 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages
Jul 03, 2024



Many recent works have explored using language models for planning problems. One line of research focuses on translating natural language descriptions of planning tasks into structured planning languages, such as the planning domain definition language (PDDL). While this approach is promising, accurately measuring the quality of generated PDDL code continues to pose significant challenges. First, generated PDDL code is typically evaluated using planning validators that check whether the problem can be solved with a planner. This method is insufficient because a language model might generate valid PDDL code that does not align with the natural language description of the task. Second, existing evaluation sets often have natural language descriptions of the planning task that closely resemble the ground truth PDDL, reducing the challenge of the task. To bridge this gap, we introduce \benchmarkName, a benchmark designed to evaluate language models' ability to generate PDDL code from natural language descriptions of planning tasks. We begin by creating a PDDL equivalence algorithm that rigorously evaluates the correctness of PDDL code generated by language models by flexibly comparing it against a ground truth PDDL. Then, we present a dataset of $132,037$ text-to-PDDL pairs across 13 different tasks, with varying levels of difficulty. Finally, we evaluate several API-access and open-weight language models that reveal this task's complexity. For example, $87.6\%$ of the PDDL problem descriptions generated by GPT-4o are syntactically parseable, $82.2\%$ are valid, solve-able problems, but only $35.1\%$ are semantically correct, highlighting the need for a more rigorous benchmark for this problem.
ConSOR: A Context-Aware Semantic Object Rearrangement Framework for Partially Arranged Scenes
Sep 30, 2023



Object rearrangement is the problem of enabling a robot to identify the correct object placement in a complex environment. Prior work on object rearrangement has explored a diverse set of techniques for following user instructions to achieve some desired goal state. Logical predicates, images of the goal scene, and natural language descriptions have all been used to instruct a robot in how to arrange objects. In this work, we argue that burdening the user with specifying goal scenes is not necessary in partially-arranged environments, such as common household settings. Instead, we show that contextual cues from partially arranged scenes (i.e., the placement of some number of pre-arranged objects in the environment) provide sufficient context to enable robots to perform object rearrangement \textit{without any explicit user goal specification}. We introduce ConSOR, a Context-aware Semantic Object Rearrangement framework that utilizes contextual cues from a partially arranged initial state of the environment to complete the arrangement of new objects, without explicit goal specification from the user. We demonstrate that ConSOR strongly outperforms two baselines in generalizing to novel object arrangements and unseen object categories. The code and data can be found at https://github.com/kartikvrama/consor.
ATCON: Attention Consistency for Vision Models
Oct 18, 2022
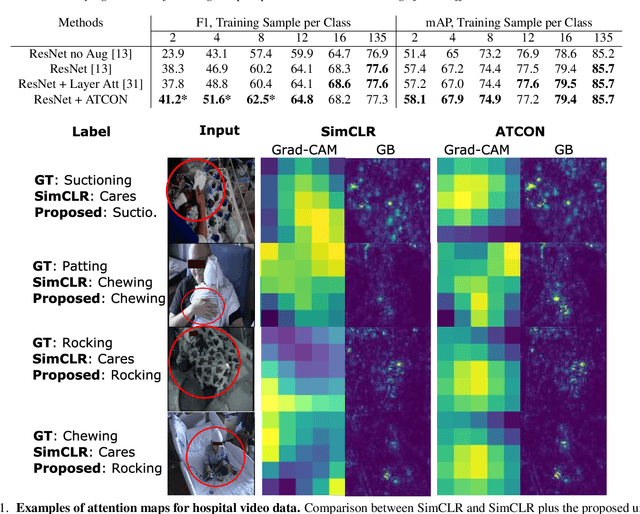

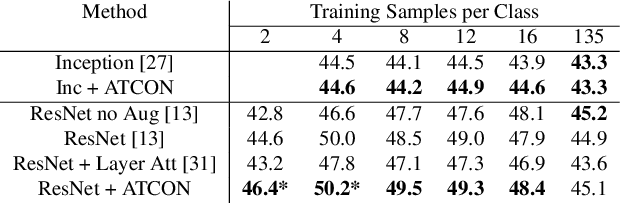
Attention--or attribution--maps methods are methods designed to highlight regions of the model's input that were discriminative for its predictions. However, different attention maps methods can highlight different regions of the input, with sometimes contradictory explanations for a prediction. This effect is exacerbated when the training set is small. This indicates that either the model learned incorrect representations or that the attention maps methods did not accurately estimate the model's representations. We propose an unsupervised fine-tuning method that optimizes the consistency of attention maps and show that it improves both classification performance and the quality of attention maps. We propose an implementation for two state-of-the-art attention computation methods, Grad-CAM and Guided Backpropagation, which relies on an input masking technique. We also show results on Grad-CAM and Integrated Gradients in an ablation study. We evaluate this method on our own dataset of event detection in continuous video recordings of hospital patients aggregated and curated for this work. As a sanity check, we also evaluate the proposed method on PASCAL VOC and SVHN. With the proposed method, with small training sets, we achieve a 6.6 points lift of F1 score over the baselines on our video dataset, a 2.9 point lift of F1 score on PASCAL, and a 1.8 points lift of mean Intersection over Union over Grad-CAM for weakly supervised detection on PASCAL. Those improved attention maps may help clinicians better understand vision model predictions and ease the deployment of machine learning systems into clinical care. We share part of the code for this article at the following repository: https://github.com/alimirzazadeh/SemisupervisedAttention.
Learning Efficient Exploration through Human Seeded Rapidly-exploring Random Trees
Mar 23, 2022
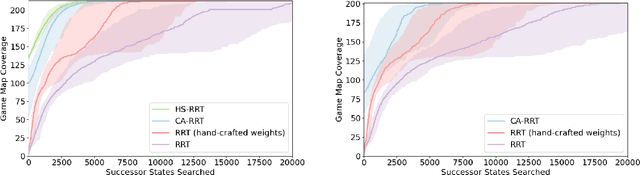
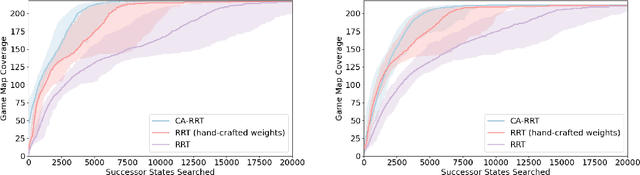
Modern day computer games have extremely large state and action spaces. To detect bugs in these games' models, human testers play the games repeatedly to explore the game and find errors in the games. Such game play is exhaustive and time consuming. Moreover, since robotics simulators depend on similar methods of model specification and debugging, the problem of finding errors in the model is of interest for the robotics community to ensure robot behaviors and interactions are consistent in simulators. Previous methods have used reinforcement learning and search based methods including Rapidly-exploring Random Trees (RRT) to explore a game's state-action space to find bugs. However, such search and exploration based methods are not efficient at exploring the state-action space without a pre-defined heuristic. In this work we attempt to combine a human-tester's expertise in solving games, and the exhaustiveness of RRT to search a game's state space efficiently with high coverage. This paper introduces human-seeded RRT (HS-RRT) and behavior-cloning-assisted RRT (CA-RRT) in testing the number of game states searched and the time taken to explore those game states. We compare our methods to an existing weighted RRT baseline for game exploration testing studied. We find HS-RRT and CA-RRT both explore more game states in fewer tree expansions/iterations when compared to the existing baseline. In each test, CA-RRT reached more states on average in the same number of iterations as RRT. In our tested environments, CA-RRT was able to reach the same number of states as RRT by more than 5000 fewer iterations on average, almost a 50% reduction.