request. Existing approaches, reliant on retraining, are costly and limited to speakers seen in the training set. We present TruS, a training-free speaker unlearning framework that shifts the paradigm from data deletion to inference-time control. TruS steers identity-specific hidden activations to suppress target speakers while preserving other attributes (e.g., prosody and emotion). Experimental results show that TruS effectively prevents voice generation on both seen and unseen opt-out speakers, establishing a scalable safeguard for speech synthesis. The demo and code are available on http://mmai.ewha.ac.kr/trus.
Making MoE-based LLM Inference Resilient with Tarragon
Jan 06, 2026Mixture-of-Experts (MoE) models are increasingly used to serve LLMs at scale, but failures become common as deployment scale grows. Existing systems exhibit poor failure resilience: even a single worker failure triggers a coarse-grained, service-wide restart, discarding accumulated progress and halting the entire inference pipeline during recovery--an approach clearly ill-suited for latency-sensitive, LLM services. We present Tarragon, a resilient MoE inference framework that confines the failures impact to individual workers while allowing the rest of the pipeline to continue making forward progress. Tarragon exploits the natural separation between the attention and expert computation in MoE-based transformers, treating attention workers (AWs) and expert workers (EWs) as distinct failure domains. Tarragon introduces a reconfigurable datapath to mask failures by rerouting requests to healthy workers. On top of this datapath, Tarragon implements a self-healing mechanism that relaxes the tightly synchronized execution of existing MoE frameworks. For stateful AWs, Tarragon performs asynchronous, incremental KV cache checkpointing with per-request restoration, and for stateless EWs, it leverages residual GPU memory to deploy shadow experts. These together keep recovery cost and recomputation overhead extremely low. Our evaluation shows that, compared to state-of-the-art MegaScale-Infer, Tarragon reduces failure-induced stalls by 160-213x (from ~64 s down to 0.3-0.4 s) while preserving performance when no failures occur.
Cornserve: Efficiently Serving Any-to-Any Multimodal Models
Dec 18, 2025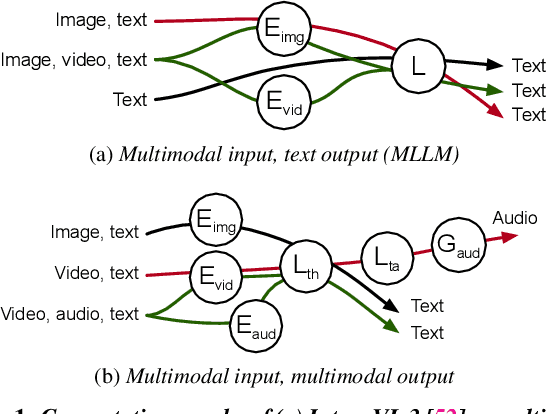
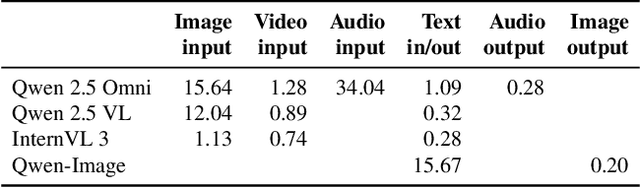
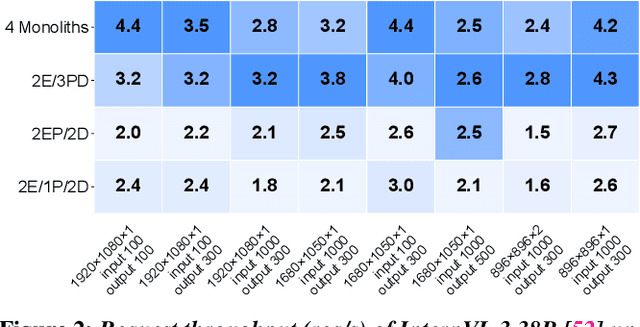
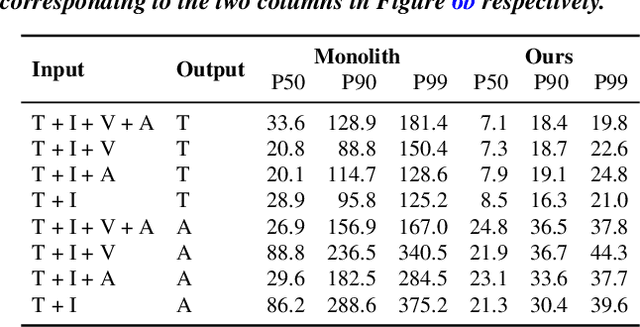
We present Cornserve, an efficient online serving system for an emerging class of multimodal models called Any-to-Any models. Any-to-Any models accept combinations of text and multimodal data (e.g., image, video, audio) as input and also generate combinations of text and multimodal data as output, introducing request type, computation path, and computation scaling heterogeneity in model serving. Cornserve allows model developers to describe the computation graph of generic Any-to-Any models, which consists of heterogeneous components such as multimodal encoders, autoregressive models like Large Language Models (LLMs), and multimodal generators like Diffusion Transformers (DiTs). Given this, Cornserve's planner automatically finds an optimized deployment plan for the model, including whether and how to disaggregate the model into smaller components based on model and workload characteristics. Cornserve's distributed runtime then executes the model per the plan, efficiently handling Any-to-Any model heterogeneity during online serving. Evaluations show that Cornserve can efficiently serve diverse Any-to-Any models and workloads, delivering up to 3.81$\times$ throughput improvement and up to 5.79$\times$ tail latency reduction over existing solutions.
On Harnessing Idle Compute at the Edge for Foundation Model Training
Dec 13, 2025The ecosystem behind foundation model development today is highly centralized and limited to large-scale cloud data center operators: training foundation models is costly, needing immense compute resources. Decentralized foundation model training across edge devices, leveraging their spare compute, promises a democratized alternative. However, existing edge-training approaches fall short: they struggle to match cloud-based training performance, exhibit limited scalability with model size, exceed device memory capacity, and have prohibitive communication overhead. They also fail to satisfactorily handle device heterogeneity and dynamism. We introduce a new paradigm, Cleave, which finely partitions training operations through a novel selective hybrid tensor parallelism method. Together with a parameter server centric training framework, Cleave copes with device memory limits and avoids communication bottlenecks, thereby enabling efficient training of large models on par with the cloud. Further, with a cost optimization model to guide device selection and training workload distribution, Cleave effectively accounts for device heterogeneity and churn. Our evaluations show that Cleave matches cloud-based GPU training by scaling efficiently to larger models and thousands of devices, supporting up to 8x more devices than baseline edge-training approaches. It outperforms state-of-the-art edge training methods by up to a factor of 10 in per-batch training time and efficiently handles device failures, achieving at least 100x faster recovery than prior methods.
Dora: QoE-Aware Hybrid Parallelism for Distributed Edge AI
Dec 09, 2025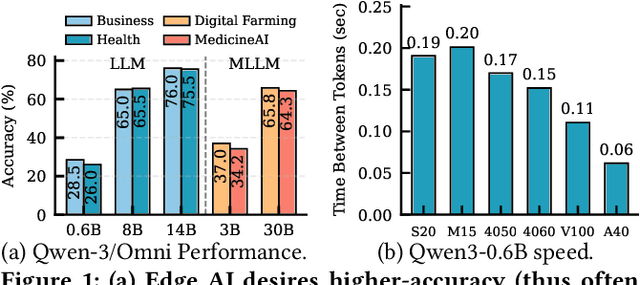
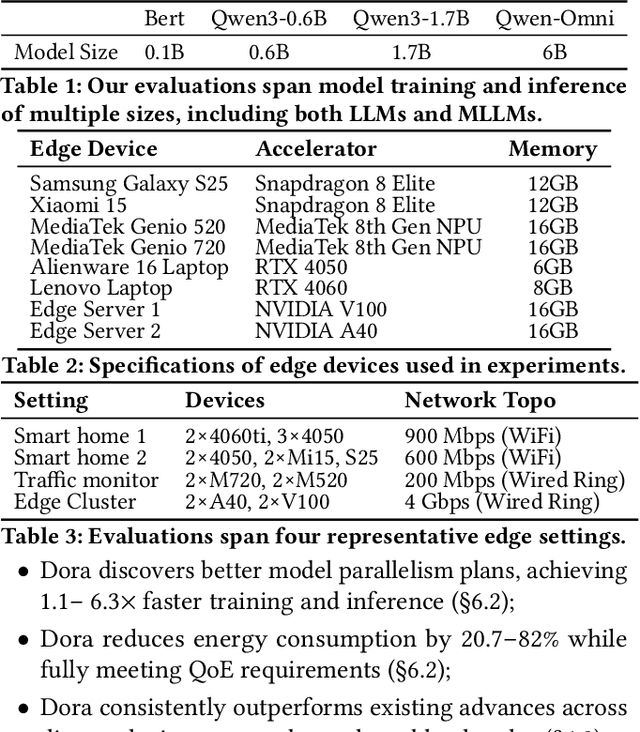
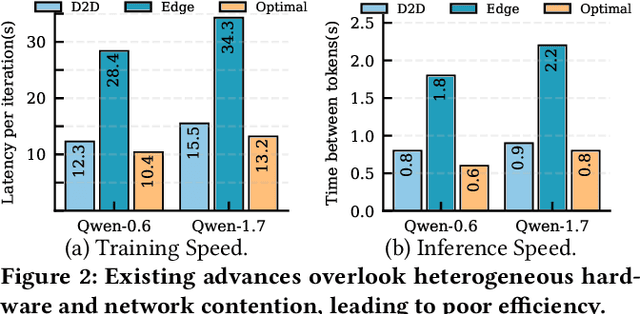
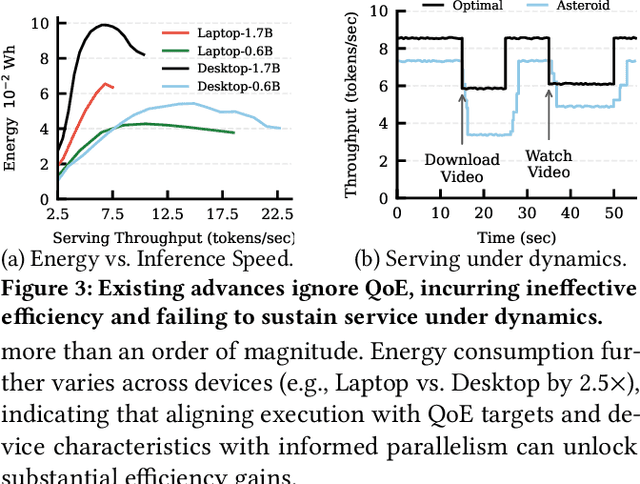
With the proliferation of edge AI applications, satisfying user quality of experience (QoE) requirements, such as model inference latency, has become a first class objective, as these models operate in resource constrained settings and directly interact with users. Yet, modern AI models routinely exceed the resource capacity of individual devices, necessitating distributed execution across heterogeneous devices over variable and contention prone networks. Existing planners for hybrid (e.g., data and pipeline) parallelism largely optimize for throughput or device utilization, overlooking QoE, leading to severe resource inefficiency (e.g., unnecessary energy drain) or QoE violations under runtime dynamics. We present Dora, a framework for QoE aware hybrid parallelism in distributed edge AI training and inference. Dora jointly optimizes heterogeneous computation, contention prone networks, and multi dimensional QoE objectives via three key mechanisms: (i) a heterogeneity aware model partitioner that determines and assigns model partitions across devices, forming a compact set of QoE compliant plans; (ii) a contention aware network scheduler that further refines these candidate plans by maximizing compute communication overlap; and (iii) a runtime adapter that adaptively composes multiple plans to maximize global efficiency while respecting overall QoEs. Across representative edge deployments, including smart homes, traffic analytics, and small edge clusters, Dora achieves 1.1--6.3 times faster execution and, alternatively, reduces energy consumption by 21--82 percent, all while maintaining QoE under runtime dynamics.
CountSteer: Steering Attention for Object Counting in Diffusion Models
Nov 14, 2025Text-to-image diffusion models generate realistic and coherent images but often fail to follow numerical instructions in text, revealing a gap between language and visual representation. Interestingly, we found that these models are not entirely blind to numbers-they are implicitly aware of their own counting accuracy, as their internal signals shift in consistent ways depending on whether the output meets the specified count. This observation suggests that the model already encodes a latent notion of numerical correctness, which can be harnessed to guide generation more precisely. Building on this intuition, we introduce CountSteer, a training-free method that improves generation of specified object counts by steering the model's cross-attention hidden states during inference. In our experiments, CountSteer improved object-count accuracy by about 4% without compromising visual quality, demonstrating a simple yet effective step toward more controllable and semantically reliable text-to-image generation.
SuperGen: An Efficient Ultra-high-resolution Video Generation System with Sketching and Tiling
Aug 25, 2025Diffusion models have recently achieved remarkable success in generative tasks (e.g., image and video generation), and the demand for high-quality content (e.g., 2K/4K videos) is rapidly increasing across various domains. However, generating ultra-high-resolution videos on existing standard-resolution (e.g., 720p) platforms remains challenging due to the excessive re-training requirements and prohibitively high computational and memory costs. To this end, we introduce SuperGen, an efficient tile-based framework for ultra-high-resolution video generation. SuperGen features a novel training-free algorithmic innovation with tiling to successfully support a wide range of resolutions without additional training efforts while significantly reducing both memory footprint and computational complexity. Moreover, SuperGen incorporates a tile-tailored, adaptive, region-aware caching strategy that accelerates video generation by exploiting redundancy across denoising steps and spatial regions. SuperGen also integrates cache-guided, communication-minimized tile parallelism for enhanced throughput and minimized latency. Evaluations demonstrate that SuperGen harvests the maximum performance gains while achieving high output quality across various benchmarks.
Towards Decentralized and Sustainable Foundation Model Training with the Edge
Jul 02, 2025Foundation models are at the forefront of AI research, appealing for their ability to learn from vast datasets and cater to diverse tasks. Yet, their significant computational demands raise issues of environmental impact and the risk of centralized control in their development. We put forward a vision towards decentralized and sustainable foundation model training that leverages the collective compute of sparingly used connected edge AI devices. We present the rationale behind our vision, particularly in support of its sustainability benefit. We further outline a set of challenges that need to be addressed to turn this vision into reality.