 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Last Human-Written Paper: Agent-Native Research Artifacts
Apr 27, 2026Scientific publication compresses a branching, iterative research process into a linear narrative, discarding the majority of what was discovered along the way. This compilation imposes two structural costs: a Storytelling Tax, where failed experiments, rejected hypotheses, and the branching exploration process are discarded to fit a linear narrative; and an Engineering Tax, where the gap between reviewer-sufficient prose and agent-sufficient specification leaves critical implementation details unwritten. Tolerable for human readers, these costs become critical when AI agents must understand, reproduce, and extend published work. We introduce the Agent-Native Research Artifact (Ara), a protocol that replaces the narrative paper with a machine-executable research package structured around four layers: scientific logic, executable code with full specifications, an exploration graph that preserves the failures compilation discards, and evidence grounding every claim in raw outputs. Three mechanisms support the ecosystem: a Live Research Manager that captures decisions and dead ends during ordinary development; an Ara Compiler that translates legacy PDFs and repos into Aras; and an Ara-native review system that automates objective checks so human reviewers can focus on significance, novelty, and taste. On PaperBench and RE-Bench, Ara raises question-answering accuracy from 72.4% to 93.7% and reproduction success from 57.4% to 64.4%. On RE-Bench's five open-ended extension tasks, preserved failure traces in Ara accelerate progress, but can also constrain a capable agent from stepping outside the prior-run box depending on the agent's capabilities.
Cornserve: A Distributed Serving System for Any-to-Any Multimodal Models
Mar 12, 2026Any-to-Any models are an emerging class of multimodal models that accept combinations of multimodal data (e.g., text, image, video, audio) as input and generate them as output. Serving these models are challenging; different requests with different input and output modalities traverse different paths through the model computation graph, and each component of the model have different scaling characteristics. We present Cornserve, a distributed serving system for generic Any-to-Any models. Cornserve provides a flexible task abstraction for expressing Any-to-Any model computation graphs, enabling component disaggregation and independent scaling. The distributed runtime dispatches compute to the data plane via an efficient record-and-replay execution model that keeps track of data dependencies, and forwards tensor data between components directly from the producer to the consumer. Built on Kubernetes with approximately 23K new lines of Python, Cornserve supports diverse Any-to-Any models and delivers up to 3.81$\times$ higher throughput and 5.79$\times$ lower tail latency. Cornserve is open-source, and the demo video is available on YouTube.
Where Do the Joules Go? Diagnosing Inference Energy Consumption
Jan 29, 2026Energy is now a critical ML computing resource. While measuring energy consumption and observing trends is a valuable first step, accurately understanding and diagnosing why those differences occur is crucial for optimization. To that end, we begin by presenting a large-scale measurement study of inference time and energy across the generative AI landscape with 46 models, 7 tasks, and 1,858 different configurations on NVIDIA H100 and B200 GPUs. Our empirical findings span order-of-magnitude variations: LLM task type can lead to 25$\times$ energy differences, video generation sometimes consumes more than 100$\times$ the energy of images, and GPU utilization differences can result in 3--5$\times$ energy differences. Based on our observations, we present a framework for reasoning about the underlying mechanisms that govern time and energy consumption. The essence is that time and energy are determined by latent metrics like memory and utilization, which are in turn affected by various factors across the algorithm, software, and hardware layers. Our framework also extends directly to throughput per watt, a critical metric for power-constrained datacenters.
Kareus: Joint Reduction of Dynamic and Static Energy in Large Model Training
Jan 25, 2026The computing demand of AI is growing at an unprecedented rate, but energy supply is not keeping pace. As a result, energy has become an expensive, contended resource that requires explicit management and optimization. Although recent works have made significant progress in large model training optimization, they focus only on a single aspect of energy consumption: dynamic or static energy. We find that fine-grained kernel scheduling and frequency scaling jointly and interdependently impact both dynamic and static energy consumption. Based on this finding, we design Kareus, a training system that pushes the time--energy tradeoff frontier by optimizing both aspects. Kareus decomposes the intractable joint optimization problem into local, partition-based subproblems. It then uses a multi-pass multi-objective optimization algorithm to find execution schedules that push the time--energy tradeoff frontier. Compared to the state of the art, Kareus reduces training energy by up to 28.3% at the same training time, or reduces training time by up to 27.5% at the same energy consumption.
Cornserve: Efficiently Serving Any-to-Any Multimodal Models
Dec 18, 2025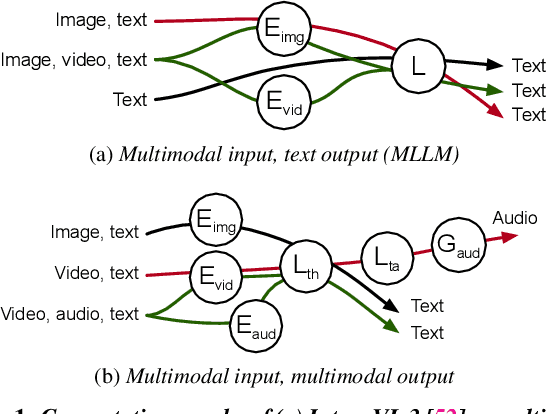
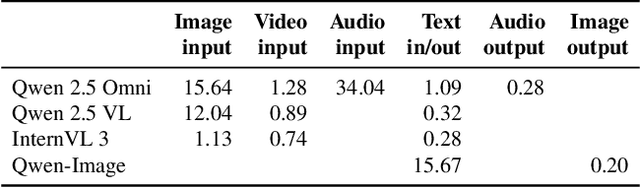
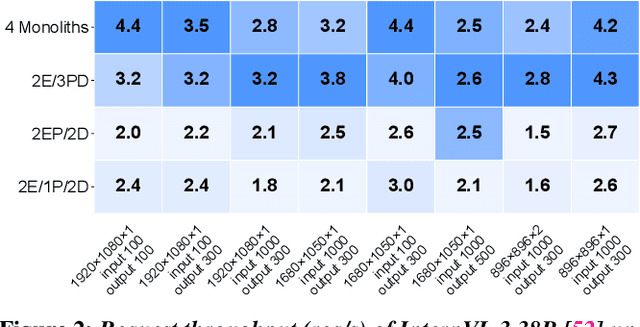
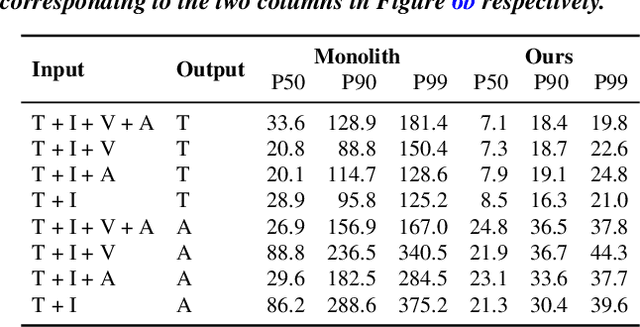
We present Cornserve, an efficient online serving system for an emerging class of multimodal models called Any-to-Any models. Any-to-Any models accept combinations of text and multimodal data (e.g., image, video, audio) as input and also generate combinations of text and multimodal data as output, introducing request type, computation path, and computation scaling heterogeneity in model serving. Cornserve allows model developers to describe the computation graph of generic Any-to-Any models, which consists of heterogeneous components such as multimodal encoders, autoregressive models like Large Language Models (LLMs), and multimodal generators like Diffusion Transformers (DiTs). Given this, Cornserve's planner automatically finds an optimized deployment plan for the model, including whether and how to disaggregate the model into smaller components based on model and workload characteristics. Cornserve's distributed runtime then executes the model per the plan, efficiently handling Any-to-Any model heterogeneity during online serving. Evaluations show that Cornserve can efficiently serve diverse Any-to-Any models and workloads, delivering up to 3.81$\times$ throughput improvement and up to 5.79$\times$ tail latency reduction over existing solutions.
TetriServe: Efficient DiT Serving for Heterogeneous Image Generation
Oct 02, 2025Diffusion Transformer (DiT) models excel at generating highquality images through iterative denoising steps, but serving them under strict Service Level Objectives (SLOs) is challenging due to their high computational cost, particularly at large resolutions. Existing serving systems use fixed degree sequence parallelism, which is inefficient for heterogeneous workloads with mixed resolutions and deadlines, leading to poor GPU utilization and low SLO attainment. In this paper, we propose step-level sequence parallelism to dynamically adjust the parallel degree of individual requests according to their deadlines. We present TetriServe, a DiT serving system that implements this strategy for highly efficient image generation. Specifically, TetriServe introduces a novel round-based scheduling mechanism that improves SLO attainment: (1) discretizing time into fixed rounds to make deadline-aware scheduling tractable, (2) adapting parallelism at the step level and minimize GPU hour consumption, and (3) jointly packing requests to minimize late completions. Extensive evaluation on state-of-the-art DiT models shows that TetriServe achieves up to 32% higher SLO attainment compared to existing solutions without degrading image quality.
EXP-Bench: Can AI Conduct AI Research Experiments?
May 30, 2025



Automating AI research holds immense potential for accelerating scientific progress, yet current AI agents struggle with the complexities of rigorous, end-to-end experimentation. We introduce EXP-Bench, a novel benchmark designed to systematically evaluate AI agents on complete research experiments sourced from influential AI publications. Given a research question and incomplete starter code, EXP-Bench challenges AI agents to formulate hypotheses, design and implement experimental procedures, execute them, and analyze results. To enable the creation of such intricate and authentic tasks with high-fidelity, we design a semi-autonomous pipeline to extract and structure crucial experimental details from these research papers and their associated open-source code. With the pipeline, EXP-Bench curated 461 AI research tasks from 51 top-tier AI research papers. Evaluations of leading LLM-based agents, such as OpenHands and IterativeAgent on EXP-Bench demonstrate partial capabilities: while scores on individual experimental aspects such as design or implementation correctness occasionally reach 20-35%, the success rate for complete, executable experiments was a mere 0.5%. By identifying these bottlenecks and providing realistic step-by-step experiment procedures, EXP-Bench serves as a vital tool for future AI agents to improve their ability to conduct AI research experiments. EXP-Bench is open-sourced at https://github.com/Just-Curieous/Curie/tree/main/benchmark/exp_bench.
The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
May 09, 2025As the adoption of Generative AI in real-world services grow explosively, energy has emerged as a critical bottleneck resource. However, energy remains a metric that is often overlooked, under-explored, or poorly understood in the context of building ML systems. We present the ML.ENERGY Benchmark, a benchmark suite and tool for measuring inference energy consumption under realistic service environments, and the corresponding ML.ENERGY Leaderboard, which have served as a valuable resource for those hoping to understand and optimize the energy consumption of their generative AI services. In this paper, we explain four key design principles for benchmarking ML energy we have acquired over time, and then describe how they are implemented in the ML.ENERGY Benchmark. We then highlight results from the latest iteration of the benchmark, including energy measurements of 40 widely used model architectures across 6 different tasks, case studies of how ML design choices impact energy consumption, and how automated optimization recommendations can lead to significant (sometimes more than 40%) energy savings without changing what is being computed by the model. The ML.ENERGY Benchmark is open-source and can be easily extended to various customized models and application scenarios.
Curie: Toward Rigorous and Automated Scientific Experimentation with AI Agents
Feb 26, 2025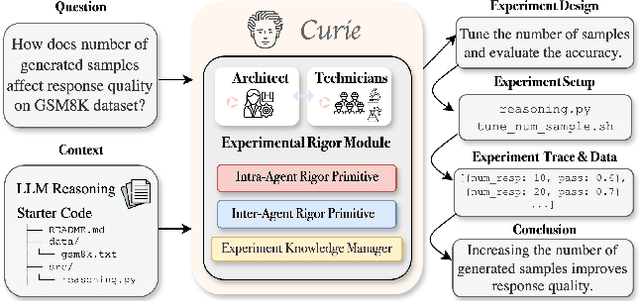
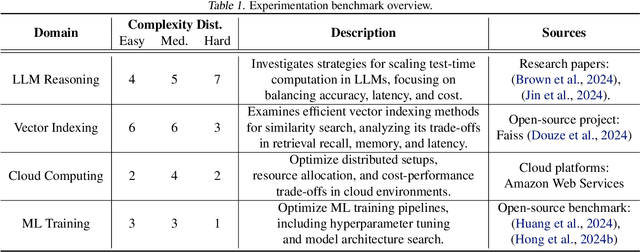
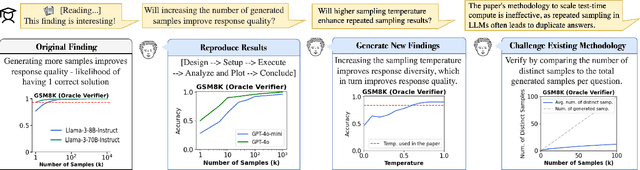
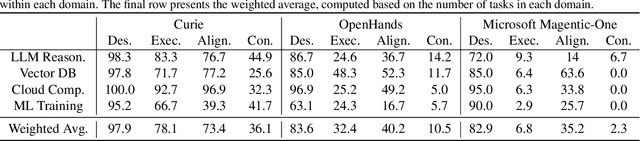
Scientific experimentation, a cornerstone of human progress, demands rigor in reliability, methodical control, and interpretability to yield meaningful results. Despite the growing capabilities of large language models (LLMs) in automating different aspects of the scientific process, automating rigorous experimentation remains a significant challenge. To address this gap, we propose Curie, an AI agent framework designed to embed rigor into the experimentation process through three key components: an intra-agent rigor module to enhance reliability, an inter-agent rigor module to maintain methodical control, and an experiment knowledge module to enhance interpretability. To evaluate Curie, we design a novel experimental benchmark composed of 46 questions across four computer science domains, derived from influential research papers, and widely adopted open-source projects. Compared to the strongest baseline tested, we achieve a 3.4$\times$ improvement in correctly answering experimental questions. Curie is open-sourced at https://github.com/Just-Curieous/Curie.
Andes: Defining and Enhancing Quality-of-Experience in LLM-Based Text Streaming Services
Apr 25, 2024



The advent of large language models (LLMs) has transformed text-based services, enabling capabilities ranging from real-time translation to AI-driven chatbots. However, existing serving systems primarily focus on optimizing server-side aggregate metrics like token generation throughput, ignoring individual user experience with streamed text. As a result, under high and/or bursty load, a significant number of users can receive unfavorable service quality or poor Quality-of-Experience (QoE). In this paper, we first formally define QoE of text streaming services, where text is delivered incrementally and interactively to users, by considering the end-to-end token delivery process throughout the entire interaction with the user. Thereafter, we propose Andes, a QoE-aware serving system that enhances user experience for LLM-enabled text streaming services. At its core, Andes strategically allocates contended GPU resources among multiple requests over time to optimize their QoE. Our evaluations demonstrate that, compared to the state-of-the-art LLM serving systems like vLLM, Andes improves the average QoE by up to 3.2$\times$ under high request rate, or alternatively, it attains up to 1.6$\times$ higher request rate while preserving high QoE.