 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling and Interpreting Missing Modalities in Patient Clinical Trajectories via Autoregressive Sequence Modeling
Apr 20, 2026An active challenge in developing multimodal machine learning (ML) models for healthcare is handling missing modalities during training and deployment. As clinical datasets are inherently temporal and sparse in terms of modality presence, capturing the underlying predictive signal via diagnostic multimodal ML models while retaining model explainability remains an ongoing challenge. In this work, we address this by re-framing clinical diagnosis as an autoregressive sequence modeling task, utilizing causal decoders from large language models (LLMs) to model a patient's multimodal trajectory. We first introduce a missingness-aware contrastive pre-training objective that integrates multiple modalities in datasets with missingness in a shared latent space. We then show that autoregressive sequence modeling with transformer-based architectures outperforms baselines on the MIMIC-IV and eICU fine-tuning benchmarks. Finally, we use interpretability techniques to move beyond performance boosts and find that across various patient stays, removing modalities leads to divergent behavior that our contrastive pre-training mitigates. By abstracting clinical diagnosis as sequence modeling and interpreting patient stay trajectories, we develop a framework to profile and handle missing modalities while addressing the canonical desideratum of safe, transparent clinical AI.
Video Finetuning Improves Reasoning Between Frames
Nov 17, 2025Multimodal large language models (LLMs) have made rapid progress in visual understanding, yet their extension from images to videos often reduces to a naive concatenation of frame tokens. In this work, we investigate what video finetuning brings to multimodal LLMs. We propose Visual Chain-of-Thought (vCoT), an explicit reasoning process that generates transitional event descriptions between consecutive frames. Using vCoT, we systematically compare image-only LVLMs with their video-finetuned counterparts, both with and without access to these transitional cues. Our experiments show that vCoT significantly improves the performance of image-only models on long-form video question answering, while yielding only marginal gains for video-finetuned models. This suggests that the latter already capture frame-to-frame transitions implicitly. Moreover, we find that video models transfer this temporal reasoning ability to purely static settings, outperforming image models' baselines on relational visual reasoning tasks.
How Do Language Models Compose Functions?
Oct 02, 2025While large language models (LLMs) appear to be increasingly capable of solving compositional tasks, it is an open question whether they do so using compositional mechanisms. In this work, we investigate how feedforward LLMs solve two-hop factual recall tasks, which can be expressed compositionally as $g(f(x))$. We first confirm that modern LLMs continue to suffer from the "compositionality gap": i.e. their ability to compute both $z = f(x)$ and $y = g(z)$ does not entail their ability to compute the composition $y = g(f(x))$. Then, using logit lens on their residual stream activations, we identify two processing mechanisms, one which solves tasks $\textit{compositionally}$, computing $f(x)$ along the way to computing $g(f(x))$, and one which solves them $\textit{directly}$, without any detectable signature of the intermediate variable $f(x)$. Finally, we find that which mechanism is employed appears to be related to the embedding space geometry, with the idiomatic mechanism being dominant in cases where there exists a linear mapping from $x$ to $g(f(x))$ in the embedding spaces. We fully release our data and code at: https://github.com/apoorvkh/composing-functions .
What is an "Abstract Reasoner"? Revisiting Experiments and Arguments about Large Language Models
Jul 30, 2025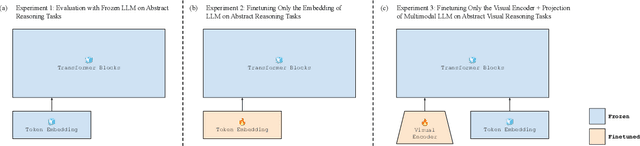


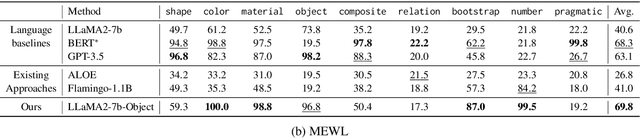
Recent work has argued that large language models (LLMs) are not "abstract reasoners", citing their poor zero-shot performance on a variety of challenging tasks as evidence. We revisit these experiments in order to add nuance to the claim. First, we show that while LLMs indeed perform poorly in a zero-shot setting, even tuning a small subset of parameters for input encoding can enable near-perfect performance. However, we also show that this finetuning does not necessarily transfer across datasets. We take this collection of empirical results as an invitation to (re-)open the discussion of what it means to be an "abstract reasoner", and why it matters whether LLMs fit the bill.
How Do Vision-Language Models Process Conflicting Information Across Modalities?
Jul 02, 2025AI models are increasingly required to be multimodal, integrating disparate input streams into a coherent state representation on which subsequent behaviors and actions can be based. This paper seeks to understand how such models behave when input streams present conflicting information. Focusing specifically on vision-language models, we provide inconsistent inputs (e.g., an image of a dog paired with the caption "A photo of a cat") and ask the model to report the information present in one of the specific modalities (e.g., "What does the caption say / What is in the image?"). We find that models often favor one modality over the other, e.g., reporting the image regardless of what the caption says, but that different models differ in which modality they favor. We find evidence that the behaviorally preferred modality is evident in the internal representational structure of the model, and that specific attention heads can restructure the representations to favor one modality over the other. Moreover, we find modality-agnostic "router heads" which appear to promote answers about the modality requested in the instruction, and which can be manipulated or transferred in order to improve performance across datasets and modalities. Together, the work provides essential steps towards identifying and controlling if and how models detect and resolve conflicting signals within complex multimodal environments.
Transferring Features Across Language Models With Model Stitching
Jun 07, 2025In this work, we demonstrate that affine mappings between residual streams of language models is a cheap way to effectively transfer represented features between models. We apply this technique to transfer the weights of Sparse Autoencoders (SAEs) between models of different sizes to compare their representations. We find that small and large models learn highly similar representation spaces, which motivates training expensive components like SAEs on a smaller model and transferring to a larger model at a FLOPs savings. For example, using a small-to-large transferred SAE as initialization can lead to 50% cheaper training runs when training SAEs on larger models. Next, we show that transferred probes and steering vectors can effectively recover ground truth performance. Finally, we dive deeper into feature-level transferability, finding that semantic and structural features transfer noticeably differently while specific classes of functional features have their roles faithfully mapped. Overall, our findings illustrate similarities and differences in the linear representation spaces of small and large models and demonstrate a method for improving the training efficiency of SAEs.
Paths Not Taken: Understanding and Mending the Multilingual Factual Recall Pipeline
May 28, 2025Multilingual large language models (LLMs) often exhibit factual inconsistencies across languages, with significantly better performance in factual recall tasks in English than in other languages. The causes of these failures, however, remain poorly understood. Using mechanistic analysis techniques, we uncover the underlying pipeline that LLMs employ, which involves using the English-centric factual recall mechanism to process multilingual queries and then translating English answers back into the target language. We identify two primary sources of error: insufficient engagement of the reliable English-centric mechanism for factual recall, and incorrect translation from English back into the target language for the final answer. To address these vulnerabilities, we introduce two vector interventions, both independent of languages and datasets, to redirect the model toward better internal paths for higher factual consistency. Our interventions combined increase the recall accuracy by over 35 percent for the lowest-performing language. Our findings demonstrate how mechanistic insights can be used to unlock latent multilingual capabilities in LLMs.
Born a Transformer -- Always a Transformer?
May 27, 2025Transformers have theoretical limitations in modeling certain sequence-to-sequence tasks, yet it remains largely unclear if these limitations play a role in large-scale pretrained LLMs, or whether LLMs might effectively overcome these constraints in practice due to the scale of both the models themselves and their pretraining data. We explore how these architectural constraints manifest after pretraining, by studying a family of $\textit{retrieval}$ and $\textit{copying}$ tasks inspired by Liu et al. [2024]. We use the recently proposed C-RASP framework for studying length generalization [Huang et al., 2025b] to provide guarantees for each of our settings. Empirically, we observe an $\textit{induction-versus-anti-induction}$ asymmetry, where pretrained models are better at retrieving tokens to the right (induction) rather than the left (anti-induction) of a query token. This asymmetry disappears upon targeted fine-tuning if length-generalization is guaranteed by theory. Mechanistic analysis reveals that this asymmetry is connected to the differences in the strength of induction versus anti-induction circuits within pretrained Transformers. We validate our findings through practical experiments on real-world tasks demonstrating reliability risks. Our results highlight that pretraining selectively enhances certain Transformer capabilities, but does not overcome fundamental length-generalization limits.
EHOP: A Dataset of Everyday NP-Hard Optimization Problems
Feb 19, 2025We introduce the dataset of Everyday Hard Optimization Problems (EHOP), a collection of NP-hard optimization problems expressed in natural language. EHOP includes problem formulations that could be found in computer science textbooks, versions that are dressed up as problems that could arise in real life, and variants of well-known problems with inverted rules. We find that state-of-the-art LLMs, across multiple prompting strategies, systematically solve textbook problems more accurately than their real-life and inverted counterparts. We argue that this constitutes evidence that LLMs adapt solutions seen during training, rather than leveraging reasoning abilities that would enable them to generalize to novel problems.
Does Training on Synthetic Data Make Models Less Robust?
Feb 11, 2025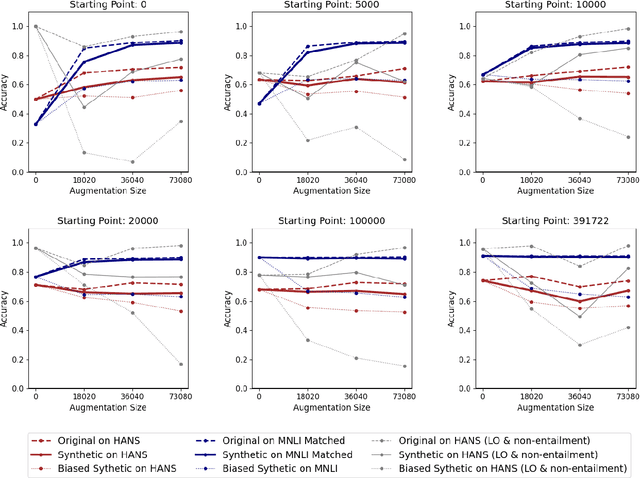
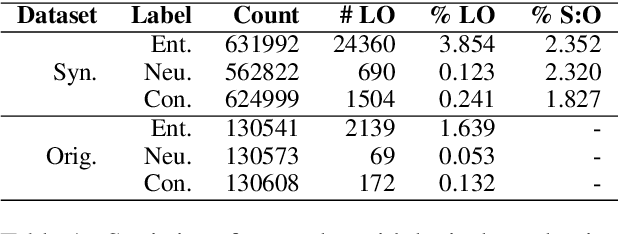
An increasingly common practice is to train large language models (LLMs) using synthetic data. Often this synthetic data is produced by the same or similar LLMs as those it is being used to train. This raises the question of whether the synthetic data might in fact exacerbate certain "blindspots" by reinforcing heuristics that the LLM already encodes. In this paper, we conduct simulated experiments on the natural language inference (NLI) task with Llama-2-7B-hf models. We use MultiNLI as the general task and HANS, a targeted evaluation set designed to measure the presence of specific heuristic strategies for NLI, as our "blindspot" task. Our goal is to determine whether performance disparities between the general and blind spot tasks emerge. Our results indicate that synthetic data does not reinforce blindspots in the way we expected. Specifically, we see that, while fine-tuning with synthetic data doesn't necessarily reduce the use of the heuristic, it also does not make it worse as we hypothesized.