 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairness in Machine Learning-based Hand Load Estimation: A Case Study on Load Carriage Tasks
Apr 08, 2025



Predicting external hand load from sensor data is essential for ergonomic exposure assessments, as obtaining this information typically requires direct observation or supplementary data. While machine learning methods have been used to estimate external hand load from worker postures or force exertion data, our findings reveal systematic bias in these predictions due to individual differences such as age and biological sex. To explore this issue, we examined bias in hand load prediction by varying the sex ratio in the training dataset. We found substantial sex disparity in predictive performance, especially when the training dataset is more sex-imbalanced. To address this bias, we developed and evaluated a fair predictive model for hand load estimation that leverages a Variational Autoencoder (VAE) with feature disentanglement. This approach is designed to separate sex-agnostic and sex-specific latent features, minimizing feature overlap. The disentanglement capability enables the model to make predictions based solely on sex-agnostic features of motion patterns, ensuring fair prediction for both biological sexes. Our proposed fair algorithm outperformed conventional machine learning methods (e.g., Random Forests) in both fairness and predictive accuracy, achieving a lower mean absolute error (MAE) difference across male and female sets and improved fairness metrics such as statistical parity (SP) and positive and negative residual differences (PRD and NRD), even when trained on imbalanced sex datasets. These findings emphasize the importance of fairness-aware machine learning algorithms to prevent potential disadvantages in workplace health and safety for certain worker populations.
Fed-Joint: Joint Modeling of Nonlinear Degradation Signals and Failure Events for Remaining Useful Life Prediction using Federated Learning
Mar 17, 2025
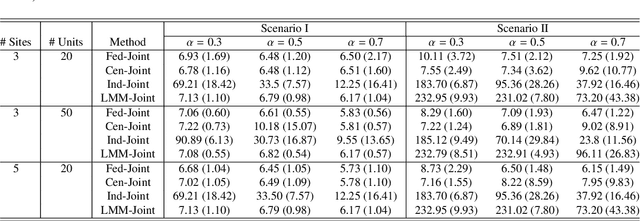


Many failure mechanisms of machinery are closely related to the behavior of condition monitoring (CM) signals. To achieve a cost-effective preventive maintenance strategy, accurate remaining useful life (RUL) prediction based on the signals is of paramount importance. However, the CM signals are often recorded at different factories and production lines, with limited amounts of data. Unfortunately, these datasets have rarely been shared between the sites due to data confidentiality and ownership issues, a lack of computing and storage power, and high communication costs associated with data transfer between sites and a data center. Another challenge in real applications is that the CM signals are often not explicitly specified \textit{a priori}, meaning that existing methods, which often usually a parametric form, may not be applicable. To address these challenges, we propose a new prognostic framework for RUL prediction using the joint modeling of nonlinear degradation signals and time-to-failure data within a federated learning scheme. The proposed method constructs a nonparametric degradation model using a federated multi-output Gaussian process and then employs a federated survival model to predict failure times and probabilities for in-service machinery. The superiority of the proposed method over other alternatives is demonstrated through comprehensive simulation studies and a case study using turbofan engine degradation signal data that include run-to-failure events.
Federated Automatic Latent Variable Selection in Multi-output Gaussian Processes
Jul 24, 2024This paper explores a federated learning approach that automatically selects the number of latent processes in multi-output Gaussian processes (MGPs). The MGP has seen great success as a transfer learning tool when data is generated from multiple sources/units/entities. A common approach in MGPs to transfer knowledge across units involves gathering all data from each unit to a central server and extracting common independent latent processes to express each unit as a linear combination of the shared latent patterns. However, this approach poses key challenges in (i) determining the adequate number of latent processes and (ii) relying on centralized learning which leads to potential privacy risks and significant computational burdens on the central server. To address these issues, we propose a hierarchical model that places spike-and-slab priors on the coefficients of each latent process. These priors help automatically select only needed latent processes by shrinking the coefficients of unnecessary ones to zero. To estimate the model while avoiding the drawbacks of centralized learning, we propose a variational inference-based approach, that formulates model inference as an optimization problem compatible with federated settings. We then design a federated learning algorithm that allows units to jointly select and infer the common latent processes without sharing their data. We also discuss an efficient learning approach for a new unit within our proposed federated framework. Simulation and case studies on Li-ion battery degradation and air temperature data demonstrate the advantageous features of our proposed approach.
Real-time Adaptation for Condition Monitoring Signal Prediction using Label-aware Neural Processes
Mar 25, 2024Building a predictive model that rapidly adapts to real-time condition monitoring (CM) signals is critical for engineering systems/units. Unfortunately, many current methods suffer from a trade-off between representation power and agility in online settings. For instance, parametric methods that assume an underlying functional form for CM signals facilitate efficient online prediction updates. However, this simplification leads to vulnerability to model specifications and an inability to capture complex signals. On the other hand, approaches based on over-parameterized or non-parametric models can excel at explaining complex nonlinear signals, but real-time updates for such models pose a challenging task. In this paper, we propose a neural process-based approach that addresses this trade-off. It encodes available observations within a CM signal into a representation space and then reconstructs the signal's history and evolution for prediction. Once trained, the model can encode an arbitrary number of observations without requiring retraining, enabling on-the-spot real-time predictions along with quantified uncertainty and can be readily updated as more online data is gathered. Furthermore, our model is designed to incorporate qualitative information (i.e., labels) from individual units. This integration not only enhances individualized predictions for each unit but also enables joint inference for both signals and their associated labels. Numerical studies on both synthetic and real-world data in reliability engineering highlight the advantageous features of our model in real-time adaptation, enhanced signal prediction with uncertainty quantification, and joint prediction for labels and signals.
The Internet of Federated Things : A Vision for the Future and In-depth Survey of Data-driven Approaches for Federated Learning
Nov 09, 2021
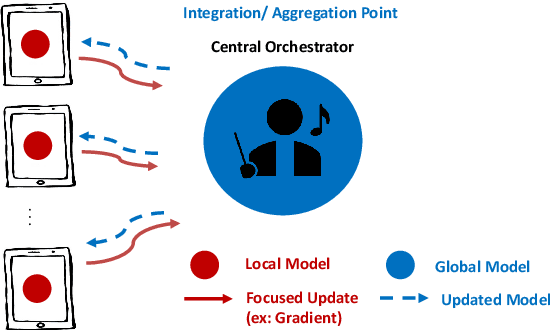
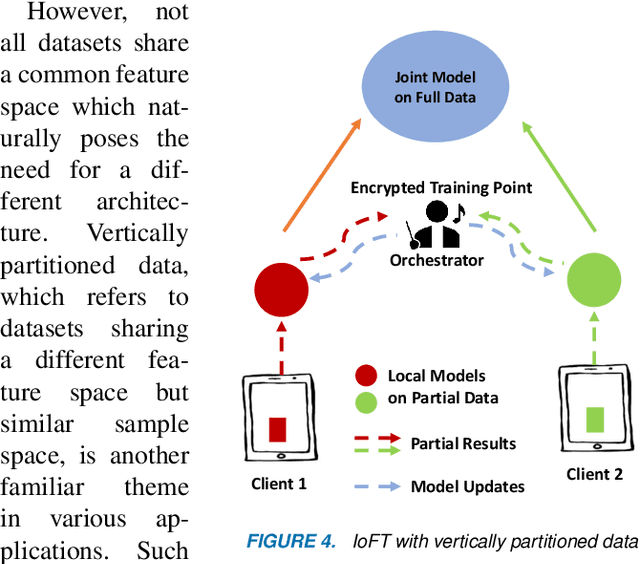
The Internet of Things (IoT) is on the verge of a major paradigm shift. In the IoT system of the future, IoFT, the cloud will be substituted by the crowd where model training is brought to the edge, allowing IoT devices to collaboratively extract knowledge and build smart analytics/models while keeping their personal data stored locally. This paradigm shift was set into motion by the tremendous increase in computational power on IoT devices and the recent advances in decentralized and privacy-preserving model training, coined as federated learning (FL). This article provides a vision for IoFT and a systematic overview of current efforts towards realizing this vision. Specifically, we first introduce the defining characteristics of IoFT and discuss FL data-driven approaches, opportunities, and challenges that allow decentralized inference within three dimensions: (i) a global model that maximizes utility across all IoT devices, (ii) a personalized model that borrows strengths across all devices yet retains its own model, (iii) a meta-learning model that quickly adapts to new devices or learning tasks. We end by describing the vision and challenges of IoFT in reshaping different industries through the lens of domain experts. Those industries include manufacturing, transportation, energy, healthcare, quality & reliability, business, and computing.
Weakly-supervised Multi-output Regression via Correlated Gaussian Processes
Feb 19, 2020

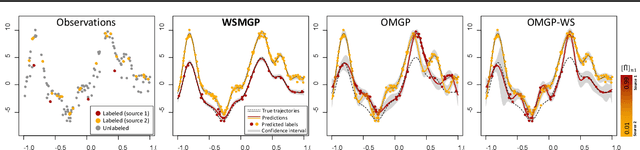

Multi-output regression seeks to infer multiple latent functions using data from multiple groups/sources while accounting for potential between-group similarities. In this paper, we consider multi-output regression under a weakly-supervised setting where a subset of data points from multiple groups are unlabeled. We use dependent Gaussian processes for multiple outputs constructed by convolutions with shared latent processes. We introduce hyperpriors for the multinomial probabilities of the unobserved labels and optimize the hyperparameters which we show improves estimation. We derive two variational bounds: (i) a modified variational bound for fast and stable convergence in model inference, (ii) a scalable variational bound that is amenable to stochastic optimization. We use experiments on synthetic and real-world data to show that the proposed model outperforms state-of-the-art models with more accurate estimation of multiple latent functions and unobserved labels.
Functional Principal Component Analysis for Extrapolating Multi-stream Longitudinal Data
Mar 09, 2019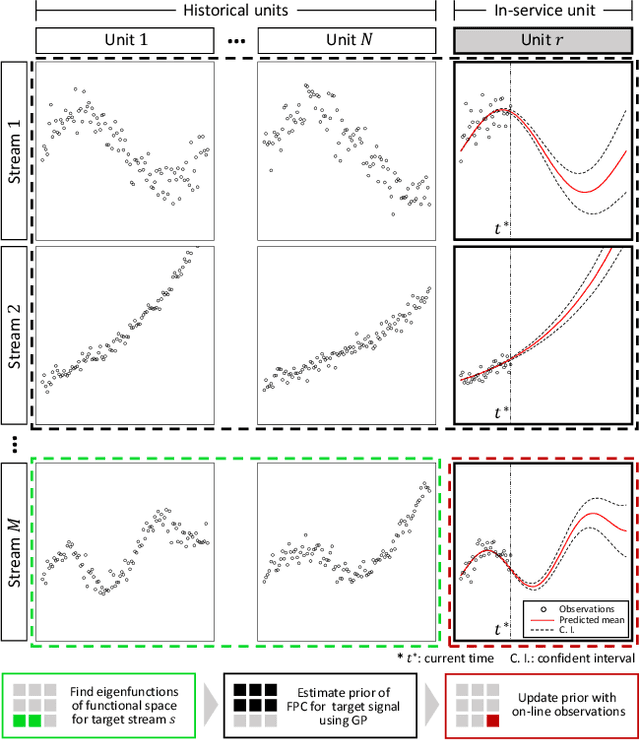
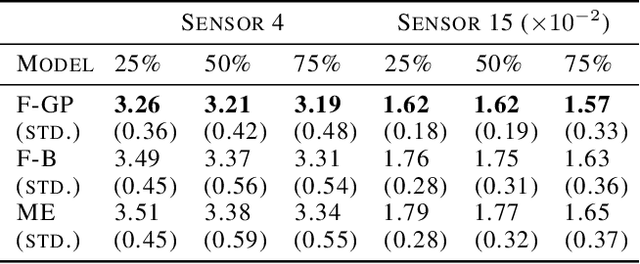
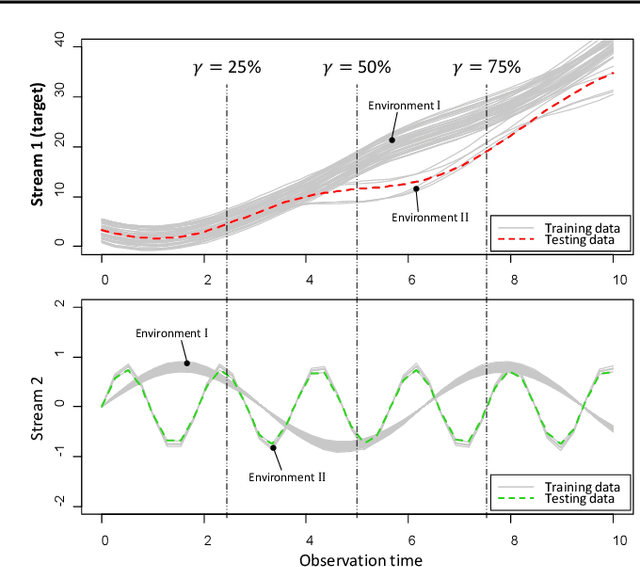
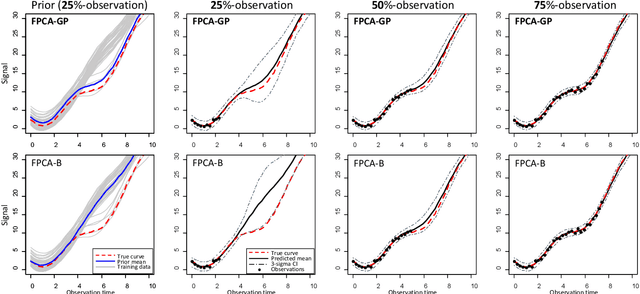
The advance of modern sensor technologies enables collection of multi-stream longitudinal data where multiple signals from different units are collected in real-time. In this article, we present a non-parametric approach to predict the evolution of multi-stream longitudinal data for an in-service unit through borrowing strength from other historical units. Our approach first decomposes each stream into a linear combination of eigenfunctions and their corresponding functional principal component (FPC) scores. A Gaussian process prior for the FPC scores is then established based on a functional semi-metric that measures similarities between streams of historical units and the in-service unit. Finally, an empirical Bayesian updating strategy is derived to update the established prior using real-time stream data obtained from the in-service unit. Experiments on synthetic and real world data show that the proposed framework outperforms state-of-the-art approaches and can effectively account for heterogeneity as well as achieve high predictive accuracy.
A Mathematical Programming Approach for Integrated Multiple Linear Regression Subset Selection and Validation
Dec 12, 2017
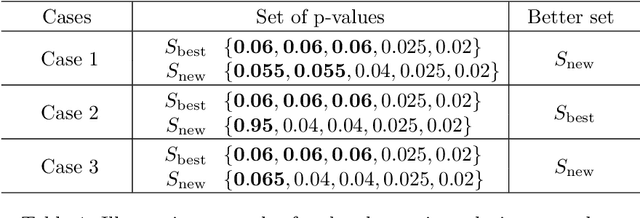
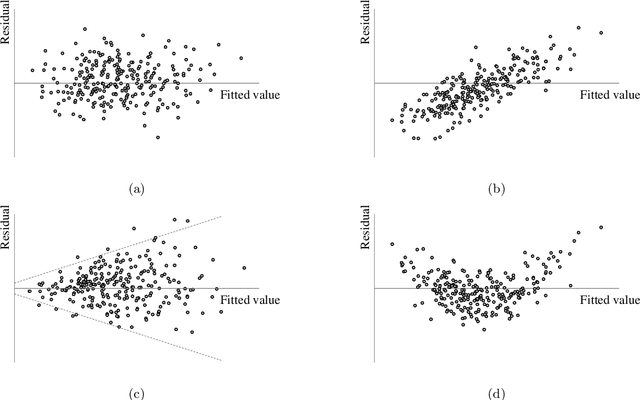
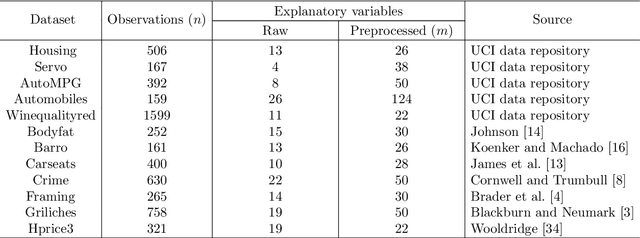
Subset selection for multiple linear regression aims to construct a regression model that minimizes errors by selecting a small number of explanatory variables. Once a model is built, various statistical tests and diagnostics are conducted to validate the model and to determine whether regression assumptions are met. Most traditional approaches require human decisions at this step, for example, the user adding or removing a variable until a satisfactory model is obtained. However, this trial-and-error strategy cannot guarantee that a subset that minimizes the errors while satisfying all regression assumptions will be found. In this paper, we propose a fully automated model building procedure for multiple linear regression subset selection that integrates model building and validation based on mathematical programming. The proposed model minimizes mean squared errors while ensuring that the majority of the important regression assumptions are met. When no subset satisfies all of the considered regression assumptions, our model provides an alternative subset that satisfies most of these assumptions. Computational results show that our model yields better solutions (i.e., satisfying more regression assumptions) compared to benchmark models while maintaining similar explanatory power.