 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Shape of Beliefs: Geometry, Dynamics, and Interventions along Representation Manifolds of Language Models' Posteriors
Feb 02, 2026Large language models (LLMs) represent prompt-conditioned beliefs (posteriors over answers and claims), but we lack a mechanistic account of how these beliefs are encoded in representation space, how they update with new evidence, and how interventions reshape them. We study a controlled setting in which Llama-3.2 generates samples from a normal distribution by implicitly inferring its parameters (mean and standard deviation) given only samples from the distribution in context. We find representations of curved "belief manifolds" for these parameters form with sufficient in-context learning and study how the model adapts when the distribution suddenly changes. While standard linear steering often pushes the model off-manifold and induces coupled, out-of-distribution shifts, geometry and field-aware steering better preserves the intended belief family. Our work demonstrates an example of linear field probing (LFP) as a simple approach to tile the data manifold and make interventions that respect the underlying geometry. We conclude that rich structure emerges naturally in LLMs and that purely linear concept representations are often an inadequate abstraction.
Transferring Features Across Language Models With Model Stitching
Jun 07, 2025In this work, we demonstrate that affine mappings between residual streams of language models is a cheap way to effectively transfer represented features between models. We apply this technique to transfer the weights of Sparse Autoencoders (SAEs) between models of different sizes to compare their representations. We find that small and large models learn highly similar representation spaces, which motivates training expensive components like SAEs on a smaller model and transferring to a larger model at a FLOPs savings. For example, using a small-to-large transferred SAE as initialization can lead to 50% cheaper training runs when training SAEs on larger models. Next, we show that transferred probes and steering vectors can effectively recover ground truth performance. Finally, we dive deeper into feature-level transferability, finding that semantic and structural features transfer noticeably differently while specific classes of functional features have their roles faithfully mapped. Overall, our findings illustrate similarities and differences in the linear representation spaces of small and large models and demonstrate a method for improving the training efficiency of SAEs.
On Linear Representations and Pretraining Data Frequency in Language Models
Apr 16, 2025Pretraining data has a direct impact on the behaviors and quality of language models (LMs), but we only understand the most basic principles of this relationship. While most work focuses on pretraining data's effect on downstream task behavior, we investigate its relationship to LM representations. Previous work has discovered that, in language models, some concepts are encoded `linearly' in the representations, but what factors cause these representations to form? We study the connection between pretraining data frequency and models' linear representations of factual relations. We find evidence that the formation of linear representations is strongly connected to pretraining term frequencies; specifically for subject-relation-object fact triplets, both subject-object co-occurrence frequency and in-context learning accuracy for the relation are highly correlated with linear representations. This is the case across all phases of pretraining. In OLMo-7B and GPT-J, we discover that a linear representation consistently (but not exclusively) forms when the subjects and objects within a relation co-occur at least 1k and 2k times, respectively, regardless of when these occurrences happen during pretraining. Finally, we train a regression model on measurements of linear representation quality in fully-trained LMs that can predict how often a term was seen in pretraining. Our model achieves low error even on inputs from a different model with a different pretraining dataset, providing a new method for estimating properties of the otherwise-unknown training data of closed-data models. We conclude that the strength of linear representations in LMs contains signal about the models' pretraining corpora that may provide new avenues for controlling and improving model behavior: particularly, manipulating the models' training data to meet specific frequency thresholds.
$100K or 100 Days: Trade-offs when Pre-Training with Academic Resources
Oct 30, 2024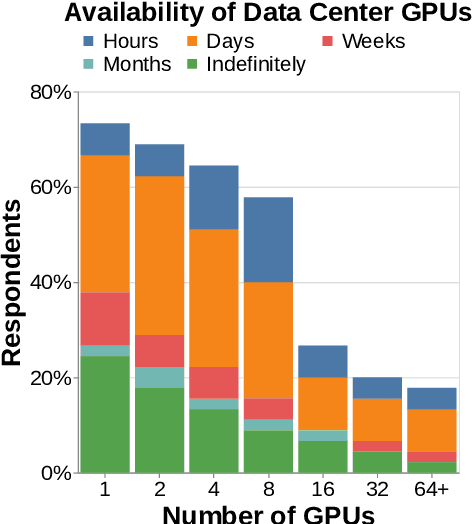
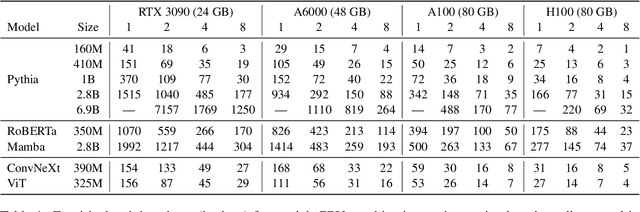
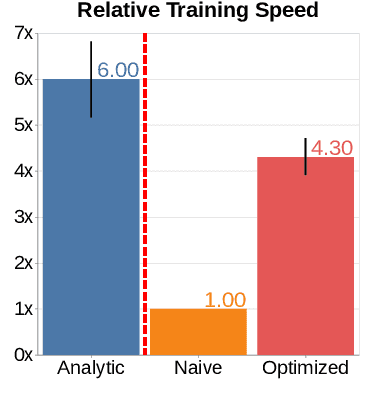
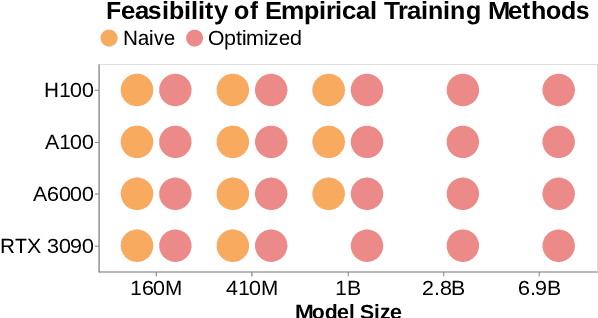
Pre-training is notoriously compute-intensive and academic researchers are notoriously under-resourced. It is, therefore, commonly assumed that academics can't pre-train models. In this paper, we seek to clarify this assumption. We first survey academic researchers to learn about their available compute and then empirically measure the time to replicate models on such resources. We introduce a benchmark to measure the time to pre-train models on given GPUs and also identify ideal settings for maximizing training speed. We run our benchmark on a range of models and academic GPUs, spending 2,000 GPU-hours on our experiments. Our results reveal a brighter picture for academic pre-training: for example, although Pythia-1B was originally trained on 64 GPUs for 3 days, we find it is also possible to replicate this model (with the same hyper-parameters) in 3x fewer GPU-days: i.e. on 4 GPUs in 18 days. We conclude with a cost-benefit analysis to help clarify the trade-offs between price and pre-training time. We believe our benchmark will help academic researchers conduct experiments that require training larger models on more data. We fully release our codebase at: https://github.com/apoorvkh/academic-pretraining.
Talking Heads: Understanding Inter-layer Communication in Transformer Language Models
Jun 13, 2024


Although it is known that transformer language models (LMs) pass features from early layers to later layers, it is not well understood how this information is represented and routed by the model. By analyzing particular mechanism LMs use to accomplish this, we find that it is also used to recall items from a list, and show that this mechanism can explain an otherwise arbitrary-seeming sensitivity of the model to the order of items in the prompt. Specifically, we find that models write into low-rank subspaces of the residual stream to represent features which are then read out by specific later layers, forming low-rank communication channels between layers. By decomposing attention head weight matrices with the Singular Value Decomposition (SVD), we find that previously described interactions between heads separated by one or more layers can be predicted via analysis of their weight matrices. We show that it is possible to manipulate the internal model representations as well as edit model weights based on the mechanism we discover in order to significantly improve performance on our synthetic Laundry List task, which requires recall from a list, often improving task accuracy by over 20%. Our analysis reveals a surprisingly intricate interpretable structure learned from language model pretraining, and helps us understand why sophisticated LMs sometimes fail in simple domains, facilitating future analysis of more complex behaviors.
Dual Process Learning: Controlling Use of In-Context vs. In-Weights Strategies with Weight Forgetting
May 28, 2024



Language models have the ability to perform in-context learning (ICL), allowing them to flexibly adapt their behavior based on context. This contrasts with in-weights learning, where information is statically encoded in model parameters from iterated observations of the data. Despite this apparent ability to learn in-context, language models are known to struggle when faced with unseen or rarely seen tokens. Hence, we study $\textbf{structural in-context learning}$, which we define as the ability of a model to execute in-context learning on arbitrary tokens -- so called because the model must generalize on the basis of e.g. sentence structure or task structure, rather than semantic content encoded in token embeddings. An ideal model would be able to do both: flexibly deploy in-weights operations (in order to robustly accommodate ambiguous or unknown contexts using encoded semantic information) and structural in-context operations (in order to accommodate novel tokens). We study structural in-context algorithms in a simple part-of-speech setting using both practical and toy models. We find that active forgetting, a technique that was recently introduced to help models generalize to new languages, forces models to adopt structural in-context learning solutions. Finally, we introduce $\textbf{temporary forgetting}$, a straightforward extension of active forgetting that enables one to control how much a model relies on in-weights vs. in-context solutions. Importantly, temporary forgetting allows us to induce a $\textit{dual process strategy}$ where in-context and in-weights solutions coexist within a single model.
Axiomatic Causal Interventions for Reverse Engineering Relevance Computation in Neural Retrieval Models
May 03, 2024



Neural models have demonstrated remarkable performance across diverse ranking tasks. However, the processes and internal mechanisms along which they determine relevance are still largely unknown. Existing approaches for analyzing neural ranker behavior with respect to IR properties rely either on assessing overall model behavior or employing probing methods that may offer an incomplete understanding of causal mechanisms. To provide a more granular understanding of internal model decision-making processes, we propose the use of causal interventions to reverse engineer neural rankers, and demonstrate how mechanistic interpretability methods can be used to isolate components satisfying term-frequency axioms within a ranking model. We identify a group of attention heads that detect duplicate tokens in earlier layers of the model, then communicate with downstream heads to compute overall document relevance. More generally, we propose that this style of mechanistic analysis opens up avenues for reverse engineering the processes neural retrieval models use to compute relevance. This work aims to initiate granular interpretability efforts that will not only benefit retrieval model development and training, but ultimately ensure safer deployment of these models.
Transformer Mechanisms Mimic Frontostriatal Gating Operations When Trained on Human Working Memory Tasks
Feb 13, 2024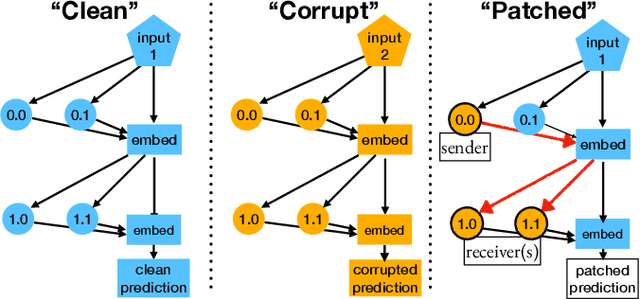
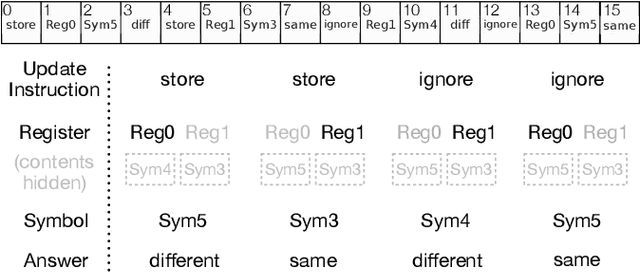
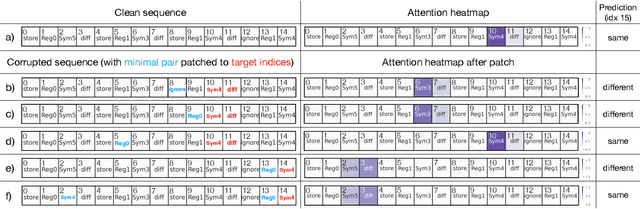
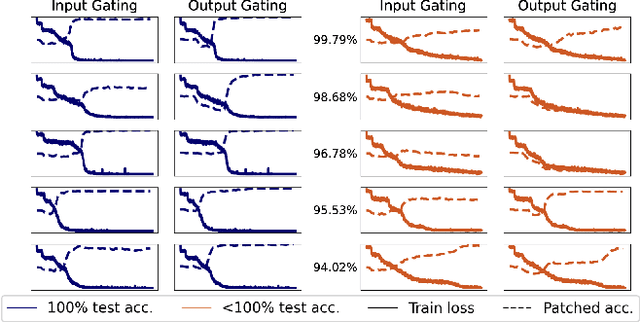
Models based on the Transformer neural network architecture have seen success on a wide variety of tasks that appear to require complex "cognitive branching" -- or the ability to maintain pursuit of one goal while accomplishing others. In cognitive neuroscience, success on such tasks is thought to rely on sophisticated frontostriatal mechanisms for selective \textit{gating}, which enable role-addressable updating -- and later readout -- of information to and from distinct "addresses" of memory, in the form of clusters of neurons. However, Transformer models have no such mechanisms intentionally built-in. It is thus an open question how Transformers solve such tasks, and whether the mechanisms that emerge to help them to do so bear any resemblance to the gating mechanisms in the human brain. In this work, we analyze the mechanisms that emerge within a vanilla attention-only Transformer trained on a simple sequence modeling task inspired by a task explicitly designed to study working memory gating in computational cognitive neuroscience. We find that, as a result of training, the self-attention mechanism within the Transformer specializes in a way that mirrors the input and output gating mechanisms which were explicitly incorporated into earlier, more biologically-inspired architectures. These results suggest opportunities for future research on computational similarities between modern AI architectures and models of the human brain.
Characterizing Mechanisms for Factual Recall in Language Models
Oct 24, 2023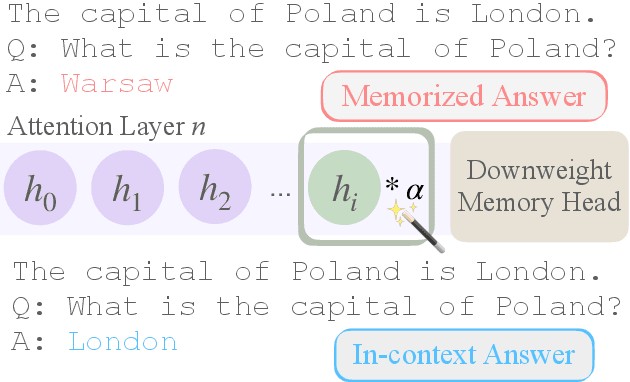

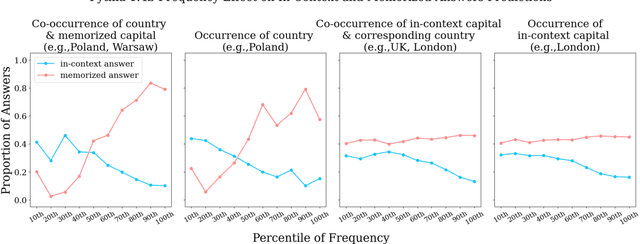
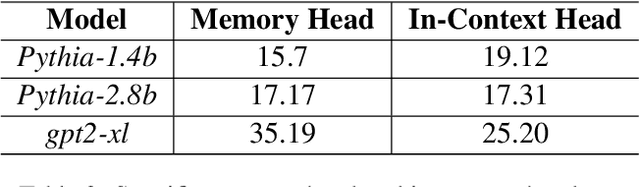
Language Models (LMs) often must integrate facts they memorized in pretraining with new information that appears in a given context. These two sources can disagree, causing competition within the model, and it is unclear how an LM will resolve the conflict. On a dataset that queries for knowledge of world capitals, we investigate both distributional and mechanistic determinants of LM behavior in such situations. Specifically, we measure the proportion of the time an LM will use a counterfactual prefix (e.g., "The capital of Poland is London") to overwrite what it learned in pretraining ("Warsaw"). On Pythia and GPT2, the training frequency of both the query country ("Poland") and the in-context city ("London") highly affect the models' likelihood of using the counterfactual. We then use head attribution to identify individual attention heads that either promote the memorized answer or the in-context answer in the logits. By scaling up or down the value vector of these heads, we can control the likelihood of using the in-context answer on new data. This method can increase the rate of generating the in-context answer to 88\% of the time simply by scaling a single head at runtime. Our work contributes to a body of evidence showing that we can often localize model behaviors to specific components and provides a proof of concept for how future methods might control model behavior dynamically at runtime.
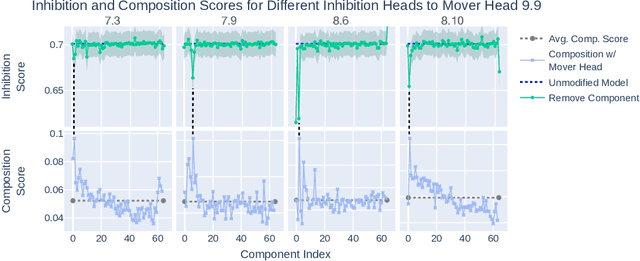
Circuit Component Reuse Across Tasks in Transformer Language Models
Oct 12, 2023



Recent work in mechanistic interpretability has shown that behaviors in language models can be successfully reverse-engineered through circuit analysis. A common criticism, however, is that each circuit is task-specific, and thus such analysis cannot contribute to understanding the models at a higher level. In this work, we present evidence that insights (both low-level findings about specific heads and higher-level findings about general algorithms) can indeed generalize across tasks. Specifically, we study the circuit discovered in Wang et al. (2022) for the Indirect Object Identification (IOI) task and 1.) show that it reproduces on a larger GPT2 model, and 2.) that it is mostly reused to solve a seemingly different task: Colored Objects (Ippolito & Callison-Burch, 2023). We provide evidence that the process underlying both tasks is functionally very similar, and contains about a 78% overlap in in-circuit attention heads. We further present a proof-of-concept intervention experiment, in which we adjust four attention heads in middle layers in order to 'repair' the Colored Objects circuit and make it behave like the IOI circuit. In doing so, we boost accuracy from 49.6% to 93.7% on the Colored Objects task and explain most sources of error. The intervention affects downstream attention heads in specific ways predicted by their interactions in the IOI circuit, indicating that this subcircuit behavior is invariant to the different task inputs. Overall, our results provide evidence that it may yet be possible to explain large language models' behavior in terms of a relatively small number of interpretable task-general algorithmic building blocks and computational components.