 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Contextual Bayesian Optimization
Apr 20, 2026Discovering optimal designs through sequential data collection is essential in many real-world applications. While Bayesian Optimization (BO) has achieved remarkable success in this setting, growing attention has recently turned to context-specific optimal design, formalized as Contextual Bayesian Optimization (CBO). Unlike BO, CBO is inherently more challenging as it must approximate an entire mapping from the context space to its corresponding optimal design, requiring simultaneous exploration across contexts and exploitation within each. In many modern applications, such tasks arise across multiple potentially heterogeneous but related clients, where collaboration can significantly improve learning efficiency. We propose CCBO, Collaborative Contextual Bayesian Optimization, a unified framework enabling multiple clients to jointly perform CBO with controllable contexts, supporting both online collaboration and offline initialization from peers' historical beliefs, with an optional privacy-preserving communication mechanism. We establish sublinear regret guarantees and demonstrate, through extensive simulations and a real-world hot rolling application, that CCBO achieves substantial improvements over existing approaches even under client heterogeneity. The code to reproduce the results can be found at https://github.com/cchihyu/Collaborative-Contextual-Bayesian-Optimization
Online Learning of Optimal Sequential Testing Policies
Sep 03, 2025



This paper studies an online learning problem that seeks optimal testing policies for a stream of subjects, each of whom can be evaluated through a sequence of candidate tests drawn from a common pool. We refer to this problem as the Online Testing Problem (OTP). Although conducting every candidate test for a subject provides more information, it is often preferable to select only a subset when tests are correlated and costly, and make decisions with partial information. If the joint distribution of test outcomes were known, the problem could be cast as a Markov Decision Process (MDP) and solved exactly. In practice, this distribution is unknown and must be learned online as subjects are tested. When a subject is not fully tested, the resulting missing data can bias estimates, making the problem fundamentally harder than standard episodic MDPs. We prove that the minimax regret must scale at least as $\Omega(T^{\frac{2}{3}})$, in contrast to the $\Theta(\sqrt{T})$ rate in episodic MDPs, revealing the difficulty introduced by missingness. This elevated lower bound is then matched by an Explore-Then-Commit algorithm whose cumulative regret is $\tilde{O}(T^{\frac{2}{3}})$ for both discrete and Gaussian distributions. To highlight the consequence of missingness-dependent rewards in OTP, we study a variant called the Online Cost-sensitive Maximum Entropy Sampling Problem, where rewards are independent of missing data. This structure enables an iterative-elimination algorithm that achieves $\tilde{O}(\sqrt{T})$ regret, breaking the $\Omega(T^{\frac{2}{3}})$ lower bound for OTP. Numerical results confirm our theory in both settings. Overall, this work deepens the understanding of the exploration--exploitation trade-off under missing data and guides the design of efficient sequential testing policies.
A Collaborative Process Parameter Recommender System for Fleets of Networked Manufacturing Machines -- with Application to 3D Printing
Jun 13, 2025Fleets of networked manufacturing machines of the same type, that are collocated or geographically distributed, are growing in popularity. An excellent example is the rise of 3D printing farms, which consist of multiple networked 3D printers operating in parallel, enabling faster production and efficient mass customization. However, optimizing process parameters across a fleet of manufacturing machines, even of the same type, remains a challenge due to machine-to-machine variability. Traditional trial-and-error approaches are inefficient, requiring extensive testing to determine optimal process parameters for an entire fleet. In this work, we introduce a machine learning-based collaborative recommender system that optimizes process parameters for each machine in a fleet by modeling the problem as a sequential matrix completion task. Our approach leverages spectral clustering and alternating least squares to iteratively refine parameter predictions, enabling real-time collaboration among the machines in a fleet while minimizing the number of experimental trials. We validate our method using a mini 3D printing farm consisting of ten 3D printers for which we optimize acceleration and speed settings to maximize print quality and productivity. Our approach achieves significantly faster convergence to optimal process parameters compared to non-collaborative matrix completion.
Inv-Entropy: A Fully Probabilistic Framework for Uncertainty Quantification in Language Models
Jun 11, 2025Large language models (LLMs) have transformed natural language processing, but their reliable deployment requires effective uncertainty quantification (UQ). Existing UQ methods are often heuristic and lack a probabilistic foundation. This paper begins by providing a theoretical justification for the role of perturbations in UQ for LLMs. We then introduce a dual random walk perspective, modeling input-output pairs as two Markov chains with transition probabilities defined by semantic similarity. Building on this, we propose a fully probabilistic framework based on an inverse model, which quantifies uncertainty by evaluating the diversity of the input space conditioned on a given output through systematic perturbations. Within this framework, we define a new uncertainty measure, Inv-Entropy. A key strength of our framework is its flexibility: it supports various definitions of uncertainty measures, embeddings, perturbation strategies, and similarity metrics. We also propose GAAP, a perturbation algorithm based on genetic algorithms, which enhances the diversity of sampled inputs. In addition, we introduce a new evaluation metric, Temperature Sensitivity of Uncertainty (TSU), which directly assesses uncertainty without relying on correctness as a proxy. Extensive experiments demonstrate that Inv-Entropy outperforms existing semantic UQ methods. The code to reproduce the results can be found at https://github.com/UMDataScienceLab/Uncertainty-Quantification-for-LLMs.
$\texttt{LLINBO}$: Trustworthy LLM-in-the-Loop Bayesian Optimization
May 20, 2025Bayesian optimization (BO) is a sequential decision-making tool widely used for optimizing expensive black-box functions. Recently, Large Language Models (LLMs) have shown remarkable adaptability in low-data regimes, making them promising tools for black-box optimization by leveraging contextual knowledge to propose high-quality query points. However, relying solely on LLMs as optimization agents introduces risks due to their lack of explicit surrogate modeling and calibrated uncertainty, as well as their inherently opaque internal mechanisms. This structural opacity makes it difficult to characterize or control the exploration-exploitation trade-off, ultimately undermining theoretical tractability and reliability. To address this, we propose LLINBO: LLM-in-the-Loop BO, a hybrid framework for BO that combines LLMs with statistical surrogate experts (e.g., Gaussian Processes (GP)). The core philosophy is to leverage contextual reasoning strengths of LLMs for early exploration, while relying on principled statistical models to guide efficient exploitation. Specifically, we introduce three mechanisms that enable this collaboration and establish their theoretical guarantees. We end the paper with a real-life proof-of-concept in the context of 3D printing. The code to reproduce the results can be found at https://github.com/UMDataScienceLab/LLM-in-the-Loop-BO.
Collaborative and Federated Black-box Optimization: A Bayesian Optimization Perspective
Nov 12, 2024We focus on collaborative and federated black-box optimization (BBOpt), where agents optimize their heterogeneous black-box functions through collaborative sequential experimentation. From a Bayesian optimization perspective, we address the fundamental challenges of distributed experimentation, heterogeneity, and privacy within BBOpt, and propose three unifying frameworks to tackle these issues: (i) a global framework where experiments are centrally coordinated, (ii) a local framework that allows agents to make decisions based on minimal shared information, and (iii) a predictive framework that enhances local surrogates through collaboration to improve decision-making. We categorize existing methods within these frameworks and highlight key open questions to unlock the full potential of federated BBOpt. Our overarching goal is to shift federated learning from its predominantly descriptive/predictive paradigm to a prescriptive one, particularly in the context of BBOpt - an inherently sequential decision-making problem.
The Traveling Bandit: A Framework for Bayesian Optimization with Movement Costs
Oct 18, 2024This paper introduces a framework for Bayesian Optimization (BO) with metric movement costs, addressing a critical challenge in practical applications where input alterations incur varying costs. Our approach is a convenient plug-in that seamlessly integrates with the existing literature on batched algorithms, where designs within batches are observed following the solution of a Traveling Salesman Problem. The proposed method provides a theoretical guarantee of convergence in terms of movement costs for BO. Empirically, our method effectively reduces average movement costs over time while maintaining comparable regret performance to conventional BO methods. This framework also shows promise for broader applications in various bandit settings with movement costs.
FCOM: A Federated Collaborative Online Monitoring Framework via Representation Learning
May 30, 2024Online learning has demonstrated notable potential to dynamically allocate limited resources to monitor a large population of processes, effectively balancing the exploitation of processes yielding high rewards, and the exploration of uncertain processes. However, most online learning algorithms were designed under 1) a centralized setting that requires data sharing across processes to obtain an accurate prediction or 2) a homogeneity assumption that estimates a single global model from the decentralized data. To facilitate the online learning of heterogeneous processes from the decentralized data, we propose a federated collaborative online monitoring method, which captures the latent representative models inherent in the population through representation learning and designs a novel federated collaborative UCB algorithm to estimate the representative models from sequentially observed decentralized data. The efficiency of our method is illustrated through theoretical analysis, simulation studies, and decentralized cognitive degradation monitoring in Alzheimer's disease.
Real-time Adaptation for Condition Monitoring Signal Prediction using Label-aware Neural Processes
Mar 25, 2024Building a predictive model that rapidly adapts to real-time condition monitoring (CM) signals is critical for engineering systems/units. Unfortunately, many current methods suffer from a trade-off between representation power and agility in online settings. For instance, parametric methods that assume an underlying functional form for CM signals facilitate efficient online prediction updates. However, this simplification leads to vulnerability to model specifications and an inability to capture complex signals. On the other hand, approaches based on over-parameterized or non-parametric models can excel at explaining complex nonlinear signals, but real-time updates for such models pose a challenging task. In this paper, we propose a neural process-based approach that addresses this trade-off. It encodes available observations within a CM signal into a representation space and then reconstructs the signal's history and evolution for prediction. Once trained, the model can encode an arbitrary number of observations without requiring retraining, enabling on-the-spot real-time predictions along with quantified uncertainty and can be readily updated as more online data is gathered. Furthermore, our model is designed to incorporate qualitative information (i.e., labels) from individual units. This integration not only enhances individualized predictions for each unit but also enables joint inference for both signals and their associated labels. Numerical studies on both synthetic and real-world data in reliability engineering highlight the advantageous features of our model in real-time adaptation, enhanced signal prediction with uncertainty quantification, and joint prediction for labels and signals.
SEE-OoD: Supervised Exploration For Enhanced Out-of-Distribution Detection
Oct 12, 2023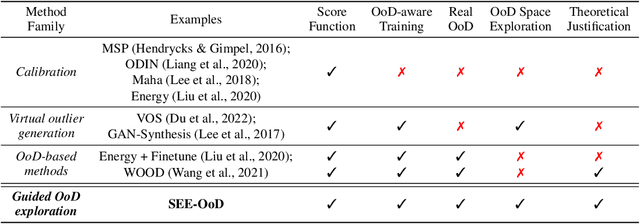
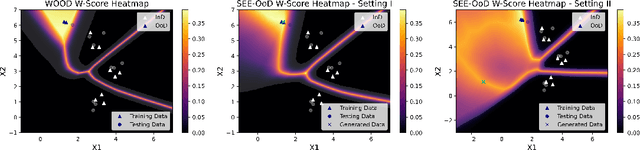
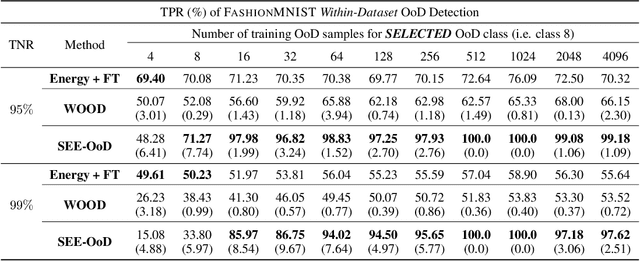
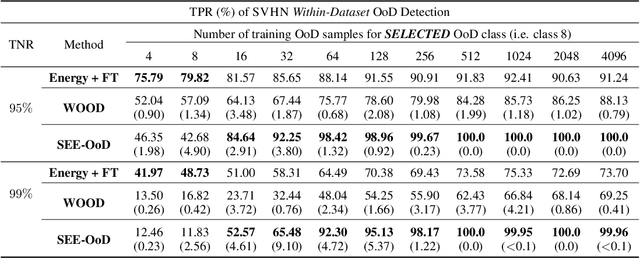
Current techniques for Out-of-Distribution (OoD) detection predominantly rely on quantifying predictive uncertainty and incorporating model regularization during the training phase, using either real or synthetic OoD samples. However, methods that utilize real OoD samples lack exploration and are prone to overfit the OoD samples at hand. Whereas synthetic samples are often generated based on features extracted from training data, rendering them less effective when the training and OoD data are highly overlapped in the feature space. In this work, we propose a Wasserstein-score-based generative adversarial training scheme to enhance OoD detection accuracy, which, for the first time, performs data augmentation and exploration simultaneously under the supervision of limited OoD samples. Specifically, the generator explores OoD spaces and generates synthetic OoD samples using feedback from the discriminator, while the discriminator exploits both the observed and synthesized samples for OoD detection using a predefined Wasserstein score. We provide theoretical guarantees that the optimal solutions of our generative scheme are statistically achievable through adversarial training in empirical settings. We then demonstrate that the proposed method outperforms state-of-the-art techniques on various computer vision datasets and exhibits superior generalizability to unseen OoD data.