 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Large Language Models: A Survey
Dec 23, 2023



Large Language Models (LLMs) have demonstrated remarkable capabilities in important tasks such as natural language understanding, language generation, and complex reasoning and have the potential to make a substantial impact on our society. Such capabilities, however, come with the considerable resources they demand, highlighting the strong need to develop effective techniques for addressing their efficiency challenges. In this survey, we provide a systematic and comprehensive review of efficient LLMs research. We organize the literature in a taxonomy consisting of three main categories, covering distinct yet interconnected efficient LLMs topics from model-centric, data-centric, and framework-centric perspective, respectively. We have also created a GitHub repository where we compile the papers featured in this survey at https://github.com/AIoT-MLSys-Lab/EfficientLLMs, and will actively maintain this repository and incorporate new research as it emerges. We hope our survey can serve as a valuable resource to help researchers and practitioners gain a systematic understanding of the research developments in efficient LLMs and inspire them to contribute to this important and exciting field.
Enabling Deep Learning on Edge Devices
Oct 06, 2022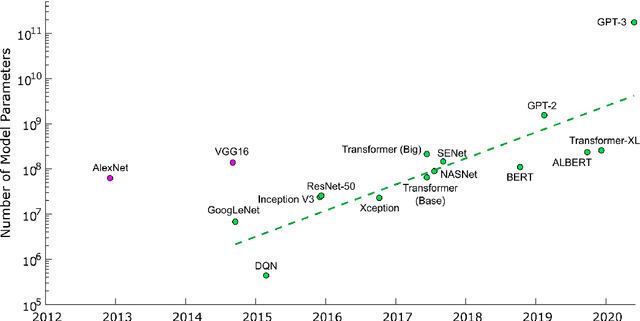

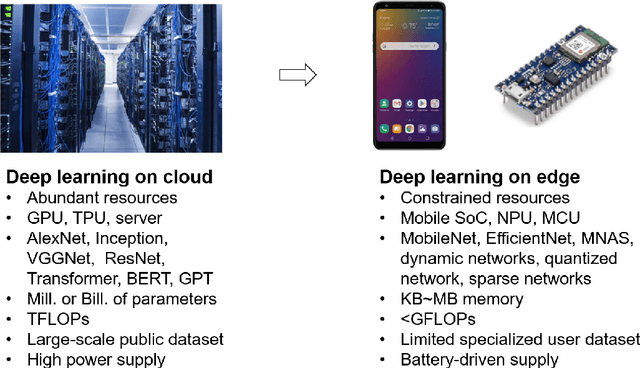

Deep neural networks (DNNs) have succeeded in many different perception tasks, e.g., computer vision, natural language processing, reinforcement learning, etc. The high-performed DNNs heavily rely on intensive resource consumption. For example, training a DNN requires high dynamic memory, a large-scale dataset, and a large number of computations (a long training time); even inference with a DNN also demands a large amount of static storage, computations (a long inference time), and energy. Therefore, state-of-the-art DNNs are often deployed on a cloud server with a large number of super-computers, a high-bandwidth communication bus, a shared storage infrastructure, and a high power supplement. Recently, some new emerging intelligent applications, e.g., AR/VR, mobile assistants, Internet of Things, require us to deploy DNNs on resource-constrained edge devices. Compare to a cloud server, edge devices often have a rather small amount of resources. To deploy DNNs on edge devices, we need to reduce the size of DNNs, i.e., we target a better trade-off between resource consumption and model accuracy. In this dissertation, we studied four edge intelligence scenarios, i.e., Inference on Edge Devices, Adaptation on Edge Devices, Learning on Edge Devices, and Edge-Server Systems, and developed different methodologies to enable deep learning in each scenario. Since current DNNs are often over-parameterized, our goal is to find and reduce the redundancy of the DNNs in each scenario.
DRESS: Dynamic REal-time Sparse Subnets
Jul 01, 2022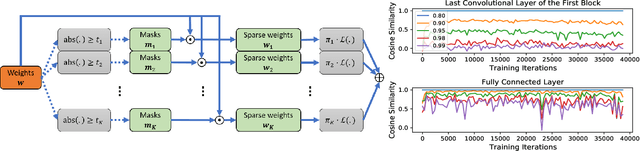
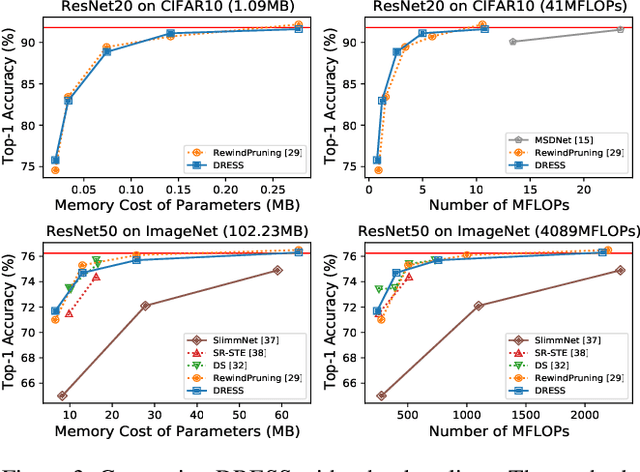
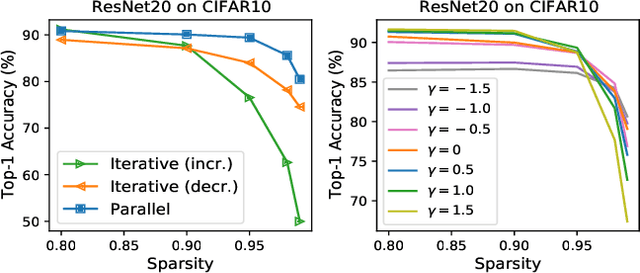
The limited and dynamically varied resources on edge devices motivate us to deploy an optimized deep neural network that can adapt its sub-networks to fit in different resource constraints. However, existing works often build sub-networks through searching different network architectures in a hand-crafted sampling space, which not only can result in a subpar performance but also may cause on-device re-configuration overhead. In this paper, we propose a novel training algorithm, Dynamic REal-time Sparse Subnets (DRESS). DRESS samples multiple sub-networks from the same backbone network through row-based unstructured sparsity, and jointly trains these sub-networks in parallel with weighted loss. DRESS also exploits strategies including parameter reusing and row-based fine-grained sampling for efficient storage consumption and efficient on-device adaptation. Extensive experiments on public vision datasets show that DRESS yields significantly higher accuracy than state-of-the-art sub-networks.
p-Meta: Towards On-device Deep Model Adaptation
Jun 25, 2022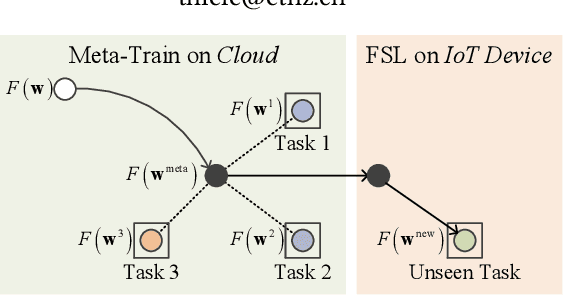

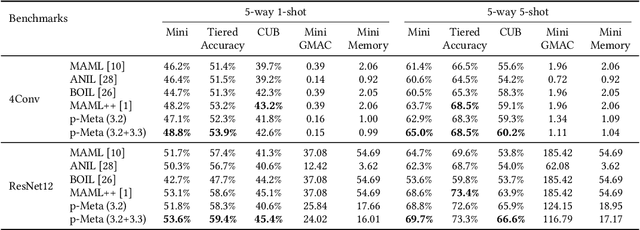
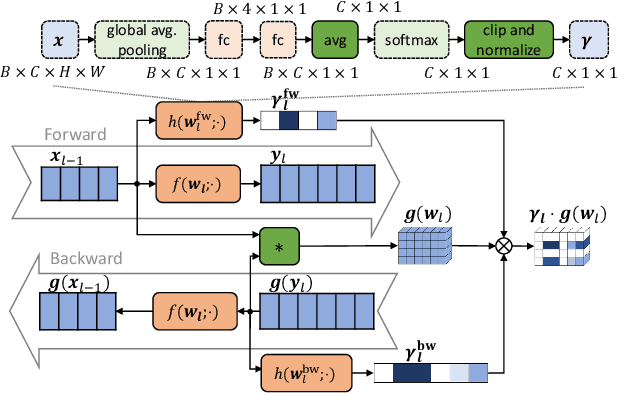
Data collected by IoT devices are often private and have a large diversity across users. Therefore, learning requires pre-training a model with available representative data samples, deploying the pre-trained model on IoT devices, and adapting the deployed model on the device with local data. Such an on-device adaption for deep learning empowered applications demands data and memory efficiency. However, existing gradient-based meta learning schemes fail to support memory-efficient adaptation. To this end, we propose p-Meta, a new meta learning method that enforces structure-wise partial parameter updates while ensuring fast generalization to unseen tasks. Evaluations on few-shot image classification and reinforcement learning tasks show that p-Meta not only improves the accuracy but also substantially reduces the peak dynamic memory by a factor of 2.5 on average compared to state-of-the-art few-shot adaptation methods.
SplitNets: Designing Neural Architectures for Efficient Distributed Computing on Head-Mounted Systems
Apr 10, 2022
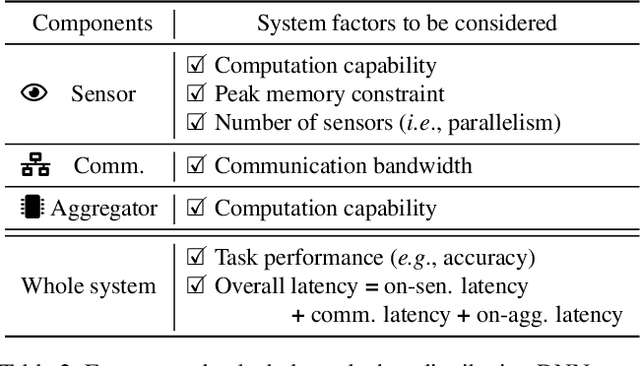
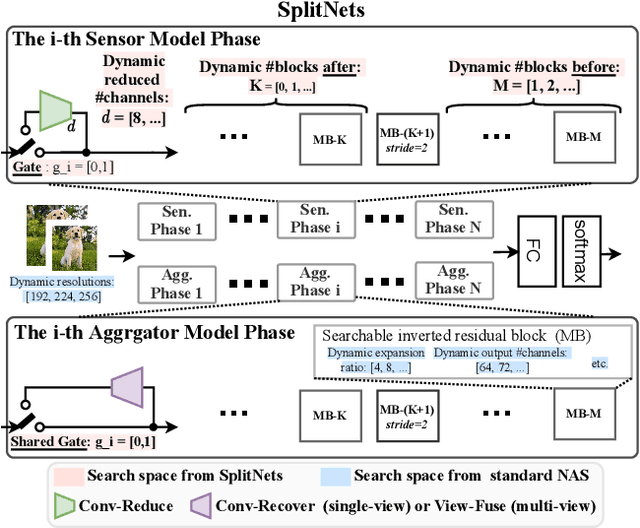

We design deep neural networks (DNNs) and corresponding networks' splittings to distribute DNNs' workload to camera sensors and a centralized aggregator on head mounted devices to meet system performance targets in inference accuracy and latency under the given hardware resource constraints. To achieve an optimal balance among computation, communication, and performance, a split-aware neural architecture search framework, SplitNets, is introduced to conduct model designing, splitting, and communication reduction simultaneously. We further extend the framework to multi-view systems for learning to fuse inputs from multiple camera sensors with optimal performance and systemic efficiency. We validate SplitNets for single-view system on ImageNet as well as multi-view system on 3D classification, and show that the SplitNets framework achieves state-of-the-art (SOTA) performance and system latency compared with existing approaches.
Measuring what Really Matters: Optimizing Neural Networks for TinyML
Apr 21, 2021
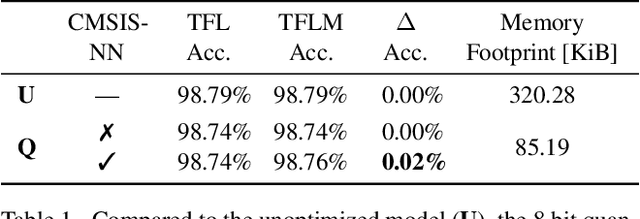
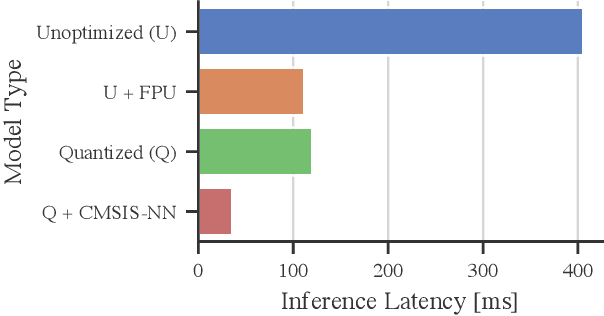
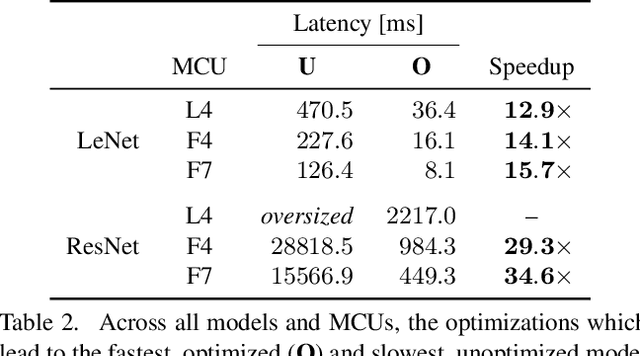
With the surge of inexpensive computational and memory resources, neural networks (NNs) have experienced an unprecedented growth in architectural and computational complexity. Introducing NNs to resource-constrained devices enables cost-efficient deployments, widespread availability, and the preservation of sensitive data. This work addresses the challenges of bringing Machine Learning to MCUs, where we focus on the ubiquitous ARM Cortex-M architecture. The detailed effects and trade-offs that optimization methods, software frameworks, and MCU hardware architecture have on key performance metrics such as inference latency and energy consumption have not been previously studied in depth for state-of-the-art frameworks such as TensorFlow Lite Micro. We find that empirical investigations which measure the perceptible metrics - performance as experienced by the user - are indispensable, as the impact of specialized instructions and layer types can be subtle. To this end, we propose an implementation-aware design as a cost-effective method for verification and benchmarking. Employing our developed toolchain, we demonstrate how existing NN deployments on resource-constrained devices can be improved by systematically optimizing NNs to their targeted application scenario.
RSKDD-Net: Random Sample-based Keypoint Detector and Descriptor
Oct 23, 2020


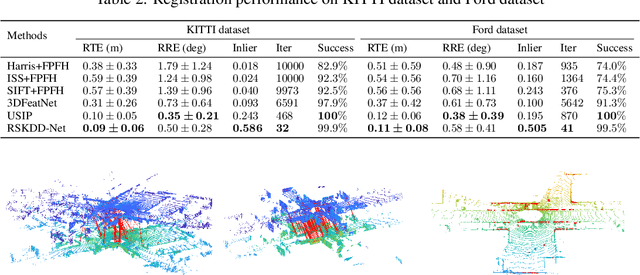
Keypoint detector and descriptor are two main components of point cloud registration. Previous learning-based keypoint detectors rely on saliency estimation for each point or farthest point sample (FPS) for candidate points selection, which are inefficient and not applicable in large scale scenes. This paper proposes Random Sample-based Keypoint Detector and Descriptor Network (RSKDD-Net) for large scale point cloud registration. The key idea is using random sampling to efficiently select candidate points and using a learning-based method to jointly generate keypoints and descriptors. To tackle the information loss of random sampling, we exploit a novel random dilation cluster strategy to enlarge the receptive field of each sampled point and an attention mechanism to aggregate the positions and features of neighbor points. Furthermore, we propose a matching loss to train the descriptor in a weakly supervised manner. Extensive experiments on two large scale outdoor LiDAR datasets show that the proposed RSKDD-Net achieves state-of-the-art performance with more than 15 times faster than existing methods. Our code is available at https://github.com/ispc-lab/RSKDD-Net.
Deep Partial Updating
Jul 06, 2020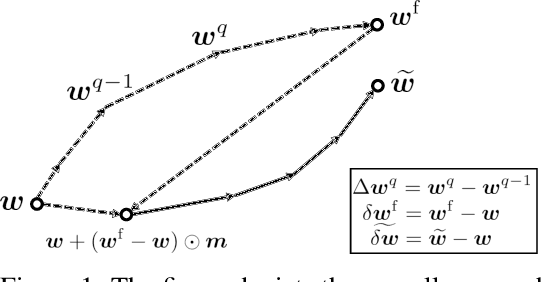
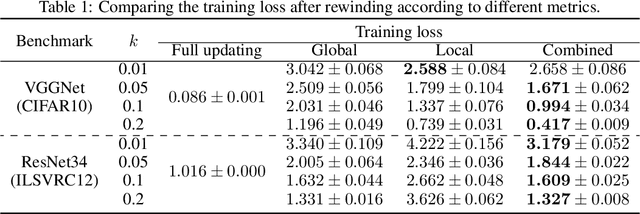
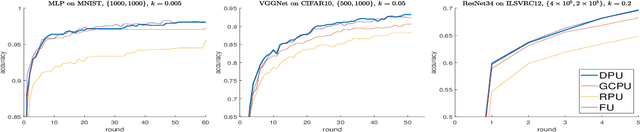
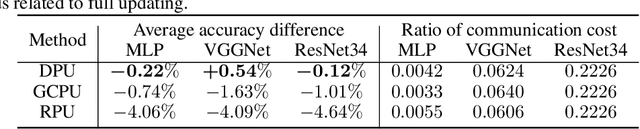
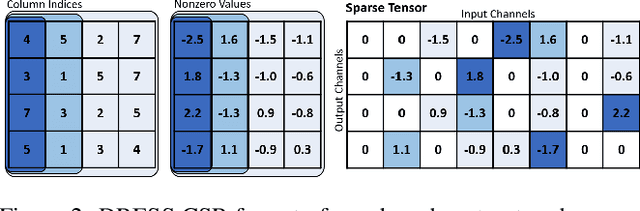
Emerging edge intelligence applications require the server to continuously retrain and update deep neural networks deployed on remote edge nodes in order to leverage newly collected data samples. Unfortunately, it may be impossible in practice to continuously send fully updated weights to these edge nodes due to the highly constrained communication resource. In this paper, we propose the weight-wise deep partial updating paradigm, which smartly selects only a subset of weights to update at each server-to-edge communication round, while achieving a similar performance compared to full updating. Our method is established through analytically upper-bounding the loss difference between partial updating and full updating, and only updates the weights which make the largest contributions to the upper bound. Extensive experimental results demonstrate the efficacy of our partial updating methodology which achieves a high inference accuracy while updating a rather small number of weights.
Event-based Robotic Grasping Detection with Neuromorphic Vision Sensor and Event-Stream Dataset
May 01, 2020

Robotic grasping plays an important role in the field of robotics. The current state-of-the-art robotic grasping detection systems are usually built on the conventional vision, such as RGB-D camera. Compared to traditional frame-based computer vision, neuromorphic vision is a small and young community of research. Currently, there are limited event-based datasets due to the troublesome annotation of the asynchronous event stream. Annotating large scale vision dataset often takes lots of computation resources, especially the troublesome data for video-level annotation. In this work, we consider the problem of detecting robotic grasps in a moving camera view of a scene containing objects. To obtain more agile robotic perception, a neuromorphic vision sensor (DAVIS) attaching to the robot gripper is introduced to explore the potential usage in grasping detection. We construct a robotic grasping dataset named Event-Stream Dataset with 91 objects. A spatio-temporal mixed particle filter (SMP Filter) is proposed to track the led-based grasp rectangles which enables video-level annotation of a single grasp rectangle per object. As leds blink at high frequency, the Event-Stream dataset is annotated in a high frequency of 1 kHz. Based on the Event-Stream dataset, we develop a deep neural network for grasping detection which consider the angle learning problem as classification instead of regression. The method performs high detection accuracy on our Event-Stream dataset with 93% precision at object-wise level. This work provides a large-scale and well-annotated dataset, and promotes the neuromorphic vision applications in agile robot.
Adaptive Loss-aware Quantization for Multi-bit Networks
Dec 18, 2019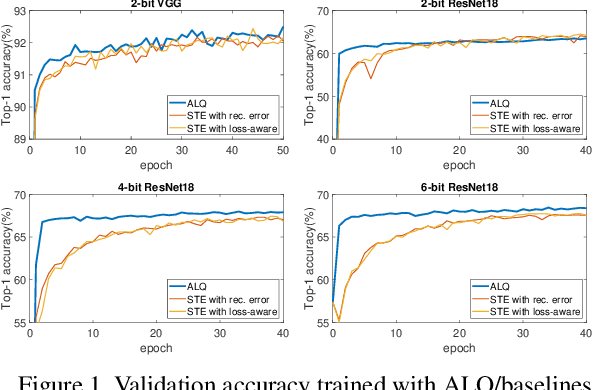
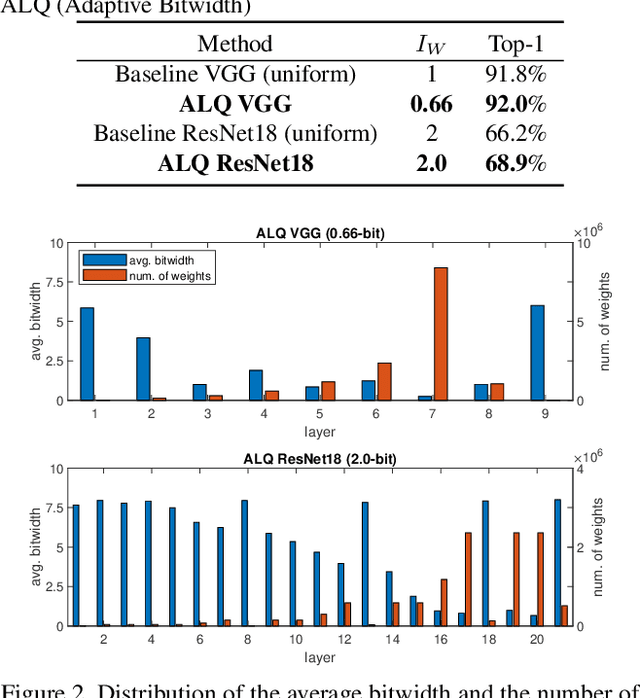

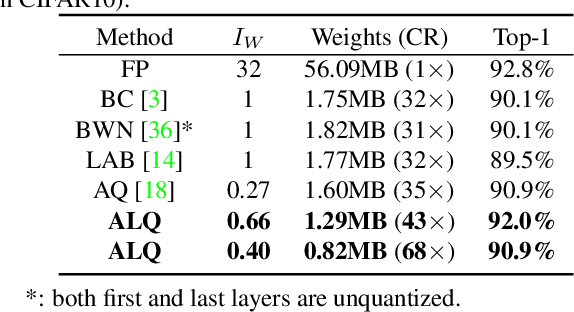
We investigate the compression of deep neural networks by quantizing their weights and activations into multiple binary bases, known as multi-bit networks (MBNs), which accelerates the inference and reduces the storage for deployment on low-resource mobile and embedded platforms. We propose Adaptive Loss-aware Quantization (ALQ), a new MBN quantization pipeline that is able to achieve an average bitwidth below one bit without notable loss in inference accuracy. Unlike previous MBN quantization solutions that train a quantizer by minimizing the error to reconstruct full precision weights, ALQ directly minimizes the quantization-induced error on the loss function involving neither gradient approximation nor full precision calculations. ALQ also exploits strategies including adaptive bitwidth, smooth bitwidth reduction, and iterative trained quantization to allow a smaller network size without loss in accuracy. Experiment results on popular image datasets show that ALQ outperforms state-of-the-art compressed networks in terms of both storage and accuracy.