 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Additive Manufacturing through Deep Learning: A Comprehensive Review of Current Progress and Future Challenges
Mar 01, 2024



Additive manufacturing (AM) has already proved itself to be the potential alternative to widely-used subtractive manufacturing due to its extraordinary capacity of manufacturing highly customized products with minimum material wastage. Nevertheless, it is still not being considered as the primary choice for the industry due to some of its major inherent challenges, including complex and dynamic process interactions, which are sometimes difficult to fully understand even with traditional machine learning because of the involvement of high-dimensional data such as images, point clouds, and voxels. However, the recent emergence of deep learning (DL) is showing great promise in overcoming many of these challenges as DL can automatically capture complex relationships from high-dimensional data without hand-crafted feature extraction. Therefore, the volume of research in the intersection of AM and DL is exponentially growing each year which makes it difficult for the researchers to keep track of the trend and future potential directions. Furthermore, to the best of our knowledge, there is no comprehensive review paper in this research track summarizing the recent studies. Therefore, this paper reviews the recent studies that apply DL for making the AM process better with a high-level summary of their contributions and limitations. Finally, it summarizes the current challenges and recommends some of the promising opportunities in this domain for further investigation with a special focus on generalizing DL models for wide-range of geometry types, managing uncertainties both in AM data and DL models, overcoming limited and noisy AM data issues by incorporating generative models, and unveiling the potential of interpretable DL for AM.
Imbalanced Data Classification via Generative Adversarial Network with Application to Anomaly Detection in Additive Manufacturing Process
Nov 09, 2022Supervised classification methods have been widely utilized for the quality assurance of the advanced manufacturing process, such as additive manufacturing (AM) for anomaly (defects) detection. However, since abnormal states (with defects) occur much less frequently than normal ones (without defects) in the manufacturing process, the number of sensor data samples collected from a normal state outweighs that from an abnormal state. This issue causes imbalanced training data for classification models, thus deteriorating the performance of detecting abnormal states in the process. It is beneficial to generate effective artificial sample data for the abnormal states to make a more balanced training set. To achieve this goal, this paper proposes a novel data augmentation method based on a generative adversarial network (GAN) using additive manufacturing process image sensor data. The novelty of our approach is that a standard GAN and classifier are jointly optimized with techniques to stabilize the learning process of standard GAN. The diverse and high-quality generated samples provide balanced training data to the classifier. The iterative optimization between GAN and classifier provides the high-performance classifier. The effectiveness of the proposed method is validated by both open-source data and real-world case studies in polymer and metal AM processes.
A Novel Sparse Bayesian Learning and Its Application to Fault Diagnosis for Multistation Assembly Systems
Oct 28, 2022This paper addresses the problem of fault diagnosis in multistation assembly systems. Fault diagnosis is to identify process faults that cause the excessive dimensional variation of the product using dimensional measurements. For such problems, the challenge is solving an underdetermined system caused by a common phenomenon in practice; namely, the number of measurements is less than that of the process errors. To address this challenge, this paper attempts to solve the following two problems: (1) how to utilize the temporal correlation in the time series data of each process error and (2) how to apply prior knowledge regarding which process errors are more likely to be process faults. A novel sparse Bayesian learning method is proposed to achieve the above objectives. The method consists of three hierarchical layers. The first layer has parameterized prior distribution that exploits the temporal correlation of each process error. Furthermore, the second and third layers achieve the prior distribution representing the prior knowledge of process faults. Then, these prior distributions are updated with the likelihood function of the measurement samples from the process, resulting in the accurate posterior distribution of process faults from an underdetermined system. Since posterior distributions of process faults are intractable, this paper derives approximate posterior distributions via Variational Bayes inference. Numerical and simulation case studies using an actual autobody assembly process are performed to demonstrate the effectiveness of the proposed method.
Reinforcement Learning-based Defect Mitigation for Quality Assurance of Additive Manufacturing
Oct 28, 2022



Additive Manufacturing (AM) is a powerful technology that produces complex 3D geometries using various materials in a layer-by-layer fashion. However, quality assurance is the main challenge in AM industry due to the possible time-varying processing conditions during AM process. Notably, new defects may occur during printing, which cannot be mitigated by offline analysis tools that focus on existing defects. This challenge motivates this work to develop online learning-based methods to deal with the new defects during printing. Since AM typically fabricates a small number of customized products, this paper aims to create an online learning-based strategy to mitigate the new defects in AM process while minimizing the number of samples needed. The proposed method is based on model-free Reinforcement Learning (RL). It is called Continual G-learning since it transfers several sources of prior knowledge to reduce the needed training samples in the AM process. Offline knowledge is obtained from literature, while online knowledge is learned during printing. The proposed method develops a new algorithm for learning the optimal defect mitigation strategies proven the best performance when utilizing both knowledge sources. Numerical and real-world case studies in a fused filament fabrication (FFF) platform are performed and demonstrate the effectiveness of the proposed method.
Self-scalable Tanh (Stan): Faster Convergence and Better Generalization in Physics-informed Neural Networks
Apr 29, 2022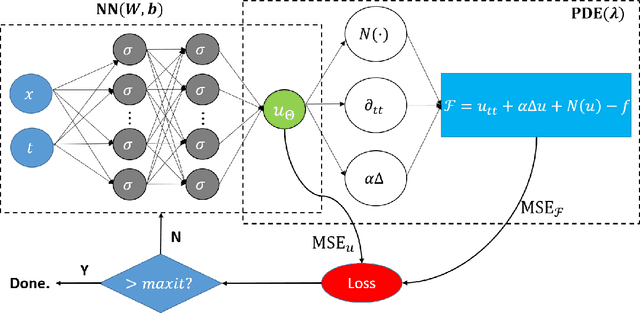
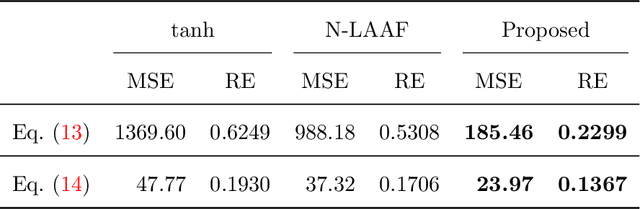
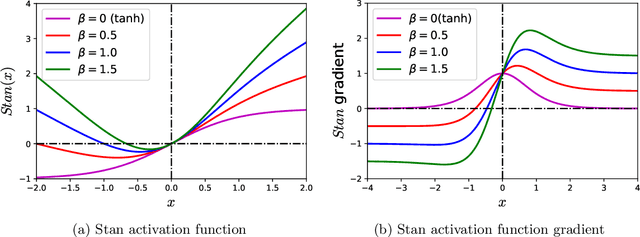
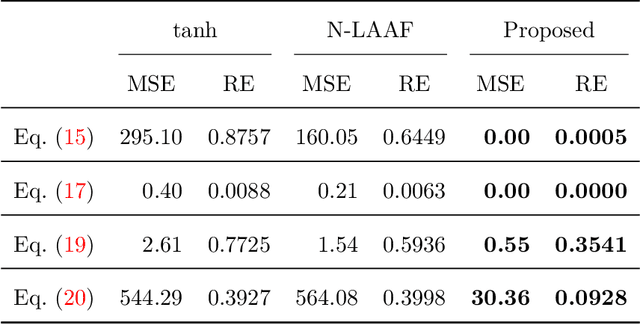
Physics-informed Neural Networks (PINNs) are gaining attention in the engineering and scientific literature for solving a range of differential equations with applications in weather modeling, healthcare, manufacturing, etc. Poor scalability is one of the barriers to utilizing PINNs for many real-world problems. To address this, a Self-scalable tanh (Stan) activation function is proposed for the PINNs. The proposed Stan function is smooth, non-saturating, and has a trainable parameter. During training, it can allow easy flow of gradients to compute the required derivatives and also enable systematic scaling of the input-output mapping. It is shown theoretically that the PINNs with the proposed Stan function have no spurious stationary points when using gradient descent algorithms. The proposed Stan is tested on a number of numerical studies involving general regression problems. It is subsequently used for solving multiple forward problems, which involve second-order derivatives and multiple dimensions, and an inverse problem where the thermal diffusivity of a rod is predicted with heat conduction data. These case studies establish empirically that the Stan activation function can achieve better training and more accurate predictions than the existing activation functions in the literature.
Robust Tensor Principal Component Analysis: Exact Recovery via Deterministic Model
Aug 05, 2020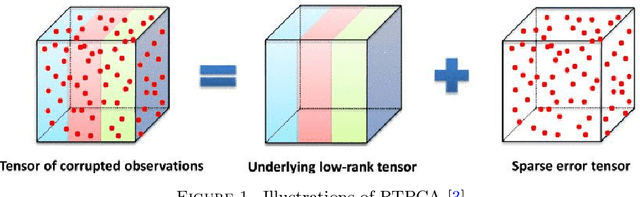

Tensor, also known as multi-dimensional array, arises from many applications in signal processing, manufacturing processes, healthcare, among others. As one of the most popular methods in tensor literature, Robust tensor principal component analysis (RTPCA) is a very effective tool to extract the low rank and sparse components in tensors. In this paper, a new method to analyze RTPCA is proposed based on the recently developed tensor-tensor product and tensor singular value decomposition (t-SVD). Specifically, it aims to solve a convex optimization problem whose objective function is a weighted combination of the tensor nuclear norm and the l1-norm. In most of literature of RTPCA, the exact recovery is built on the tensor incoherence conditions and the assumption of a uniform model on the sparse support. Unlike this conventional way, in this paper, without any assumption of randomness, the exact recovery can be achieved in a completely deterministic fashion by characterizing the tensor rank-sparsity incoherence, which is an uncertainty principle between the low-rank tensor spaces and the pattern of sparse tensor.
A Method for Robust Online Classification using Dictionary Learning: Development and Assessment for Monitoring Manual Material Handling Activities Using Wearable Sensors
Oct 22, 2018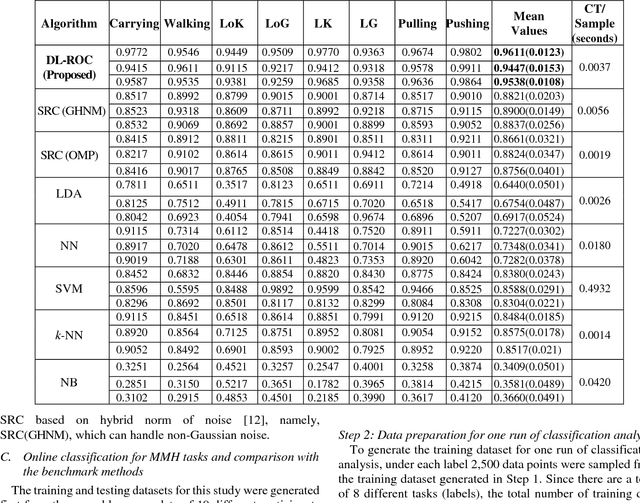
Classification methods based on sparse estimation have drawn much attention recently, due to their effectiveness in processing high-dimensional data such as images. In this paper, a method to improve the performance of a sparse representation classification (SRC) approach is proposed; it is then applied to the problem of online process monitoring of human workers, specifically manual material handling (MMH) operations monitored using wearable sensors (involving 111 sensor channels). Our proposed method optimizes the design matrix (aka dictionary) in the linear model used for SRC, minimizing its ill-posedness to achieve a sparse solution. This procedure is based on the idea of dictionary learning (DL): we optimize the design matrix formed by training datasets to minimize both redundancy and coherency as well as reducing the size of these datasets. Use of such optimized training data can subsequently improve classification accuracy and help decrease the computational time needed for the SRC; it is thus more applicable for online process monitoring. Performance of the proposed methodology is demonstrated using wearable sensor data obtained from manual material handling experiments, and is found to be superior to those of benchmark methods in terms of accuracy, while also requiring computational time appropriate for MMH online monitoring.