 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Partial Observability in Sequential Decision Processes via the Lambda Discrepancy
Jul 10, 2024



Reinforcement learning algorithms typically rely on the assumption that the environment dynamics and value function can be expressed in terms of a Markovian state representation. However, when state information is only partially observable, how can an agent learn such a state representation, and how can it detect when it has found one? We introduce a metric that can accomplish both objectives, without requiring access to--or knowledge of--an underlying, unobservable state space. Our metric, the $\lambda$-discrepancy, is the difference between two distinct temporal difference (TD) value estimates, each computed using TD($\lambda$) with a different value of $\lambda$. Since TD($\lambda$=0) makes an implicit Markov assumption and TD($\lambda$=1) does not, a discrepancy between these estimates is a potential indicator of a non-Markovian state representation. Indeed, we prove that the $\lambda$-discrepancy is exactly zero for all Markov decision processes and almost always non-zero for a broad class of partially observable environments. We also demonstrate empirically that, once detected, minimizing the $\lambda$-discrepancy can help with learning a memory function to mitigate the corresponding partial observability. We then train a reinforcement learning agent that simultaneously constructs two recurrent value networks with different $\lambda$ parameters and minimizes the difference between them as an auxiliary loss. The approach scales to challenging partially observable domains, where the resulting agent frequently performs significantly better (and never performs worse) than a baseline recurrent agent with only a single value network.
Planetarium: A Rigorous Benchmark for Translating Text to Structured Planning Languages
Jul 03, 2024



Many recent works have explored using language models for planning problems. One line of research focuses on translating natural language descriptions of planning tasks into structured planning languages, such as the planning domain definition language (PDDL). While this approach is promising, accurately measuring the quality of generated PDDL code continues to pose significant challenges. First, generated PDDL code is typically evaluated using planning validators that check whether the problem can be solved with a planner. This method is insufficient because a language model might generate valid PDDL code that does not align with the natural language description of the task. Second, existing evaluation sets often have natural language descriptions of the planning task that closely resemble the ground truth PDDL, reducing the challenge of the task. To bridge this gap, we introduce \benchmarkName, a benchmark designed to evaluate language models' ability to generate PDDL code from natural language descriptions of planning tasks. We begin by creating a PDDL equivalence algorithm that rigorously evaluates the correctness of PDDL code generated by language models by flexibly comparing it against a ground truth PDDL. Then, we present a dataset of $132,037$ text-to-PDDL pairs across 13 different tasks, with varying levels of difficulty. Finally, we evaluate several API-access and open-weight language models that reveal this task's complexity. For example, $87.6\%$ of the PDDL problem descriptions generated by GPT-4o are syntactically parseable, $82.2\%$ are valid, solve-able problems, but only $35.1\%$ are semantically correct, highlighting the need for a more rigorous benchmark for this problem.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023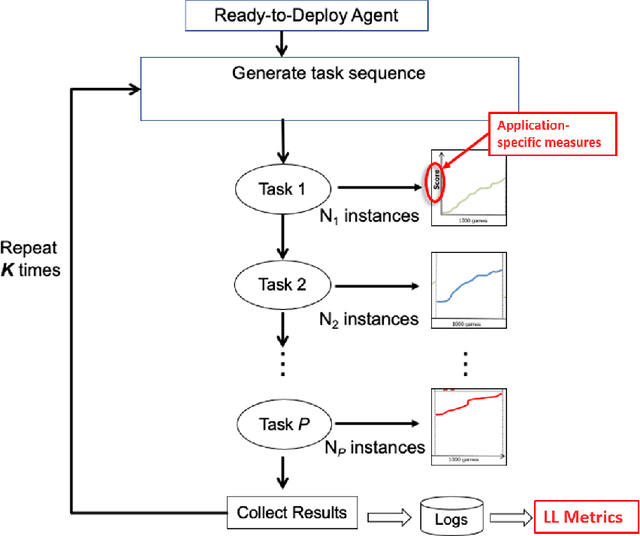
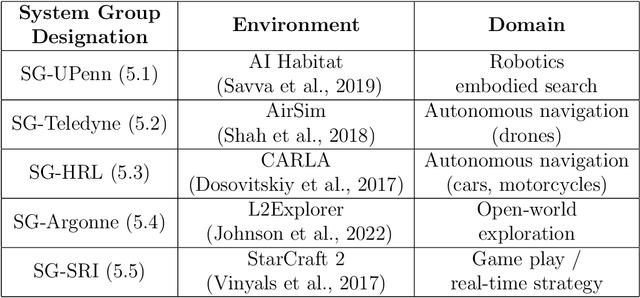


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Specifying Behavior Preference with Tiered Reward Functions
Dec 07, 2022Reinforcement-learning agents seek to maximize a reward signal through environmental interactions. As humans, our contribution to the learning process is through designing the reward function. Like programmers, we have a behavior in mind and have to translate it into a formal specification, namely rewards. In this work, we consider the reward-design problem in tasks formulated as reaching desirable states and avoiding undesirable states. To start, we propose a strict partial ordering of the policy space. We prefer policies that reach the good states faster and with higher probability while avoiding the bad states longer. Next, we propose an environment-independent tiered reward structure and show it is guaranteed to induce policies that are Pareto-optimal according to our preference relation. Finally, we empirically evaluate tiered reward functions on several environments and show they induce desired behavior and lead to fast learning.
Evaluation Beyond Task Performance: Analyzing Concepts in AlphaZero in Hex
Nov 26, 2022AlphaZero, an approach to reinforcement learning that couples neural networks and Monte Carlo tree search (MCTS), has produced state-of-the-art strategies for traditional board games like chess, Go, shogi, and Hex. While researchers and game commentators have suggested that AlphaZero uses concepts that humans consider important, it is unclear how these concepts are captured in the network. We investigate AlphaZero's internal representations in the game of Hex using two evaluation techniques from natural language processing (NLP): model probing and behavioral tests. In doing so, we introduce new evaluation tools to the RL community and illustrate how evaluations other than task performance can be used to provide a more complete picture of a model's strengths and weaknesses. Our analyses in the game of Hex reveal interesting patterns and generate some testable hypotheses about how such models learn in general. For example, we find that MCTS discovers concepts before the neural network learns to encode them. We also find that concepts related to short-term end-game planning are best encoded in the final layers of the model, whereas concepts related to long-term planning are encoded in the middle layers of the model.
Reward-Predictive Clustering
Nov 07, 2022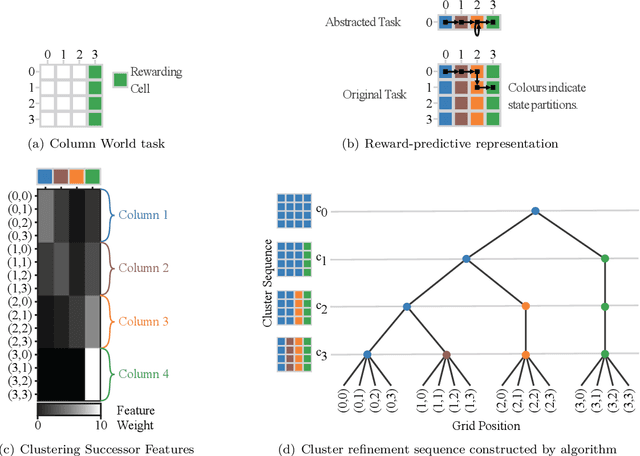
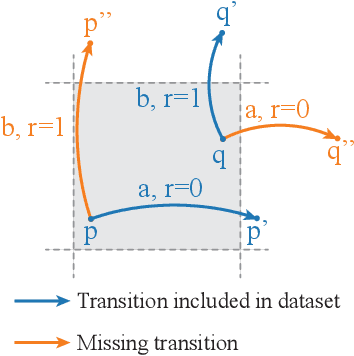

Recent advances in reinforcement-learning research have demonstrated impressive results in building algorithms that can out-perform humans in complex tasks. Nevertheless, creating reinforcement-learning systems that can build abstractions of their experience to accelerate learning in new contexts still remains an active area of research. Previous work showed that reward-predictive state abstractions fulfill this goal, but have only be applied to tabular settings. Here, we provide a clustering algorithm that enables the application of such state abstractions to deep learning settings, providing compressed representations of an agent's inputs that preserve the ability to predict sequences of reward. A convergence theorem and simulations show that the resulting reward-predictive deep network maximally compresses the agent's inputs, significantly speeding up learning in high dimensional visual control tasks. Furthermore, we present different generalization experiments and analyze under which conditions a pre-trained reward-predictive representation network can be re-used without re-training to accelerate learning -- a form of systematic out-of-distribution transfer.
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
Designing Rewards for Fast Learning
May 30, 2022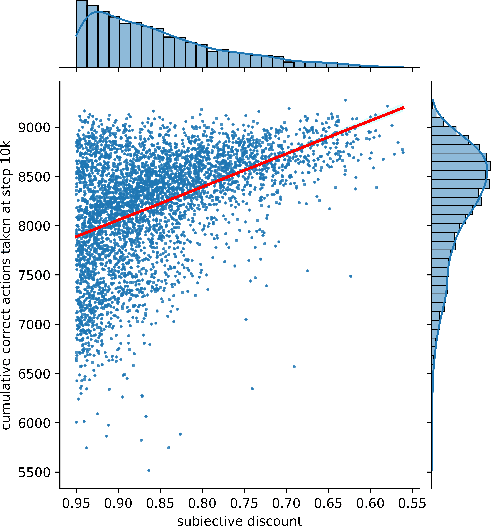
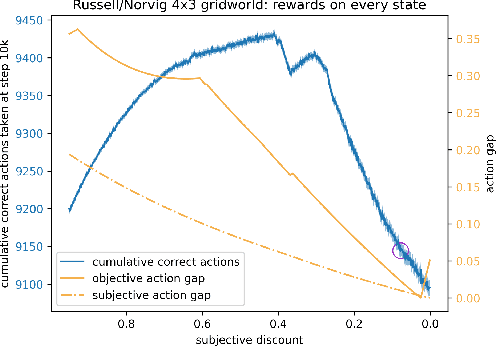
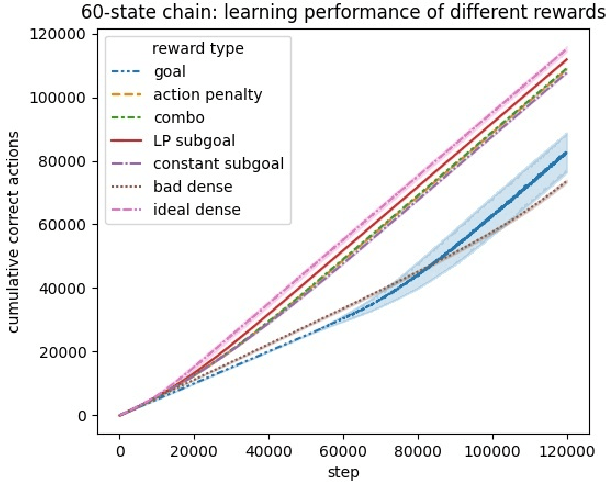
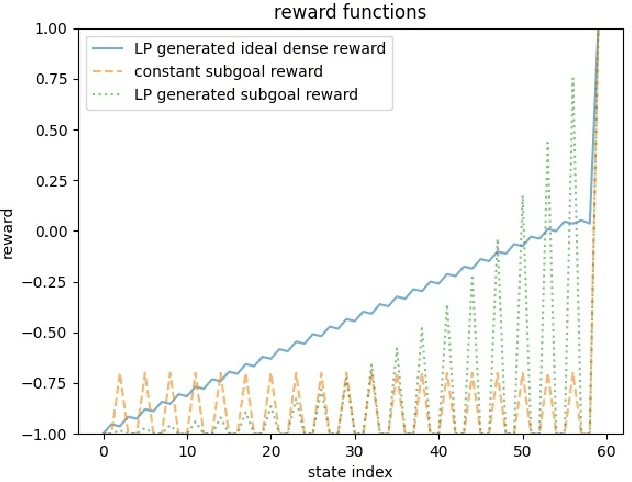
To convey desired behavior to a Reinforcement Learning (RL) agent, a designer must choose a reward function for the environment, arguably the most important knob designers have in interacting with RL agents. Although many reward functions induce the same optimal behavior (Ng et al., 1999), in practice, some of them result in faster learning than others. In this paper, we look at how reward-design choices impact learning speed and seek to identify principles of good reward design that quickly induce target behavior. This reward-identification problem is framed as an optimization problem: Firstly, we advocate choosing state-based rewards that maximize the action gap, making optimal actions easy to distinguish from suboptimal ones. Secondly, we propose minimizing a measure of the horizon, something we call the "subjective discount", over which rewards need to be optimized to encourage agents to make optimal decisions with less lookahead. To solve this optimization problem, we propose a linear-programming based algorithm that efficiently finds a reward function that maximizes action gap and minimizes subjective discount. We test the rewards generated with the algorithm in tabular environments with Q-Learning, and empirically show they lead to faster learning. Although we only focus on Q-Learning because it is perhaps the simplest and most well understood RL algorithm, preliminary results with R-max (Brafman and Tennenholtz, 2000) suggest our results are much more general. Our experiments support three principles of reward design: 1) consistent with existing results, penalizing each step taken induces faster learning than rewarding the goal. 2) When rewarding subgoals along the target trajectory, rewards should gradually increase as the goal gets closer. 3) Dense reward that's nonzero on every state is only good if designed carefully.
Deep Q-Network with Proximal Iteration
Dec 10, 2021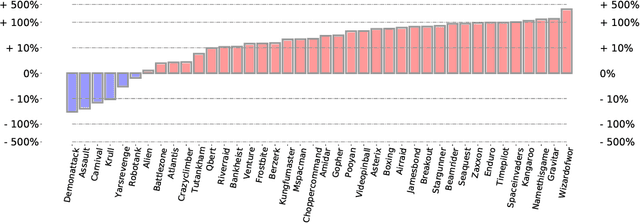

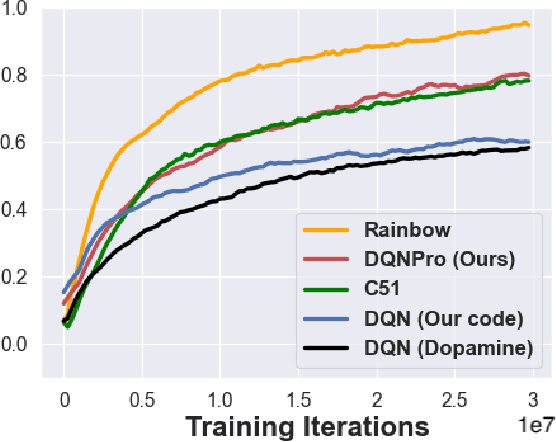

We employ Proximal Iteration for value-function optimization in reinforcement learning. Proximal Iteration is a computationally efficient technique that enables us to bias the optimization procedure towards more desirable solutions. As a concrete application of Proximal Iteration in deep reinforcement learning, we endow the objective function of the Deep Q-Network (DQN) agent with a proximal term to ensure that the online-network component of DQN remains in the vicinity of the target network. The resultant agent, which we call DQN with Proximal Iteration, or DQNPro, exhibits significant improvements over the original DQN on the Atari benchmark. Our results accentuate the power of employing sound optimization techniques for deep reinforcement learning.
On the Expressivity of Markov Reward
Nov 01, 2021



Reward is the driving force for reinforcement-learning agents. This paper is dedicated to understanding the expressivity of reward as a way to capture tasks that we would want an agent to perform. We frame this study around three new abstract notions of "task" that might be desirable: (1) a set of acceptable behaviors, (2) a partial ordering over behaviors, or (3) a partial ordering over trajectories. Our main results prove that while reward can express many of these tasks, there exist instances of each task type that no Markov reward function can capture. We then provide a set of polynomial-time algorithms that construct a Markov reward function that allows an agent to optimize tasks of each of these three types, and correctly determine when no such reward function exists. We conclude with an empirical study that corroborates and illustrates our theoretical findings.