 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSEANet: Ultrasound-Specific Edge-Aware Multi-Branch Network for Lightweight Medical Image Segmentation
Sep 09, 2025
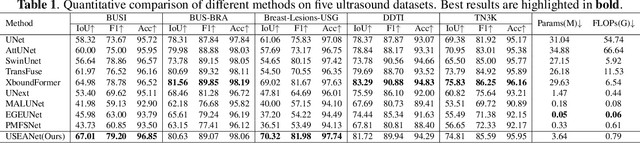


Ultrasound image segmentation faces unique challenges including speckle noise, low contrast, and ambiguous boundaries, while clinical deployment demands computationally efficient models. We propose USEANet, an ultrasound-specific edge-aware multi-branch network that achieves optimal performance-efficiency balance through four key innovations: (1) ultrasound-specific multi-branch processing with specialized modules for noise reduction, edge enhancement, and contrast improvement; (2) edge-aware attention mechanisms that focus on boundary information with minimal computational overhead; (3) hierarchical feature aggregation with adaptive weight learning; and (4) ultrasound-aware decoder enhancement for optimal segmentation refinement. Built on an ultra-lightweight PVT-B0 backbone, USEANet significantly outperforms existing methods across five ultrasound datasets while using only 3.64M parameters and 0.79G FLOPs. Experimental results demonstrate superior segmentation accuracy with 67.01 IoU on BUSI dataset, representing substantial improvements over traditional approaches while maintaining exceptional computational efficiency suitable for real-time clinical applications. Code is available at https://github.com/chouheiwa/USEANet.
Replicable Distribution Testing
Jul 03, 2025We initiate a systematic investigation of distribution testing in the framework of algorithmic replicability. Specifically, given independent samples from a collection of probability distributions, the goal is to characterize the sample complexity of replicably testing natural properties of the underlying distributions. On the algorithmic front, we develop new replicable algorithms for testing closeness and independence of discrete distributions. On the lower bound front, we develop a new methodology for proving sample complexity lower bounds for replicable testing that may be of broader interest. As an application of our technique, we establish near-optimal sample complexity lower bounds for replicable uniformity testing -- answering an open question from prior work -- and closeness testing.
Using Subgraph GNNs for Node Classification:an Overlooked Potential Approach
Mar 09, 2025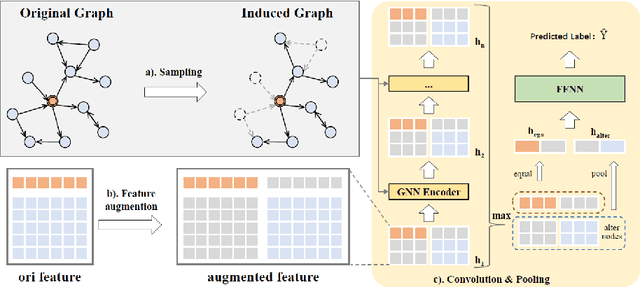
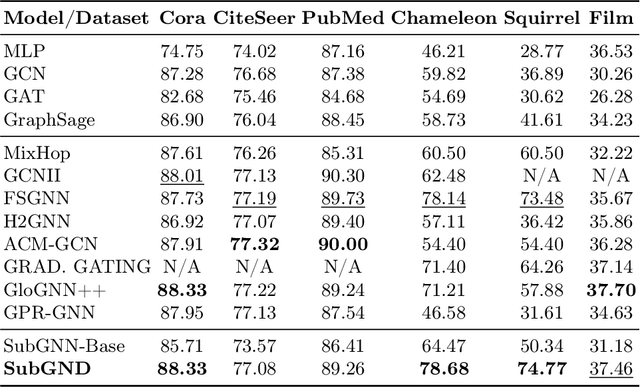
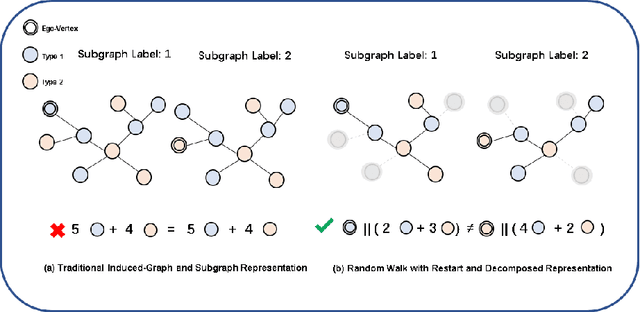
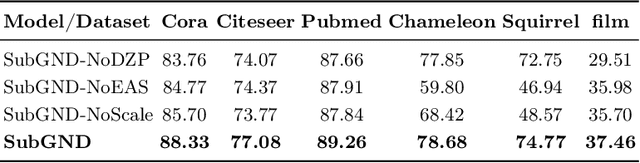
Previous studies have demonstrated the strong performance of Graph Neural Networks (GNNs) in node classification. However, most existing GNNs adopt a node-centric perspective and rely on global message passing, leading to high computational and memory costs that hinder scalability. To mitigate these challenges, subgraph-based methods have been introduced, leveraging local subgraphs as approximations of full computational trees. While this approach improves efficiency, it often suffers from performance degradation due to the loss of global contextual information, limiting its effectiveness compared to global GNNs. To address this trade-off between scalability and classification accuracy, we reformulate the node classification task as a subgraph classification problem and propose SubGND (Subgraph GNN for NoDe). This framework introduces a differentiated zero-padding strategy and an Ego-Alter subgraph representation method to resolve label conflicts while incorporating an Adaptive Feature Scaling Mechanism to dynamically adjust feature contributions based on dataset-specific dependencies. Experimental results on six benchmark datasets demonstrate that SubGND achieves performance comparable to or surpassing global message-passing GNNs, particularly in heterophilic settings, highlighting its effectiveness and scalability as a promising solution for node classification.
Federated Automatic Latent Variable Selection in Multi-output Gaussian Processes
Jul 24, 2024This paper explores a federated learning approach that automatically selects the number of latent processes in multi-output Gaussian processes (MGPs). The MGP has seen great success as a transfer learning tool when data is generated from multiple sources/units/entities. A common approach in MGPs to transfer knowledge across units involves gathering all data from each unit to a central server and extracting common independent latent processes to express each unit as a linear combination of the shared latent patterns. However, this approach poses key challenges in (i) determining the adequate number of latent processes and (ii) relying on centralized learning which leads to potential privacy risks and significant computational burdens on the central server. To address these issues, we propose a hierarchical model that places spike-and-slab priors on the coefficients of each latent process. These priors help automatically select only needed latent processes by shrinking the coefficients of unnecessary ones to zero. To estimate the model while avoiding the drawbacks of centralized learning, we propose a variational inference-based approach, that formulates model inference as an optimization problem compatible with federated settings. We then design a federated learning algorithm that allows units to jointly select and infer the common latent processes without sharing their data. We also discuss an efficient learning approach for a new unit within our proposed federated framework. Simulation and case studies on Li-ion battery degradation and air temperature data demonstrate the advantageous features of our proposed approach.