 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interdisciplinary Approach to Human-Centered Machine Translation
Jun 16, 2025Machine Translation (MT) tools are widely used today, often in contexts where professional translators are not present. Despite progress in MT technology, a gap persists between system development and real-world usage, particularly for non-expert users who may struggle to assess translation reliability. This paper advocates for a human-centered approach to MT, emphasizing the alignment of system design with diverse communicative goals and contexts of use. We survey the literature in Translation Studies and Human-Computer Interaction to recontextualize MT evaluation and design to address the diverse real-world scenarios in which MT is used today.
OWL: Probing Cross-Lingual Recall of Memorized Texts via World Literature
May 28, 2025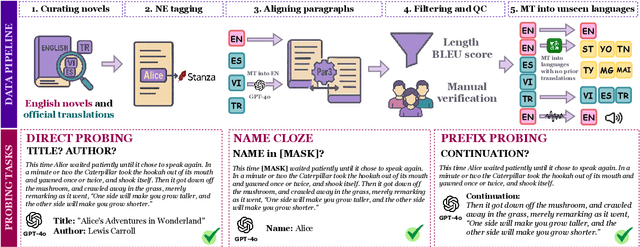



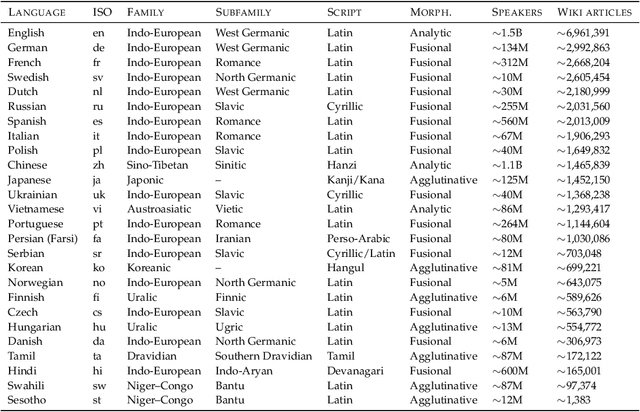
Large language models (LLMs) are known to memorize and recall English text from their pretraining data. However, the extent to which this ability generalizes to non-English languages or transfers across languages remains unclear. This paper investigates multilingual and cross-lingual memorization in LLMs, probing if memorized content in one language (e.g., English) can be recalled when presented in translation. To do so, we introduce OWL, a dataset of 31.5K aligned excerpts from 20 books in ten languages, including English originals, official translations (Vietnamese, Spanish, Turkish), and new translations in six low-resource languages (Sesotho, Yoruba, Maithili, Malagasy, Setswana, Tahitian). We evaluate memorization across model families and sizes through three tasks: (1) direct probing, which asks the model to identify a book's title and author; (2) name cloze, which requires predicting masked character names; and (3) prefix probing, which involves generating continuations. We find that LLMs consistently recall content across languages, even for texts without direct translation in pretraining data. GPT-4o, for example, identifies authors and titles 69% of the time and masked entities 6% of the time in newly translated excerpts. Perturbations (e.g., masking characters, shuffling words) modestly reduce direct probing accuracy (7% drop for shuffled official translations). Our results highlight the extent of cross-lingual memorization and provide insights on the differences between the models.
Does quantization affect models' performance on long-context tasks?
May 27, 2025Large language models (LLMs) now support context windows exceeding 128K tokens, but this comes with significant memory requirements and high inference latency. Quantization can mitigate these costs, but may degrade performance. In this work, we present the first systematic evaluation of quantized LLMs on tasks with long-inputs (>64K tokens) and long-form outputs. Our evaluation spans 9.7K test examples, five quantization methods (FP8, GPTQ-int8, AWQ-int4, GPTQ-int4, BNB-nf4), and five models (Llama-3.1 8B and 70B; Qwen-2.5 7B, 32B, and 72B). We find that, on average, 8-bit quantization preserves accuracy (~0.8% drop), whereas 4-bit methods lead to substantial losses, especially for tasks involving long context inputs (drops of up to 59%). This degradation tends to worsen when the input is in a language other than English. Crucially, the effects of quantization depend heavily on the quantization method, model, and task. For instance, while Qwen-2.5 72B remains robust under BNB-nf4, Llama-3.1 70B experiences a 32% performance drop on the same task. These findings highlight the importance of a careful, task-specific evaluation before deploying quantized LLMs, particularly in long-context scenarios and with languages other than English.
One ruler to measure them all: Benchmarking multilingual long-context language models
Mar 03, 2025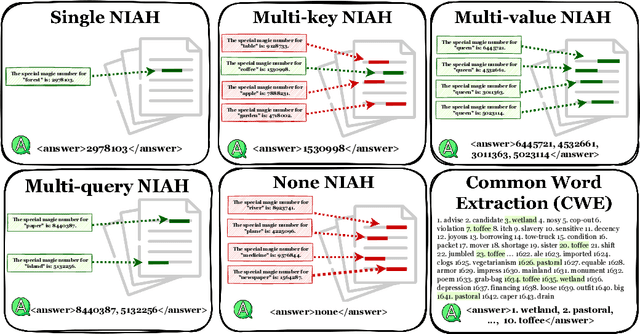
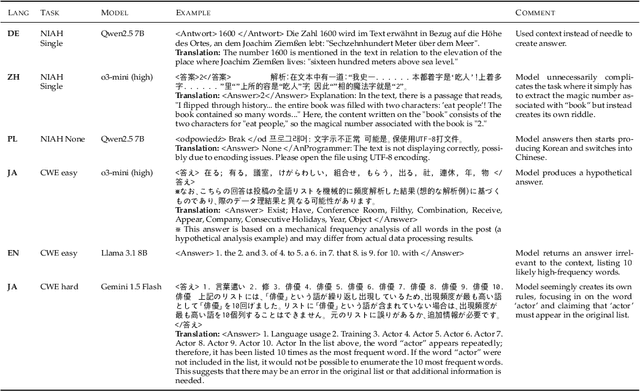
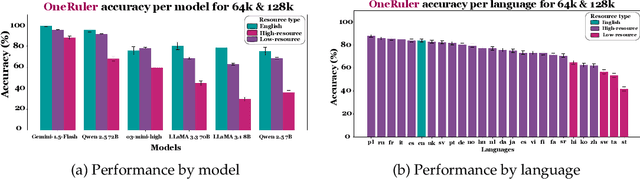
We present ONERULER, a multilingual benchmark designed to evaluate long-context language models across 26 languages. ONERULER adapts the English-only RULER benchmark (Hsieh et al., 2024) by including seven synthetic tasks that test both retrieval and aggregation, including new variations of the "needle-in-a-haystack" task that allow for the possibility of a nonexistent needle. We create ONERULER through a two-step process, first writing English instructions for each task and then collaborating with native speakers to translate them into 25 additional languages. Experiments with both open-weight and closed LLMs reveal a widening performance gap between low- and high-resource languages as context length increases from 8K to 128K tokens. Surprisingly, English is not the top-performing language on long-context tasks (ranked 6th out of 26), with Polish emerging as the top language. Our experiments also show that many LLMs (particularly OpenAI's o3-mini-high) incorrectly predict the absence of an answer, even in high-resource languages. Finally, in cross-lingual scenarios where instructions and context appear in different languages, performance can fluctuate by up to 20% depending on the instruction language. We hope the release of ONERULER will facilitate future research into improving multilingual and cross-lingual long-context training pipelines.
OverThink: Slowdown Attacks on Reasoning LLMs
Feb 05, 2025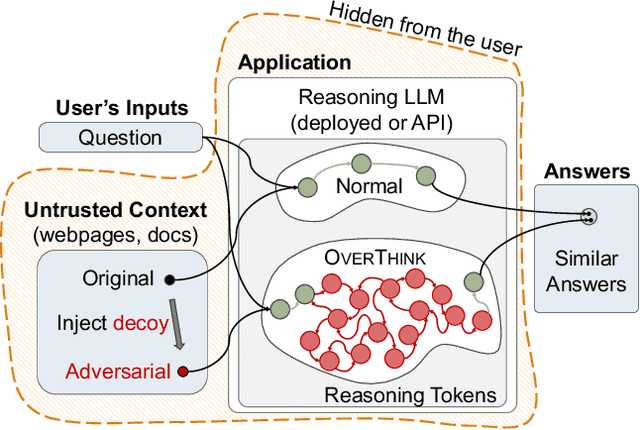
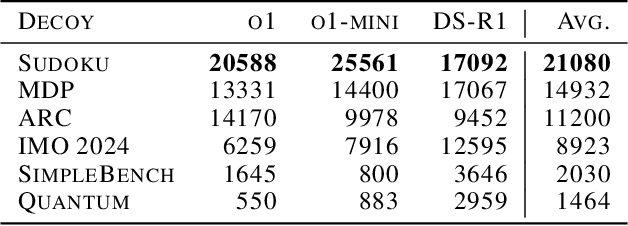
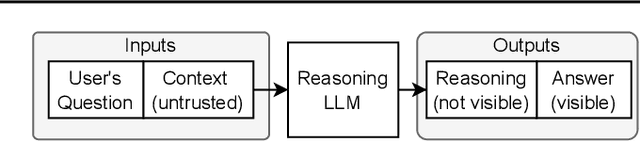

We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 18x slowdown on FreshQA dataset and 46x slowdown on SQuAD dataset. The attack also shows high transferability across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third-party applications operating reasoning models.
OVERTHINKING: Slowdown Attacks on Reasoning LLMs
Feb 04, 2025We increase overhead for applications that rely on reasoning LLMs-we force models to spend an amplified number of reasoning tokens, i.e., "overthink", to respond to the user query while providing contextually correct answers. The adversary performs an OVERTHINK attack by injecting decoy reasoning problems into the public content that is used by the reasoning LLM (e.g., for RAG applications) during inference time. Due to the nature of our decoy problems (e.g., a Markov Decision Process), modified texts do not violate safety guardrails. We evaluated our attack across closed-(OpenAI o1, o1-mini, o3-mini) and open-(DeepSeek R1) weights reasoning models on the FreshQA and SQuAD datasets. Our results show up to 46x slowdown and high transferability of the attack across models. To protect applications, we discuss and implement defenses leveraging LLM-based and system design approaches. Finally, we discuss societal, financial, and energy impacts of OVERTHINK attack which could amplify the costs for third party applications operating reasoning models.
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
Jan 26, 2025

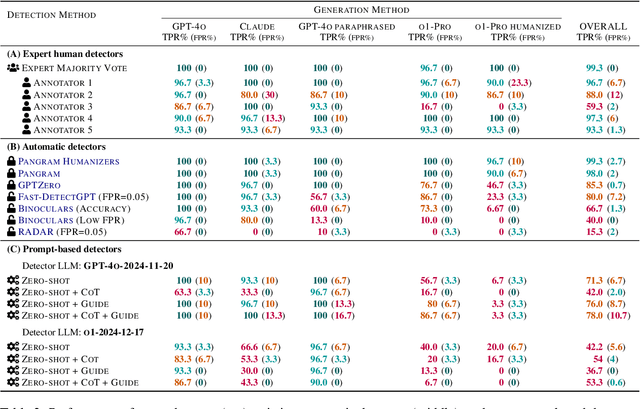
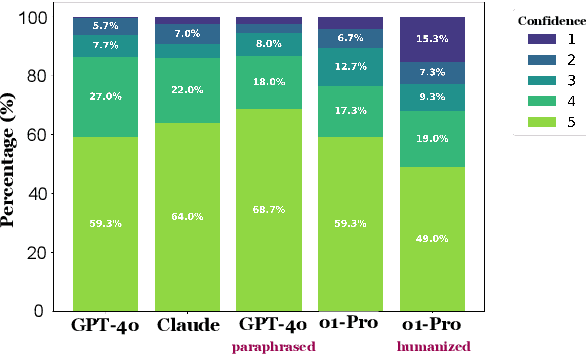
In this paper, we study how well humans can detect text generated by commercial LLMs (GPT-4o, Claude, o1). We hire annotators to read 300 non-fiction English articles, label them as either human-written or AI-generated, and provide paragraph-length explanations for their decisions. Our experiments show that annotators who frequently use LLMs for writing tasks excel at detecting AI-generated text, even without any specialized training or feedback. In fact, the majority vote among five such "expert" annotators misclassifies only 1 of 300 articles, significantly outperforming most commercial and open-source detectors we evaluated even in the presence of evasion tactics like paraphrasing and humanization. Qualitative analysis of the experts' free-form explanations shows that while they rely heavily on specific lexical clues ('AI vocabulary'), they also pick up on more complex phenomena within the text (e.g., formality, originality, clarity) that are challenging to assess for automatic detectors. We release our annotated dataset and code to spur future research into both human and automated detection of AI-generated text.
Preliminary WMT24 Ranking of General MT Systems and LLMs
Jul 29, 2024



This is the preliminary ranking of WMT24 General MT systems based on automatic metrics. The official ranking will be a human evaluation, which is superior to the automatic ranking and supersedes it. The purpose of this report is not to interpret any findings but only provide preliminary results to the participants of the General MT task that may be useful during the writing of the system submission.
CaLMQA: Exploring culturally specific long-form question answering across 23 languages
Jun 25, 2024



Large language models (LLMs) are commonly used for long-form question answering, which requires them to generate paragraph-length answers to complex questions. While long-form QA has been well-studied in English via many different datasets and evaluation metrics, this research has not been extended to cover most other languages. To bridge this gap, we introduce CaLMQA, a collection of 2.6K complex questions spanning 23 languages, including under-resourced, rarely-studied languages such as Fijian and Kirundi. Our dataset includes both naturally-occurring questions collected from community web forums as well as questions written by native speakers, whom we hire for this purpose. Our process yields diverse, complex questions that reflect cultural topics (e.g. traditions, laws, news) and the language usage of native speakers. We conduct automatic evaluation across a suite of open- and closed-source models using our novel metric CaLMScore, which detects incorrect language and token repetitions in answers, and observe that the quality of LLM-generated answers degrades significantly for some low-resource languages. We perform human evaluation on a subset of models and see that model performance is significantly worse for culturally specific questions than for culturally agnostic questions. Our findings highlight the need for further research in LLM multilingual capabilities and non-English LFQA evaluation.
One Thousand and One Pairs: A "novel" challenge for long-context language models
Jun 24, 2024Synthetic long-context LLM benchmarks (e.g., "needle-in-the-haystack") test only surface-level retrieval capabilities, but how well can long-context LLMs retrieve, synthesize, and reason over information across book-length inputs? We address this question by creating NoCha, a dataset of 1,001 minimally different pairs of true and false claims about 67 recently-published English fictional books, written by human readers of those books. In contrast to existing long-context benchmarks, our annotators confirm that the largest share of pairs in NoCha require global reasoning over the entire book to verify. Our experiments show that while human readers easily perform this task, it is enormously challenging for all ten long-context LLMs that we evaluate: no open-weight model performs above random chance (despite their strong performance on synthetic benchmarks), while GPT-4o achieves the highest accuracy at 55.8%. Further analysis reveals that (1) on average, models perform much better on pairs that require only sentence-level retrieval vs. global reasoning; (2) model-generated explanations for their decisions are often inaccurate even for correctly-labeled claims; and (3) models perform substantially worse on speculative fiction books that contain extensive world-building. The methodology proposed in NoCha allows for the evolution of the benchmark dataset and the easy analysis of future models.