 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLMT: A Bayesian Framework for Causal Discovery from Textual Alarm Records in Manufacturing Systems
Jun 03, 2026Textual event records, such as alarm logs, have become an increasingly common data source in engineering and manufacturing systems. Beyond identifying correlations or recurring patterns, engineers are often interested in understanding which types of events causally trigger or influence other events during system operation. Textual event descriptions may contain semantic clues about such causal relationships, and recent large language models (LLMs) provide a promising tool for extracting these signals. However, relying solely on LLM-encoded textual information is insufficient for accurate causal discovery, since semantic patterns do not directly reveal causal mechanisms and may confuse causation with correlation or frequent sequential patterns. To address these challenges, we propose \textbf{LMT}, a Bayesian causal discovery framework for engineering event data that jointly leverages textual descriptions and timestamps. Specifically, LMT first uses LLMs to extract semantic causal signals from event descriptions and constructs a prior distribution over causal graphs among event types or event clusters. It then incorporates temporal evidence through a Poisson-process-based likelihood, allowing the LLM-informed prior to be refined by timestamp-based statistical evidence. By integrating the textual and temporal information, LMT produces a causal graph that is both interpretable and data-supported. Simulation studies show that the proposed framework is effective across different settings and is especially advantageous in small-sample alarm-event scenarios.
CausalGDP: Causality-Guided Diffusion Policies for Reinforcement Learning
Feb 09, 2026Reinforcement learning (RL) has achieved remarkable success in a wide range of sequential decision-making problems. Recent diffusion-based policies further improve RL by modeling complex, high-dimensional action distributions. However, existing diffusion policies primarily rely on statistical associations and fail to explicitly account for causal relationships among states, actions, and rewards, limiting their ability to identify which action components truly cause high returns. In this paper, we propose Causality-guided Diffusion Policy (CausalGDP), a unified framework that integrates causal reasoning into diffusion-based RL. CausalGDP first learns a base diffusion policy and an initial causal dynamical model from offline data, capturing causal dependencies among states, actions, and rewards. During real-time interaction, the causal information is continuously updated and incorporated as a guidance signal to steer the diffusion process toward actions that causally influence future states and rewards. By explicitly considering causality beyond association, CausalGDP focuses policy optimization on action components that genuinely drive performance improvements. Experimental results demonstrate that CausalGDP consistently achieves competitive or superior performance over state-of-the-art diffusion-based and offline RL methods, especially in complex, high-dimensional control tasks.
Physics as the Inductive Bias for Causal Discovery
Feb 03, 2026Causal discovery is often a data-driven paradigm to analyze complex real-world systems. In parallel, physics-based models such as ordinary differential equations (ODEs) provide mechanistic structure for many dynamical processes. Integrating these paradigms potentially allows physical knowledge to act as an inductive bias, improving identifiability, stability, and robustness of causal discovery in dynamical systems. However, such integration remains challenging: real dynamical systems often exhibit feedback, cyclic interactions, and non-stationary data trend, while many widely used causal discovery methods are formulated under acyclicity or equilibrium-based assumptions. In this work, we propose an integrative causal discovery framework for dynamical systems that leverages partial physical knowledge as an inductive bias. Specifically, we model system evolution as a stochastic differential equation (SDE), where the drift term encodes known ODE dynamics and the diffusion term corresponds to unknown causal couplings beyond the prescribed physics. We develop a scalable sparsity-inducing MLE algorithm that exploits causal graph structure for efficient parameter estimation. Under mild conditions, we establish guarantees to recover the causal graph. Experiments on dynamical systems with diverse causal structures show that our approach improves causal graph recovery and produces more stable, physically consistent estimates than purely data-driven state-of-the-art baselines.
Toward Temporal Causal Representation Learning with Tensor Decomposition
Jul 18, 2025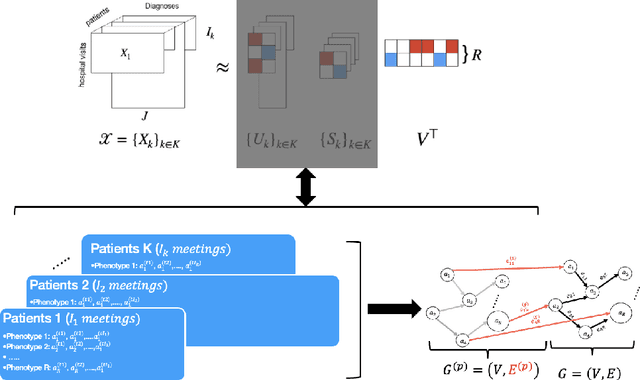
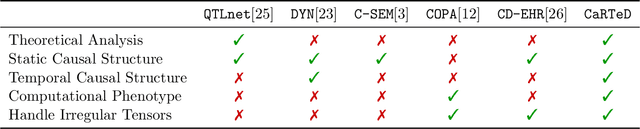
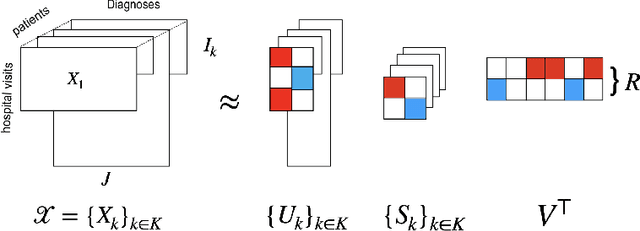
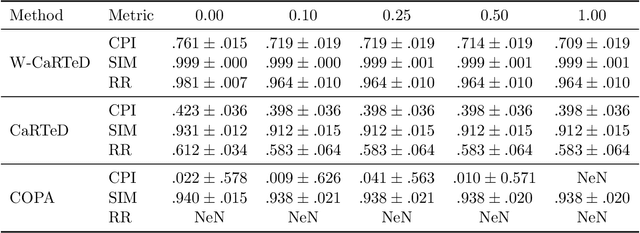
Temporal causal representation learning is a powerful tool for uncovering complex patterns in observational studies, which are often represented as low-dimensional time series. However, in many real-world applications, data are high-dimensional with varying input lengths and naturally take the form of irregular tensors. To analyze such data, irregular tensor decomposition is critical for extracting meaningful clusters that capture essential information. In this paper, we focus on modeling causal representation learning based on the transformed information. First, we present a novel causal formulation for a set of latent clusters. We then propose CaRTeD, a joint learning framework that integrates temporal causal representation learning with irregular tensor decomposition. Notably, our framework provides a blueprint for downstream tasks using the learned tensor factors, such as modeling latent structures and extracting causal information, and offers a more flexible regularization design to enhance tensor decomposition. Theoretically, we show that our algorithm converges to a stationary point. More importantly, our results fill the gap in theoretical guarantees for the convergence of state-of-the-art irregular tensor decomposition. Experimental results on synthetic and real-world electronic health record (EHR) datasets (MIMIC-III), with extensive benchmarks from both phenotyping and network recovery perspectives, demonstrate that our proposed method outperforms state-of-the-art techniques and enhances the explainability of causal representations.
Fed-Joint: Joint Modeling of Nonlinear Degradation Signals and Failure Events for Remaining Useful Life Prediction using Federated Learning
Mar 17, 2025
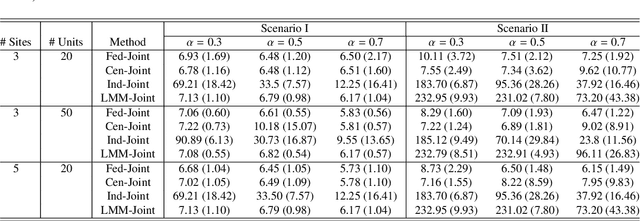


Many failure mechanisms of machinery are closely related to the behavior of condition monitoring (CM) signals. To achieve a cost-effective preventive maintenance strategy, accurate remaining useful life (RUL) prediction based on the signals is of paramount importance. However, the CM signals are often recorded at different factories and production lines, with limited amounts of data. Unfortunately, these datasets have rarely been shared between the sites due to data confidentiality and ownership issues, a lack of computing and storage power, and high communication costs associated with data transfer between sites and a data center. Another challenge in real applications is that the CM signals are often not explicitly specified \textit{a priori}, meaning that existing methods, which often usually a parametric form, may not be applicable. To address these challenges, we propose a new prognostic framework for RUL prediction using the joint modeling of nonlinear degradation signals and time-to-failure data within a federated learning scheme. The proposed method constructs a nonparametric degradation model using a federated multi-output Gaussian process and then employs a federated survival model to predict failure times and probabilities for in-service machinery. The superiority of the proposed method over other alternatives is demonstrated through comprehensive simulation studies and a case study using turbofan engine degradation signal data that include run-to-failure events.
Explainable Federated Bayesian Causal Inference and Its Application in Advanced Manufacturing
Jan 10, 2025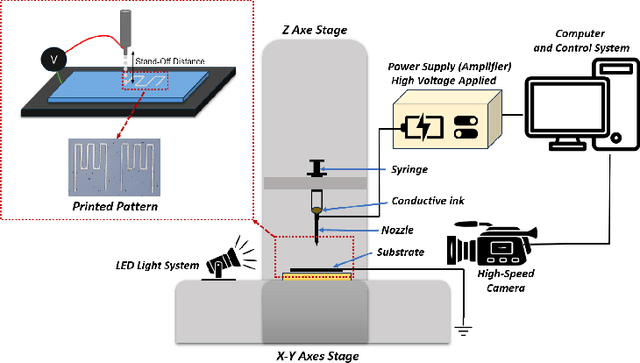
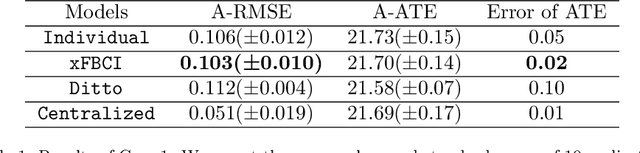
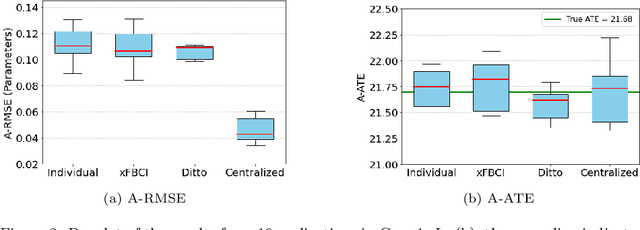
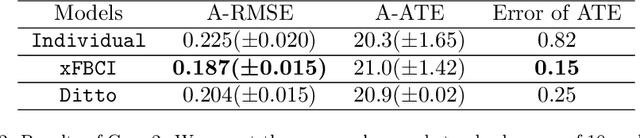
Causal inference has recently gained notable attention across various fields like biology, healthcare, and environmental science, especially within explainable artificial intelligence (xAI) systems, for uncovering the causal relationships among multiple variables and outcomes. Yet, it has not been fully recognized and deployed in the manufacturing systems. In this paper, we introduce an explainable, scalable, and flexible federated Bayesian learning framework, \texttt{xFBCI}, designed to explore causality through treatment effect estimation in distributed manufacturing systems. By leveraging federated Bayesian learning, we efficiently estimate posterior of local parameters to derive the propensity score for each client without accessing local private data. These scores are then used to estimate the treatment effect using propensity score matching (PSM). Through simulations on various datasets and a real-world Electrohydrodynamic (EHD) printing data, we demonstrate that our approach outperforms standard Bayesian causal inference methods and several state-of-the-art federated learning benchmarks.
Temporal Causal Discovery in Dynamic Bayesian Networks Using Federated Learning
Dec 13, 2024



Traditionally, learning the structure of a Dynamic Bayesian Network has been centralized, with all data pooled in one location. However, in real-world scenarios, data are often dispersed among multiple parties (e.g., companies, devices) that aim to collaboratively learn a Dynamic Bayesian Network while preserving their data privacy and security. In this study, we introduce a federated learning approach for estimating the structure of a Dynamic Bayesian Network from data distributed horizontally across different parties. We propose a distributed structure learning method that leverages continuous optimization so that only model parameters are exchanged during optimization. Experimental results on synthetic and real datasets reveal that our method outperforms other state-of-the-art techniques, particularly when there are many clients with limited individual sample sizes.
Collaborative and Distributed Bayesian Optimization via Consensus: Showcasing the Power of Collaboration for Optimal Design
Jun 25, 2023Optimal design is a critical yet challenging task within many applications. This challenge arises from the need for extensive trial and error, often done through simulations or running field experiments. Fortunately, sequential optimal design, also referred to as Bayesian optimization when using surrogates with a Bayesian flavor, has played a key role in accelerating the design process through efficient sequential sampling strategies. However, a key opportunity exists nowadays. The increased connectivity of edge devices sets forth a new collaborative paradigm for Bayesian optimization. A paradigm whereby different clients collaboratively borrow strength from each other by effectively distributing their experimentation efforts to improve and fast-track their optimal design process. To this end, we bring the notion of consensus to Bayesian optimization, where clients agree (i.e., reach a consensus) on their next-to-sample designs. Our approach provides a generic and flexible framework that can incorporate different collaboration mechanisms. In lieu of this, we propose transitional collaborative mechanisms where clients initially rely more on each other to maneuver through the early stages with scant data, then, at the late stages, focus on their own objectives to get client-specific solutions. Theoretically, we show the sub-linear growth in regret for our proposed framework. Empirically, through simulated datasets and a real-world collaborative material discovery experiment, we show that our framework can effectively accelerate and improve the optimal design process and benefit all participants.
Federated Data Analytics: A Study on Linear Models
Jun 15, 2022
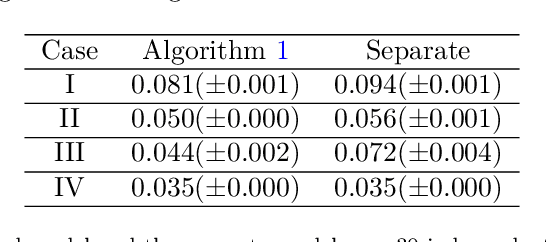

As edge devices become increasingly powerful, data analytics are gradually moving from a centralized to a decentralized regime where edge compute resources are exploited to process more of the data locally. This regime of analytics is coined as federated data analytics (FDA). In spite of the recent success stories of FDA, most literature focuses exclusively on deep neural networks. In this work, we take a step back to develop an FDA treatment for one of the most fundamental statistical models: linear regression. Our treatment is built upon hierarchical modeling that allows borrowing strength across multiple groups. To this end, we propose two federated hierarchical model structures that provide a shared representation across devices to facilitate information sharing. Notably, our proposed frameworks are capable of providing uncertainty quantification, variable selection, hypothesis testing and fast adaptation to new unseen data. We validate our methods on a range of real-life applications including condition monitoring for aircraft engines. The results show that our FDA treatment for linear models can serve as a competing benchmark model for future development of federated algorithms.
Self-scalable Tanh (Stan): Faster Convergence and Better Generalization in Physics-informed Neural Networks
Apr 29, 2022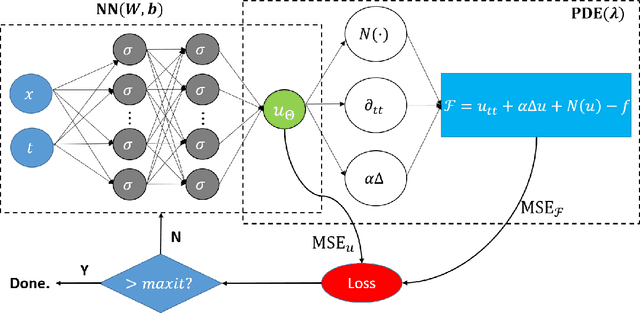
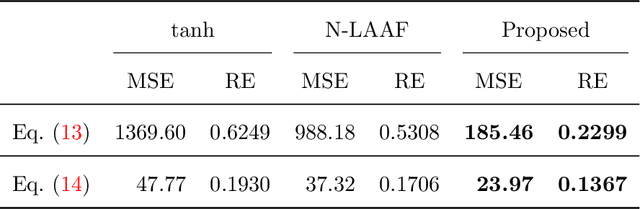
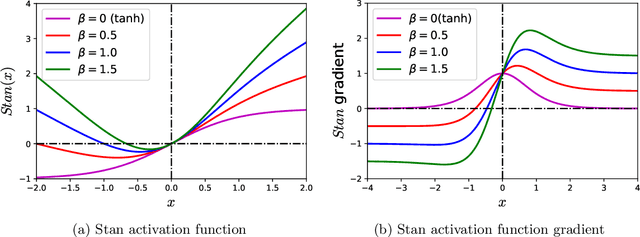
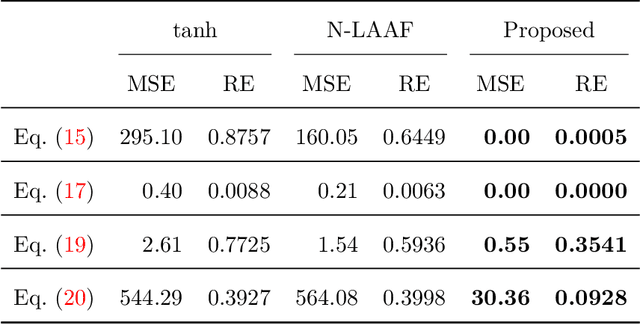
Physics-informed Neural Networks (PINNs) are gaining attention in the engineering and scientific literature for solving a range of differential equations with applications in weather modeling, healthcare, manufacturing, etc. Poor scalability is one of the barriers to utilizing PINNs for many real-world problems. To address this, a Self-scalable tanh (Stan) activation function is proposed for the PINNs. The proposed Stan function is smooth, non-saturating, and has a trainable parameter. During training, it can allow easy flow of gradients to compute the required derivatives and also enable systematic scaling of the input-output mapping. It is shown theoretically that the PINNs with the proposed Stan function have no spurious stationary points when using gradient descent algorithms. The proposed Stan is tested on a number of numerical studies involving general regression problems. It is subsequently used for solving multiple forward problems, which involve second-order derivatives and multiple dimensions, and an inverse problem where the thermal diffusivity of a rod is predicted with heat conduction data. These case studies establish empirically that the Stan activation function can achieve better training and more accurate predictions than the existing activation functions in the literature.