 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModule-Aware Parameter-Efficient Machine Unlearning on Transformers
Aug 24, 2025Transformer has become fundamental to a vast series of pre-trained large models that have achieved remarkable success across diverse applications. Machine unlearning, which focuses on efficiently removing specific data influences to comply with privacy regulations, shows promise in restricting updates to influence-critical parameters. However, existing parameter-efficient unlearning methods are largely devised in a module-oblivious manner, which tends to inaccurately identify these parameters and leads to inferior unlearning performance for Transformers. In this paper, we propose {\tt MAPE-Unlearn}, a module-aware parameter-efficient machine unlearning approach that uses a learnable pair of masks to pinpoint influence-critical parameters in the heads and filters of Transformers. The learning objective of these masks is derived by desiderata of unlearning and optimized through an efficient algorithm featured by a greedy search with a warm start. Extensive experiments on various Transformer models and datasets demonstrate the effectiveness and robustness of {\tt MAPE-Unlearn} for unlearning.
Tianyi: A Traditional Chinese Medicine all-rounder language model and its Real-World Clinical Practice
May 19, 2025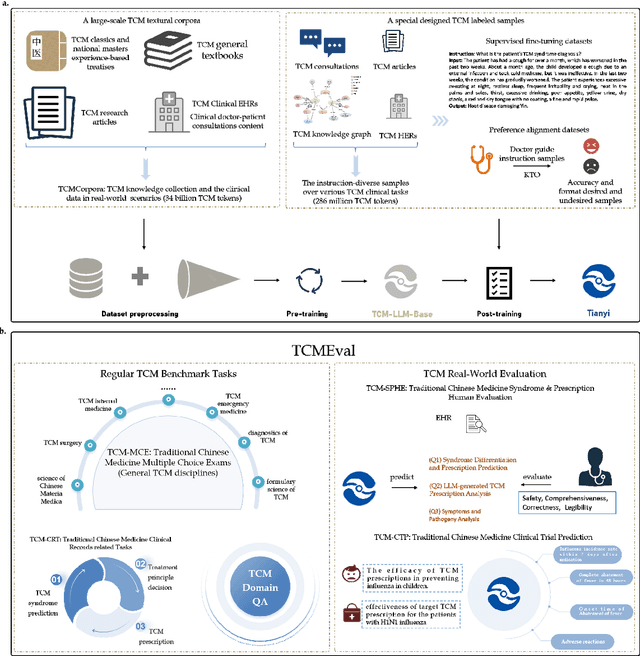
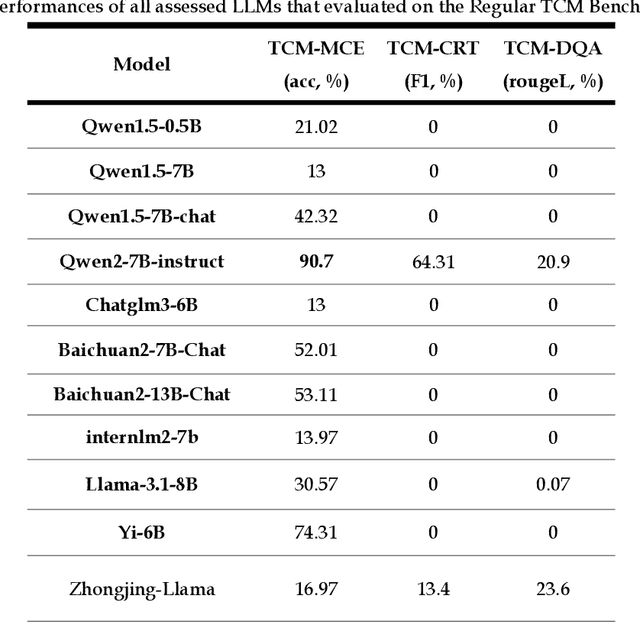

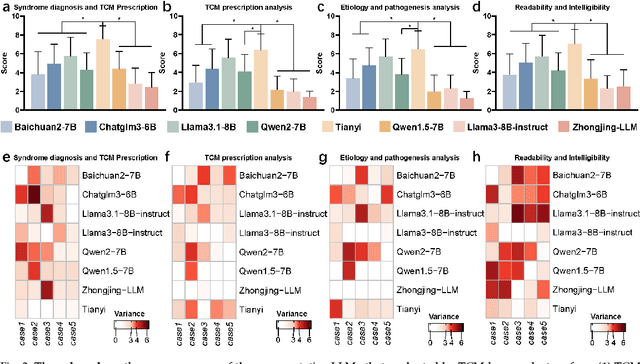
Natural medicines, particularly Traditional Chinese Medicine (TCM), are gaining global recognition for their therapeutic potential in addressing human symptoms and diseases. TCM, with its systematic theories and extensive practical experience, provides abundant resources for healthcare. However, the effective application of TCM requires precise syndrome diagnosis, determination of treatment principles, and prescription formulation, which demand decades of clinical expertise. Despite advancements in TCM-based decision systems, machine learning, and deep learning research, limitations in data and single-objective constraints hinder their practical application. In recent years, large language models (LLMs) have demonstrated potential in complex tasks, but lack specialization in TCM and face significant challenges, such as too big model scale to deploy and issues with hallucination. To address these challenges, we introduce Tianyi with 7.6-billion-parameter LLM, a model scale proper and specifically designed for TCM, pre-trained and fine-tuned on diverse TCM corpora, including classical texts, expert treatises, clinical records, and knowledge graphs. Tianyi is designed to assimilate interconnected and systematic TCM knowledge through a progressive learning manner. Additionally, we establish TCMEval, a comprehensive evaluation benchmark, to assess LLMs in TCM examinations, clinical tasks, domain-specific question-answering, and real-world trials. The extensive evaluations demonstrate the significant potential of Tianyi as an AI assistant in TCM clinical practice and research, bridging the gap between TCM knowledge and practical application.
From Easy to Hard: Building a Shortcut for Differentially Private Image Synthesis
Apr 02, 2025

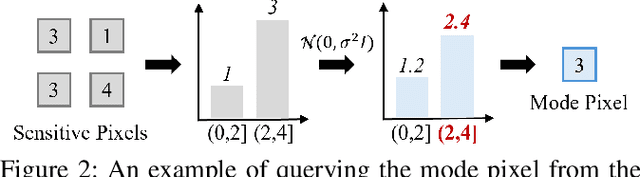

Differentially private (DP) image synthesis aims to generate synthetic images from a sensitive dataset, alleviating the privacy leakage concerns of organizations sharing and utilizing synthetic images. Although previous methods have significantly progressed, especially in training diffusion models on sensitive images with DP Stochastic Gradient Descent (DP-SGD), they still suffer from unsatisfactory performance. In this work, inspired by curriculum learning, we propose a two-stage DP image synthesis framework, where diffusion models learn to generate DP synthetic images from easy to hard. Unlike existing methods that directly use DP-SGD to train diffusion models, we propose an easy stage in the beginning, where diffusion models learn simple features of the sensitive images. To facilitate this easy stage, we propose to use `central images', simply aggregations of random samples of the sensitive dataset. Intuitively, although those central images do not show details, they demonstrate useful characteristics of all images and only incur minimal privacy costs, thus helping early-phase model training. We conduct experiments to present that on the average of four investigated image datasets, the fidelity and utility metrics of our synthetic images are 33.1% and 2.1% better than the state-of-the-art method.
Addressing Information Loss and Interaction Collapse: A Dual Enhanced Attention Framework for Feature Interaction
Mar 14, 2025The Transformer has proven to be a significant approach in feature interaction for CTR prediction, achieving considerable success in previous works. However, it also presents potential challenges in handling feature interactions. Firstly, Transformers may encounter information loss when capturing feature interactions. By relying on inner products to represent pairwise relationships, they compress raw interaction information, which can result in a degradation of fidelity. Secondly, due to the long-tail features distribution, feature fields with low information-abundance embeddings constrain the information abundance of other fields, leading to collapsed embedding matrices. To tackle these issues, we propose a Dual Attention Framework for Enhanced Feature Interaction, known as Dual Enhanced Attention. This framework integrates two attention mechanisms: the Combo-ID attention mechanism and the collapse-avoiding attention mechanism. The Combo-ID attention mechanism directly retains feature interaction pairs to mitigate information loss, while the collapse-avoiding attention mechanism adaptively filters out low information-abundance interaction pairs to prevent interaction collapse. Extensive experiments conducted on industrial datasets have shown the effectiveness of Dual Enhanced Attention.
Efficient Long Sequential Low-rank Adaptive Attention for Click-through rate Prediction
Mar 04, 2025In the context of burgeoning user historical behavior data, Accurate click-through rate(CTR) prediction requires effective modeling of lengthy user behavior sequences. As the volume of such data keeps swelling, the focus of research has shifted towards developing effective long-term behavior modeling methods to capture latent user interests. Nevertheless, the complexity introduced by large scale data brings about computational hurdles. There is a pressing need to strike a balance between achieving high model performance and meeting the strict response time requirements of online services. While existing retrieval-based methods (e.g., similarity filtering or attention approximation) achieve practical runtime efficiency, they inherently compromise information fidelity through aggressive sequence truncation or attention sparsification. This paper presents a novel attention mechanism. It overcomes the shortcomings of existing methods while ensuring computational efficiency. This mechanism learn compressed representation of sequence with length $L$ via low-rank projection matrices (rank $r \ll L$), reducing attention complexity from $O(L)$ to $O(r)$. It also integrates a uniquely designed loss function to preserve nonlinearity of attention. In the inference stage, the mechanism adopts matrix absorption and prestorage strategies. These strategies enable it to effectively satisfy online constraints. Comprehensive offline and online experiments demonstrate that the proposed method outperforms current state-of-the-art solutions.
AdaFlow: Opportunistic Inference on Asynchronous Mobile Data with Generalized Affinity Control
Oct 31, 2024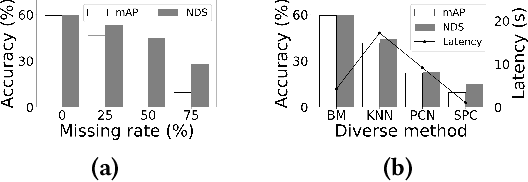


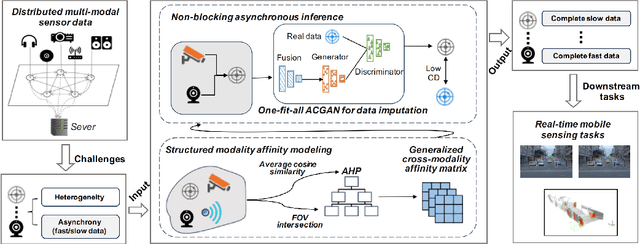
The rise of mobile devices equipped with numerous sensors, such as LiDAR and cameras, has spurred the adoption of multi-modal deep intelligence for distributed sensing tasks, such as smart cabins and driving assistance. However, the arrival times of mobile sensory data vary due to modality size and network dynamics, which can lead to delays (if waiting for slower data) or accuracy decline (if inference proceeds without waiting). Moreover, the diversity and dynamic nature of mobile systems exacerbate this challenge. In response, we present a shift to \textit{opportunistic} inference for asynchronous distributed multi-modal data, enabling inference as soon as partial data arrives. While existing methods focus on optimizing modality consistency and complementarity, known as modal affinity, they lack a \textit{computational} approach to control this affinity in open-world mobile environments. AdaFlow pioneers the formulation of structured cross-modality affinity in mobile contexts using a hierarchical analysis-based normalized matrix. This approach accommodates the diversity and dynamics of modalities, generalizing across different types and numbers of inputs. Employing an affinity attention-based conditional GAN (ACGAN), AdaFlow facilitates flexible data imputation, adapting to various modalities and downstream tasks without retraining. Experiments show that AdaFlow significantly reduces inference latency by up to 79.9\% and enhances accuracy by up to 61.9\%, outperforming status quo approaches.
Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages
Jul 03, 2024



Many recent works have explored using language models for planning problems. One line of research focuses on translating natural language descriptions of planning tasks into structured planning languages, such as the planning domain definition language (PDDL). While this approach is promising, accurately measuring the quality of generated PDDL code continues to pose significant challenges. First, generated PDDL code is typically evaluated using planning validators that check whether the problem can be solved with a planner. This method is insufficient because a language model might generate valid PDDL code that does not align with the natural language description of the task. Second, existing evaluation sets often have natural language descriptions of the planning task that closely resemble the ground truth PDDL, reducing the challenge of the task. To bridge this gap, we introduce \benchmarkName, a benchmark designed to evaluate language models' ability to generate PDDL code from natural language descriptions of planning tasks. We begin by creating a PDDL equivalence algorithm that rigorously evaluates the correctness of PDDL code generated by language models by flexibly comparing it against a ground truth PDDL. Then, we present a dataset of $132,037$ text-to-PDDL pairs across 13 different tasks, with varying levels of difficulty. Finally, we evaluate several API-access and open-weight language models that reveal this task's complexity. For example, $87.6\%$ of the PDDL problem descriptions generated by GPT-4o are syntactically parseable, $82.2\%$ are valid, solve-able problems, but only $35.1\%$ are semantically correct, highlighting the need for a more rigorous benchmark for this problem.
Preference Tuning For Toxicity Mitigation Generalizes Across Languages
Jun 23, 2024



Detoxifying multilingual Large Language Models (LLMs) has become crucial due to their increasing global use. In this work, we explore zero-shot cross-lingual generalization of preference tuning in detoxifying LLMs. Unlike previous studies that show limited cross-lingual generalization for other safety tasks, we demonstrate that Direct Preference Optimization (DPO) training with only English data can significantly reduce toxicity in multilingual open-ended generations. For example, the probability of mGPT-1.3B generating toxic continuations drops from 46.8% to 3.9% across 17 different languages after training. Our results also extend to other multilingual LLMs, such as BLOOM, Llama3, and Aya-23. Using mechanistic interpretability tools like causal intervention and activation analysis, we identified the dual multilinguality property of MLP layers in LLMs, which explains the cross-lingual generalization of DPO. Finally, we show that bilingual sentence retrieval can predict the cross-lingual transferability of DPO preference tuning.
Quantifying and Defending against Privacy Threats on Federated Knowledge Graph Embedding
Apr 06, 2023



Knowledge Graph Embedding (KGE) is a fundamental technique that extracts expressive representation from knowledge graph (KG) to facilitate diverse downstream tasks. The emerging federated KGE (FKGE) collaboratively trains from distributed KGs held among clients while avoiding exchanging clients' sensitive raw KGs, which can still suffer from privacy threats as evidenced in other federated model trainings (e.g., neural networks). However, quantifying and defending against such privacy threats remain unexplored for FKGE which possesses unique properties not shared by previously studied models. In this paper, we conduct the first holistic study of the privacy threat on FKGE from both attack and defense perspectives. For the attack, we quantify the privacy threat by proposing three new inference attacks, which reveal substantial privacy risk by successfully inferring the existence of the KG triple from victim clients. For the defense, we propose DP-Flames, a novel differentially private FKGE with private selection, which offers a better privacy-utility tradeoff by exploiting the entity-binding sparse gradient property of FKGE and comes with a tight privacy accountant by incorporating the state-of-the-art private selection technique. We further propose an adaptive privacy budget allocation policy to dynamically adjust defense magnitude across the training procedure. Comprehensive evaluations demonstrate that the proposed defense can successfully mitigate the privacy threat by effectively reducing the success rate of inference attacks from $83.1\%$ to $59.4\%$ on average with only a modest utility decrease.
AdaEnlight: Energy-aware Low-light Video Stream Enhancement on Mobile Devices
Nov 30, 2022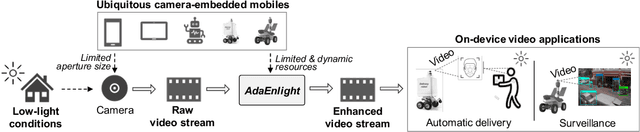

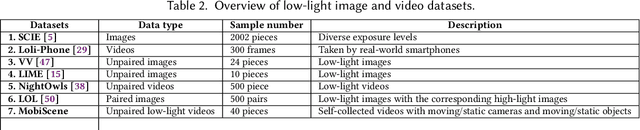
The ubiquity of camera-embedded devices and the advances in deep learning have stimulated various intelligent mobile video applications. These applications often demand on-device processing of video streams to deliver real-time, high-quality services for privacy and robustness concerns. However, the performance of these applications is constrained by the raw video streams, which tend to be taken with small-aperture cameras of ubiquitous mobile platforms in dim light. Despite extensive low-light video enhancement solutions, they are unfit for deployment to mobile devices due to their complex models and and ignorance of system dynamics like energy budgets. In this paper, we propose AdaEnlight, an energy-aware low-light video stream enhancement system on mobile devices. It achieves real-time video enhancement with competitive visual quality while allowing runtime behavior adaptation to the platform-imposed dynamic energy budgets. We report extensive experiments on diverse datasets, scenarios, and platforms and demonstrate the superiority of AdaEnlight compared with state-of-the-art low-light image and video enhancement solutions.