 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Paper and Code
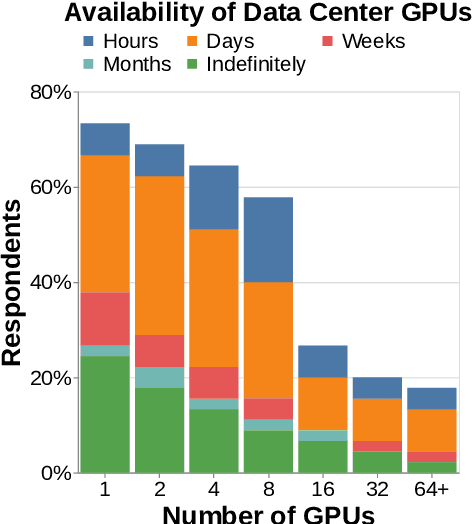
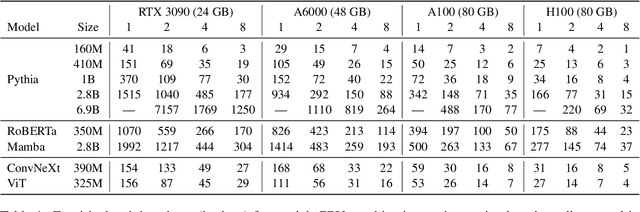
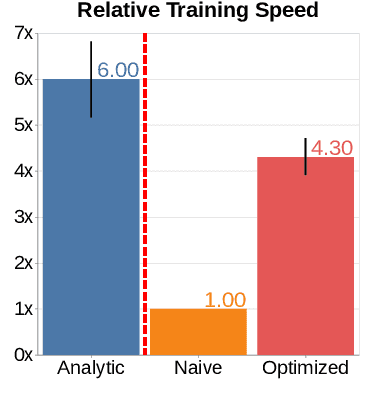
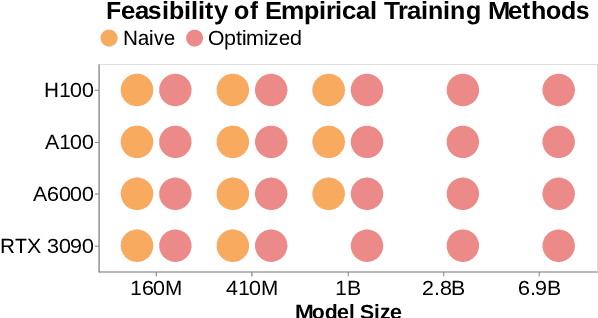
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.