 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedMosaic: Federated Retrieval-Augmented Generation via Parametric Adapters
Feb 05, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by grounding generation in external knowledge to improve factuality and reduce hallucinations. Yet most deployments assume a centralized corpus, which is infeasible in privacy aware domains where knowledge remains siloed. This motivates federated RAG (FedRAG), where a central LLM server collaborates with distributed silos without sharing raw documents. In context RAG violates this requirement by transmitting verbatim documents, whereas parametric RAG encodes documents into lightweight adapters that merge with a frozen LLM at inference, avoiding raw-text exchange. We adopt the parametric approach but face two unique challenges induced by FedRAG: high storage and communication from per-document adapters, and destructive aggregation caused by indiscriminately merging multiple adapters. We present FedMosaic, the first federated RAG framework built on parametric adapters. FedMosaic clusters semantically related documents into multi-document adapters with document-specific masks to reduce overhead while preserving specificity, and performs selective adapter aggregation to combine only relevance-aligned, nonconflicting adapters. Experiments show that FedMosaic achieves an average 10.9% higher accuracy than state-of-the-art methods in four categories, while lowering storage costs by 78.8% to 86.3% and communication costs by 91.4%, and never sharing raw documents.
CAFEDistill: Learning Personalized and Dynamic Models through Federated Early-Exit Network Distillation
Jan 15, 2026Personalized Federated Learning (PFL) enables collaboratively model training on decentralized, heterogeneous data while tailoring them to each client's unique distribution. However, existing PFL methods produce static models with a fixed tradeoff between accuracy and efficiency, limiting their applicability in environments where inference requirements vary with contexts and resource availability. Early-exit networks (EENs) offer adaptive inference by attaching intermediate classifiers. Yet integrating them into PFL is challenging due to client-wise heterogeneity and depth-wise interference arising from conflicting exit objectives. Prior studies fail to resolve both conflicts simultaneously, leading to suboptimal performance. In this paper, we propose CAFEDistill, a Conflict-Aware Federated Exit Distillation framework that jointly addresses these conflicts and extends PFL to early-exit networks. Through a progressive, depth-prioritized student coordination mechanism, CAFEDistill mitigates interference among shallow and deep exits while allowing effective personalized knowledge transfer across clients. Furthermore, it reduces communication overhead via a client-decoupled formulation. Extensive evaluations show that CAFEDistill outperforms the state-of-the-arts, achieving higher accuracy and reducing inference costs by 30.79%-46.86%.
Accurate and Efficient Multivariate Time Series Forecasting via Offline Clustering
May 09, 2025Accurate and efficient multivariate time series (MTS) forecasting is essential for applications such as traffic management and weather prediction, which depend on capturing long-range temporal dependencies and interactions between entities. Existing methods, particularly those based on Transformer architectures, compute pairwise dependencies across all time steps, leading to a computational complexity that scales quadratically with the length of the input. To overcome these challenges, we introduce the Forecaster with Offline Clustering Using Segments (FOCUS), a novel approach to MTS forecasting that simplifies long-range dependency modeling through the use of prototypes extracted via offline clustering. These prototypes encapsulate high-level events in the real-world system underlying the data, summarizing the key characteristics of similar time segments. In the online phase, FOCUS dynamically adapts these patterns to the current input and captures dependencies between the input segment and high-level events, enabling both accurate and efficient forecasting. By identifying prototypes during the offline clustering phase, FOCUS reduces the computational complexity of modeling long-range dependencies in the online phase to linear scaling. Extensive experiments across diverse benchmarks demonstrate that FOCUS achieves state-of-the-art accuracy while significantly reducing computational costs.
Efficient Data Valuation Approximation in Federated Learning: A Sampling-based Approach
Apr 23, 2025Federated learning paradigm to utilize datasets across multiple data providers. In FL, cross-silo data providers often hesitate to share their high-quality dataset unless their data value can be fairly assessed. Shapley value (SV) has been advocated as the standard metric for data valuation in FL due to its desirable properties. However, the computational overhead of SV is prohibitive in practice, as it inherently requires training and evaluating an FL model across an exponential number of dataset combinations. Furthermore, existing solutions fail to achieve high accuracy and efficiency, making practical use of SV still out of reach, because they ignore choosing suitable computation scheme for approximation framework and overlook the property of utility function in FL. We first propose a unified stratified-sampling framework for two widely-used schemes. Then, we analyze and choose the more promising scheme under the FL linear regression assumption. After that, we identify a phenomenon termed key combinations, where only limited dataset combinations have a high-impact on final data value. Building on these insights, we propose a practical approximation algorithm, IPSS, which strategically selects high-impact dataset combinations rather than evaluating all possible combinations, thus substantially reducing time cost with minor approximation error. Furthermore, we conduct extensive evaluations on the FL benchmark datasets to demonstrate that our proposed algorithm outperforms a series of representative baselines in terms of efficiency and effectiveness.
FoCTTA: Low-Memory Continual Test-Time Adaptation with Focus
Feb 28, 2025Continual adaptation to domain shifts at test time (CTTA) is crucial for enhancing the intelligence of deep learning enabled IoT applications. However, prevailing TTA methods, which typically update all batch normalization (BN) layers, exhibit two memory inefficiencies. First, the reliance on BN layers for adaptation necessitates large batch sizes, leading to high memory usage. Second, updating all BN layers requires storing the activations of all BN layers for backpropagation, exacerbating the memory demand. Both factors lead to substantial memory costs, making existing solutions impractical for IoT devices. In this paper, we present FoCTTA, a low-memory CTTA strategy. The key is to automatically identify and adapt a few drift-sensitive representation layers, rather than blindly update all BN layers. The shift from BN to representation layers eliminates the need for large batch sizes. Also, by updating adaptation-critical layers only, FoCTTA avoids storing excessive activations. This focused adaptation approach ensures that FoCTTA is not only memory-efficient but also maintains effective adaptation. Evaluations show that FoCTTA improves the adaptation accuracy over the state-of-the-arts by 4.5%, 4.9%, and 14.8% on CIFAR10-C, CIFAR100-C, and ImageNet-C under the same memory constraints. Across various batch sizes, FoCTTA reduces the memory usage by 3-fold on average, while improving the accuracy by 8.1%, 3.6%, and 0.2%, respectively, on the three datasets.
AdaShadow: Responsive Test-time Model Adaptation in Non-stationary Mobile Environments
Oct 10, 2024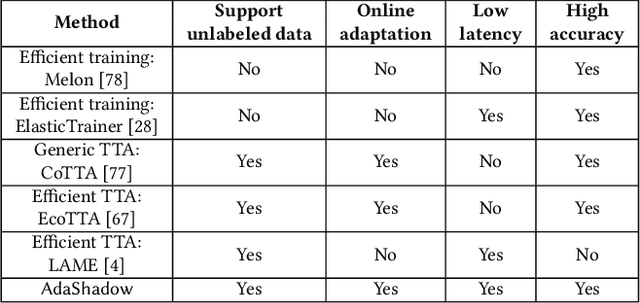
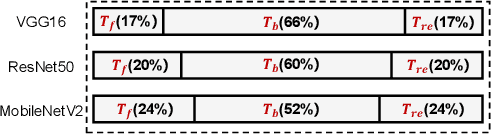
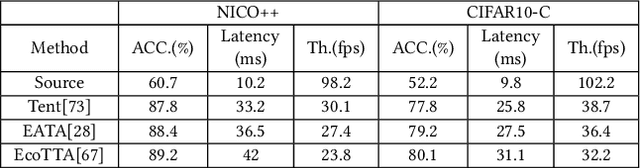
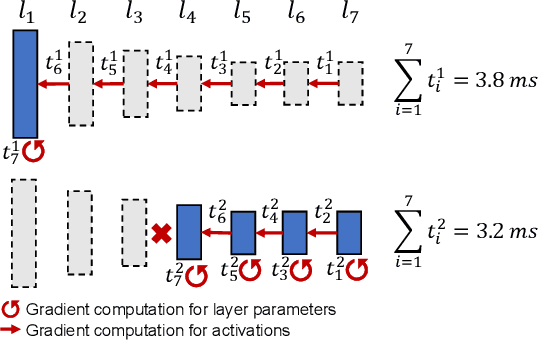
On-device adapting to continual, unpredictable domain shifts is essential for mobile applications like autonomous driving and augmented reality to deliver seamless user experiences in evolving environments. Test-time adaptation (TTA) emerges as a promising solution by tuning model parameters with unlabeled live data immediately before prediction. However, TTA's unique forward-backward-reforward pipeline notably increases the latency over standard inference, undermining the responsiveness in time-sensitive mobile applications. This paper presents AdaShadow, a responsive test-time adaptation framework for non-stationary mobile data distribution and resource dynamics via selective updates of adaptation-critical layers. Although the tactic is recognized in generic on-device training, TTA's unsupervised and online context presents unique challenges in estimating layer importance and latency, as well as scheduling the optimal layer update plan. AdaShadow addresses these challenges with a backpropagation-free assessor to rapidly identify critical layers, a unit-based runtime predictor to account for resource dynamics in latency estimation, and an online scheduler for prompt layer update planning. Also, AdaShadow incorporates a memory I/O-aware computation reuse scheme to further reduce latency in the reforward pass. Results show that AdaShadow achieves the best accuracy-latency balance under continual shifts. At low memory and energy costs, Adashadow provides a 2x to 3.5x speedup (ms-level) over state-of-the-art TTA methods with comparable accuracy and a 14.8% to 25.4% accuracy boost over efficient supervised methods with similar latency.
* This paper is accepted by SenSys 2024. Copyright may be transferred without notice
Deep Learning Inference on Heterogeneous Mobile Processors: Potentials and Pitfalls
May 03, 2024



There is a growing demand to deploy computation-intensive deep learning (DL) models on resource-constrained mobile devices for real-time intelligent applications. Equipped with a variety of processing units such as CPUs, GPUs, and NPUs, the mobile devices hold potential to accelerate DL inference via parallel execution across heterogeneous processors. Various efficient parallel methods have been explored to optimize computation distribution, achieve load balance, and minimize communication cost across processors. Yet their practical effectiveness in the dynamic and diverse real-world mobile environment is less explored. This paper presents a holistic empirical study to assess the capabilities and challenges associated with parallel DL inference on heterogeneous mobile processors. Through carefully designed experiments covering various DL models, mobile software/hardware environments, workload patterns, and resource availability, we identify limitations of existing techniques and highlight opportunities for cross-level optimization.
SwapNet: Efficient Swapping for DNN Inference on Edge AI Devices Beyond the Memory Budget
Jan 30, 2024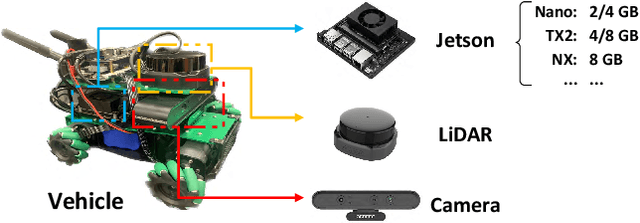
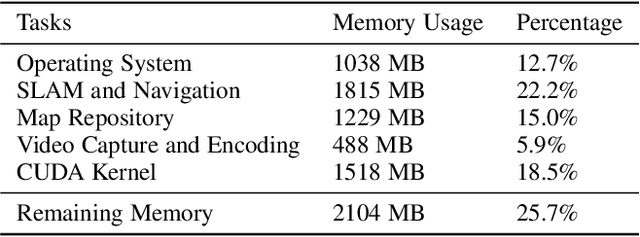
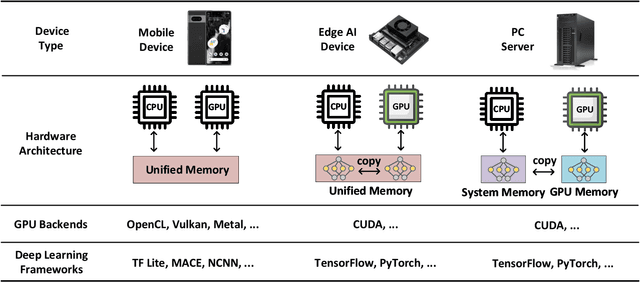
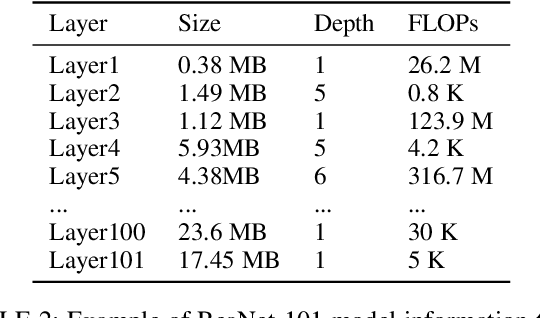
Executing deep neural networks (DNNs) on edge artificial intelligence (AI) devices enables various autonomous mobile computing applications. However, the memory budget of edge AI devices restricts the number and complexity of DNNs allowed in such applications. Existing solutions, such as model compression or cloud offloading, reduce the memory footprint of DNN inference at the cost of decreased model accuracy or autonomy. To avoid these drawbacks, we divide DNN into blocks and swap them in and out in order, such that large DNNs can execute within a small memory budget. Nevertheless, naive swapping on edge AI devices induces significant delays due to the redundant memory operations in the DNN development ecosystem for edge AI devices. To this end, we develop SwapNet, an efficient DNN block swapping middleware for edge AI devices. We systematically eliminate the unnecessary memory operations during block swapping while retaining compatible with the deep learning frameworks, GPU backends, and hardware architectures of edge AI devices. We further showcase the utility of SwapNet via a multi-DNN scheduling scheme. Evaluations on eleven DNN inference tasks in three applications demonstrate that SwapNet achieves almost the same latency as the case with sufficient memory even when DNNs demand 2.32x to 5.81x memory beyond the available budget. The design of SwapNet also provides novel and feasible insights for deploying large language models (LLMs) on edge AI devices in the future.
Enabling Resource-efficient AIoT System with Cross-level Optimization: A survey
Sep 27, 2023The emerging field of artificial intelligence of things (AIoT, AI+IoT) is driven by the widespread use of intelligent infrastructures and the impressive success of deep learning (DL). With the deployment of DL on various intelligent infrastructures featuring rich sensors and weak DL computing capabilities, a diverse range of AIoT applications has become possible. However, DL models are notoriously resource-intensive. Existing research strives to realize near-/realtime inference of AIoT live data and low-cost training using AIoT datasets on resource-scare infrastructures. Accordingly, the accuracy and responsiveness of DL models are bounded by resource availability. To this end, the algorithm-system co-design that jointly optimizes the resource-friendly DL models and model-adaptive system scheduling improves the runtime resource availability and thus pushes the performance boundary set by the standalone level. Unlike previous surveys on resource-friendly DL models or hand-crafted DL compilers/frameworks with partially fine-tuned components, this survey aims to provide a broader optimization space for more free resource-performance tradeoffs. The cross-level optimization landscape involves various granularity, including the DL model, computation graph, operator, memory schedule, and hardware instructor in both on-device and distributed paradigms. Furthermore, due to the dynamic nature of AIoT context, which includes heterogeneous hardware, agnostic sensing data, varying user-specified performance demands, and resource constraints, this survey explores the context-aware inter-/intra-device controllers for automatic cross-level adaptation. Additionally, we identify some potential directions for resource-efficient AIoT systems. By consolidating problems and techniques scattered over diverse levels, we aim to help readers understand their connections and stimulate further discussions.
Localised Adaptive Spatial-Temporal Graph Neural Network
Jun 15, 2023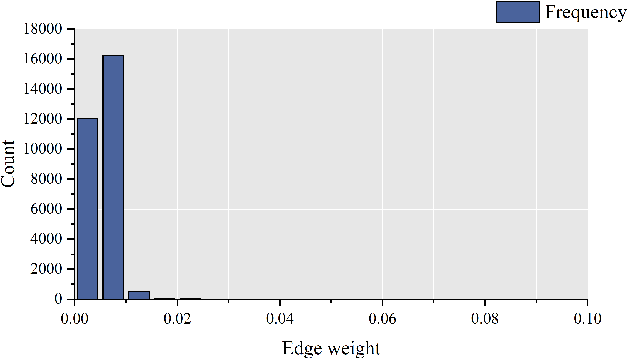
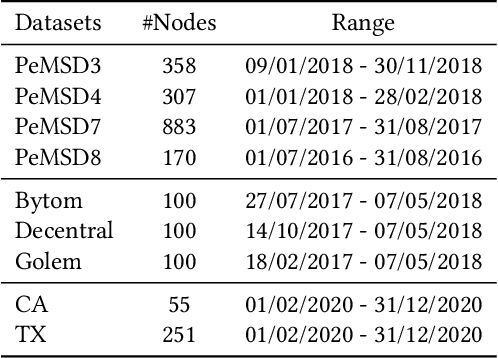
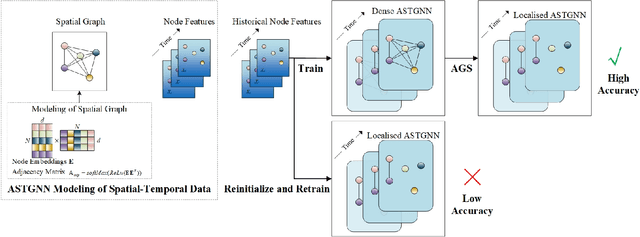

Spatial-temporal graph models are prevailing for abstracting and modelling spatial and temporal dependencies. In this work, we ask the following question: whether and to what extent can we localise spatial-temporal graph models? We limit our scope to adaptive spatial-temporal graph neural networks (ASTGNNs), the state-of-the-art model architecture. Our approach to localisation involves sparsifying the spatial graph adjacency matrices. To this end, we propose Adaptive Graph Sparsification (AGS), a graph sparsification algorithm which successfully enables the localisation of ASTGNNs to an extreme extent (fully localisation). We apply AGS to two distinct ASTGNN architectures and nine spatial-temporal datasets. Intriguingly, we observe that spatial graphs in ASTGNNs can be sparsified by over 99.5\% without any decline in test accuracy. Furthermore, even when ASTGNNs are fully localised, becoming graph-less and purely temporal, we record no drop in accuracy for the majority of tested datasets, with only minor accuracy deterioration observed in the remaining datasets. However, when the partially or fully localised ASTGNNs are reinitialised and retrained on the same data, there is a considerable and consistent drop in accuracy. Based on these observations, we reckon that \textit{(i)} in the tested data, the information provided by the spatial dependencies is primarily included in the information provided by the temporal dependencies and, thus, can be essentially ignored for inference; and \textit{(ii)} although the spatial dependencies provide redundant information, it is vital for the effective training of ASTGNNs and thus cannot be ignored during training. Furthermore, the localisation of ASTGNNs holds the potential to reduce the heavy computation overhead required on large-scale spatial-temporal data and further enable the distributed deployment of ASTGNNs.