 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Finetuning Improves Reasoning Between Frames
Nov 17, 2025Multimodal large language models (LLMs) have made rapid progress in visual understanding, yet their extension from images to videos often reduces to a naive concatenation of frame tokens. In this work, we investigate what video finetuning brings to multimodal LLMs. We propose Visual Chain-of-Thought (vCoT), an explicit reasoning process that generates transitional event descriptions between consecutive frames. Using vCoT, we systematically compare image-only LVLMs with their video-finetuned counterparts, both with and without access to these transitional cues. Our experiments show that vCoT significantly improves the performance of image-only models on long-form video question answering, while yielding only marginal gains for video-finetuned models. This suggests that the latter already capture frame-to-frame transitions implicitly. Moreover, we find that video models transfer this temporal reasoning ability to purely static settings, outperforming image models' baselines on relational visual reasoning tasks.
What is an "Abstract Reasoner"? Revisiting Experiments and Arguments about Large Language Models
Jul 30, 2025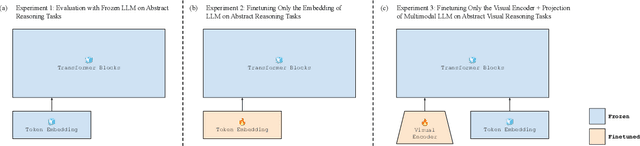


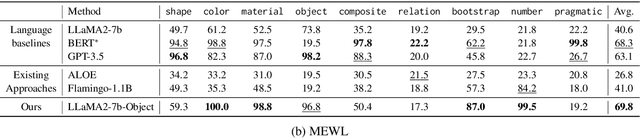
Recent work has argued that large language models (LLMs) are not "abstract reasoners", citing their poor zero-shot performance on a variety of challenging tasks as evidence. We revisit these experiments in order to add nuance to the claim. First, we show that while LLMs indeed perform poorly in a zero-shot setting, even tuning a small subset of parameters for input encoding can enable near-perfect performance. However, we also show that this finetuning does not necessarily transfer across datasets. We take this collection of empirical results as an invitation to (re-)open the discussion of what it means to be an "abstract reasoner", and why it matters whether LLMs fit the bill.
How Do Vision-Language Models Process Conflicting Information Across Modalities?
Jul 02, 2025AI models are increasingly required to be multimodal, integrating disparate input streams into a coherent state representation on which subsequent behaviors and actions can be based. This paper seeks to understand how such models behave when input streams present conflicting information. Focusing specifically on vision-language models, we provide inconsistent inputs (e.g., an image of a dog paired with the caption "A photo of a cat") and ask the model to report the information present in one of the specific modalities (e.g., "What does the caption say / What is in the image?"). We find that models often favor one modality over the other, e.g., reporting the image regardless of what the caption says, but that different models differ in which modality they favor. We find evidence that the behaviorally preferred modality is evident in the internal representational structure of the model, and that specific attention heads can restructure the representations to favor one modality over the other. Moreover, we find modality-agnostic "router heads" which appear to promote answers about the modality requested in the instruction, and which can be manipulated or transferred in order to improve performance across datasets and modalities. Together, the work provides essential steps towards identifying and controlling if and how models detect and resolve conflicting signals within complex multimodal environments.
TACO: Enhancing Multimodal In-context Learning via Task Mapping-Guided Sequence Configuration
May 21, 2025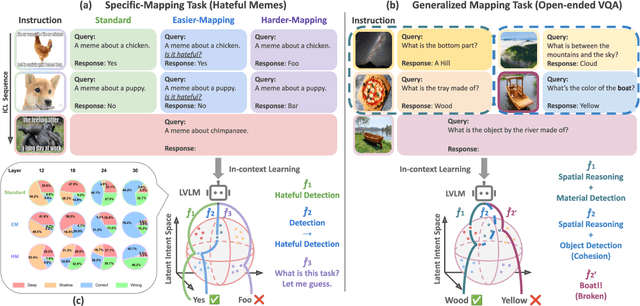
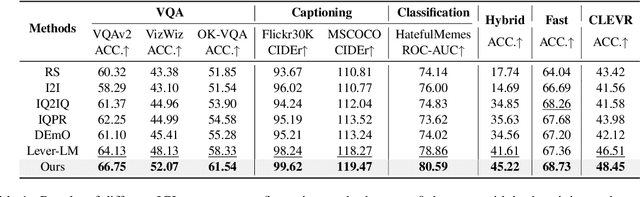
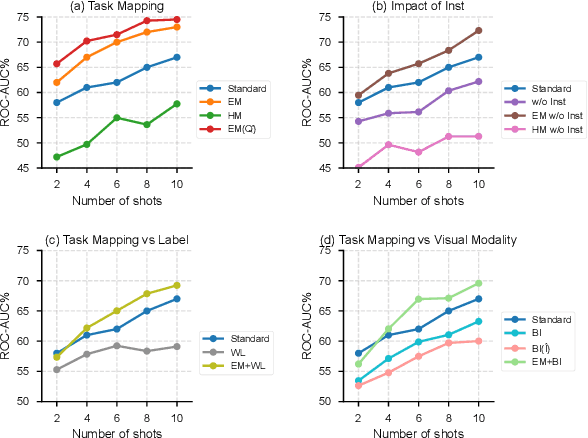
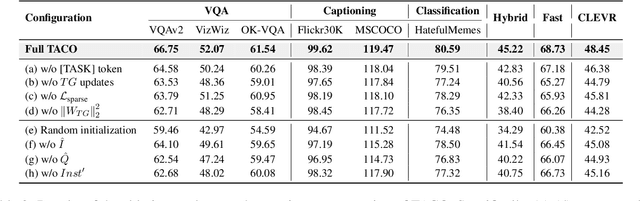
Multimodal in-context learning (ICL) has emerged as a key mechanism for harnessing the capabilities of large vision-language models (LVLMs). However, its effectiveness remains highly sensitive to the quality of input in-context sequences, particularly for tasks involving complex reasoning or open-ended generation. A major limitation is our limited understanding of how LVLMs actually exploit these sequences during inference. To bridge this gap, we systematically interpret multimodal ICL through the lens of task mapping, which reveals how local and global relationships within and among demonstrations guide model reasoning. Building on this insight, we present TACO, a lightweight transformer-based model equipped with task-aware attention that dynamically configures in-context sequences. By injecting task-mapping signals into the autoregressive decoding process, TACO creates a bidirectional synergy between sequence construction and task reasoning. Experiments on five LVLMs and nine datasets demonstrate that TACO consistently surpasses baselines across diverse ICL tasks. These results position task mapping as a valuable perspective for interpreting and improving multimodal ICL.
$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Oct 30, 2024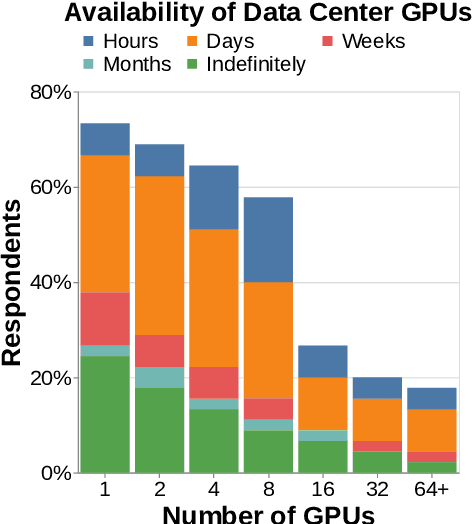
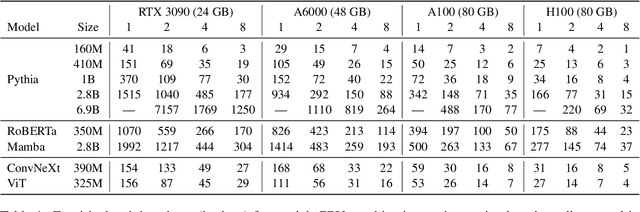
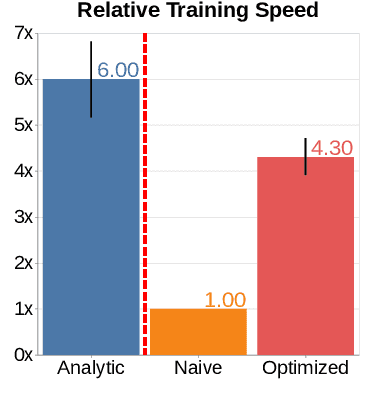
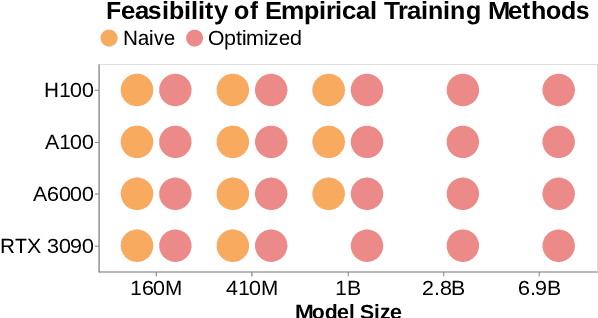
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.
Pre-trained Vision-Language Models Learn Discoverable Visual Concepts
Apr 19, 2024Do vision-language models (VLMs) pre-trained to caption an image of a "durian" learn visual concepts such as "brown" (color) and "spiky" (texture) at the same time? We aim to answer this question as visual concepts learned "for free" would enable wide applications such as neuro-symbolic reasoning or human-interpretable object classification. We assume that the visual concepts, if captured by pre-trained VLMs, can be extracted by their vision-language interface with text-based concept prompts. We observe that recent works prompting VLMs with concepts often differ in their strategies to define and evaluate the visual concepts, leading to conflicting conclusions. We propose a new concept definition strategy based on two observations: First, certain concept prompts include shortcuts that recognize correct concepts for wrong reasons; Second, multimodal information (e.g. visual discriminativeness, and textual knowledge) should be leveraged when selecting the concepts. Our proposed concept discovery and learning (CDL) framework is thus designed to identify a diverse list of generic visual concepts (e.g. "spiky" as opposed to "spiky durian"), which are ranked and selected based on visual and language mutual information. We carefully design quantitative and human evaluations of the discovered concepts on six diverse visual recognition datasets, which confirm that pre-trained VLMs do learn visual concepts that provide accurate and thorough descriptions for the recognized objects. All code and models are publicly released.
mOthello: When Do Cross-Lingual Representation Alignment and Cross-Lingual Transfer Emerge in Multilingual Models?
Apr 18, 2024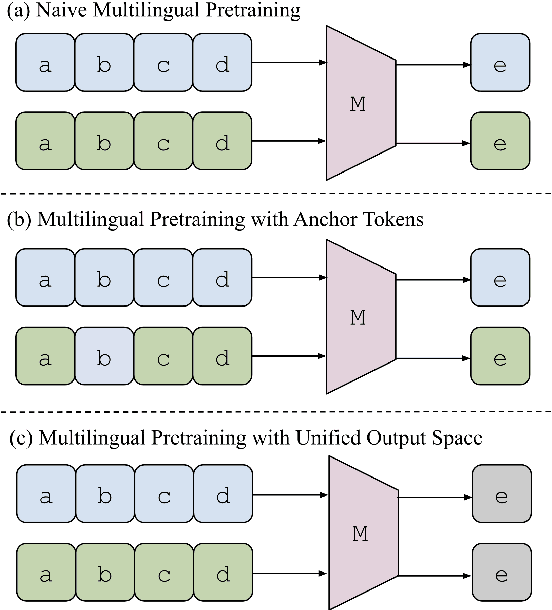

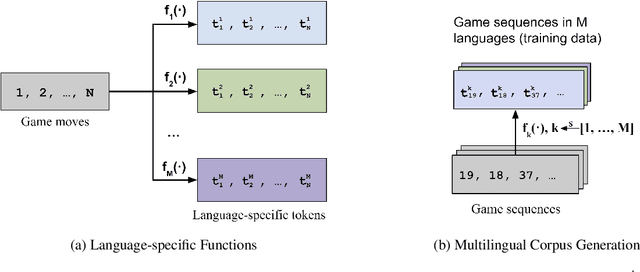

Many pretrained multilingual models exhibit cross-lingual transfer ability, which is often attributed to a learned language-neutral representation during pretraining. However, it remains unclear what factors contribute to the learning of a language-neutral representation, and whether the learned language-neutral representation suffices to facilitate cross-lingual transfer. We propose a synthetic task, Multilingual Othello (mOthello), as a testbed to delve into these two questions. We find that: (1) models trained with naive multilingual pretraining fail to learn a language-neutral representation across all input languages; (2) the introduction of "anchor tokens" (i.e., lexical items that are identical across languages) helps cross-lingual representation alignment; and (3) the learning of a language-neutral representation alone is not sufficient to facilitate cross-lingual transfer. Based on our findings, we propose a novel approach - multilingual pretraining with unified output space - that both induces the learning of language-neutral representation and facilitates cross-lingual transfer.
Emergence of Abstract State Representations in Embodied Sequence Modeling
Nov 07, 2023Decision making via sequence modeling aims to mimic the success of language models, where actions taken by an embodied agent are modeled as tokens to predict. Despite their promising performance, it remains unclear if embodied sequence modeling leads to the emergence of internal representations that represent the environmental state information. A model that lacks abstract state representations would be liable to make decisions based on surface statistics which fail to generalize. We take the BabyAI environment, a grid world in which language-conditioned navigation tasks are performed, and build a sequence modeling Transformer, which takes a language instruction, a sequence of actions, and environmental observations as its inputs. In order to investigate the emergence of abstract state representations, we design a "blindfolded" navigation task, where only the initial environmental layout, the language instruction, and the action sequence to complete the task are available for training. Our probing results show that intermediate environmental layouts can be reasonably reconstructed from the internal activations of a trained model, and that language instructions play a role in the reconstruction accuracy. Our results suggest that many key features of state representations can emerge via embodied sequence modeling, supporting an optimistic outlook for applications of sequence modeling objectives to more complex embodied decision-making domains.
Improved Inference of Human Intent by Combining Plan Recognition and Language Feedback
Oct 03, 2023



Conversational assistive robots can aid people, especially those with cognitive impairments, to accomplish various tasks such as cooking meals, performing exercises, or operating machines. However, to interact with people effectively, robots must recognize human plans and goals from noisy observations of human actions, even when the user acts sub-optimally. Previous works on Plan and Goal Recognition (PGR) as planning have used hierarchical task networks (HTN) to model the actor/human. However, these techniques are insufficient as they do not have user engagement via natural modes of interaction such as language. Moreover, they have no mechanisms to let users, especially those with cognitive impairments, know of a deviation from their original plan or about any sub-optimal actions taken towards their goal. We propose a novel framework for plan and goal recognition in partially observable domains -- Dialogue for Goal Recognition (D4GR) enabling a robot to rectify its belief in human progress by asking clarification questions about noisy sensor data and sub-optimal human actions. We evaluate the performance of D4GR over two simulated domains -- kitchen and blocks domain. With language feedback and the world state information in a hierarchical task model, we show that D4GR framework for the highest sensor noise performs 1% better than HTN in goal accuracy in both domains. For plan accuracy, D4GR outperforms by 4% in the kitchen domain and 2% in the blocks domain in comparison to HTN. The ALWAYS-ASK oracle outperforms our policy by 3% in goal recognition and 7%in plan recognition. D4GR does so by asking 68% fewer questions than an oracle baseline. We also demonstrate a real-world robot scenario in the kitchen domain, validating the improved plan and goal recognition of D4GR in a realistic setting.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.