 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Critical Batch Size Revisited: A Simple Empirical Approach to Large-Batch Language Model Training
May 29, 2025The right batch size is important when training language models at scale: a large batch size is necessary for fast training, but a batch size that is too large will harm token efficiency. To navigate this tradeoff, McCandlish et al. (2018) suggest that a critical batch size (CBS), below which training will not substantially degrade loss, can be estimated based on the gradient noise scale during training. While their method has been adopted in practice, e.g., when training GPT-3, strong assumptions are required to justify gradient noise as a proxy for the CBS, which makes it unclear whether their approach should be trusted in practice, limiting its applicability. In this paper, we introduce a simple, empirical approach to directly measure the CBS and show how the CBS evolves over training. Applying our approach to the OLMo models, we find that CBS is near 0 at initialization, increases rapidly at first, and then plateaus as training progresses. Furthermore, we find that this trend holds across different model sizes (1B and 7B), suggesting CBS from small training runs can inform larger-scale training runs. Our findings about how the CBS changes over training motivate batch size warmup as a natural way to reliably train language models at large batch size: start the batch size small and increase it as the CBS grows. To validate this claim, we use batch size warmup to train OLMo 1B to slightly better loss than the original training run with 43% fewer gradient steps. This shows how our framework can be applied to reliably train language models at larger batch sizes, increasing data parallelism without compromising performance.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
CaLMQA: Exploring culturally specific long-form question answering across 23 languages
Jun 25, 2024



Large language models (LLMs) are commonly used for long-form question answering, which requires them to generate paragraph-length answers to complex questions. While long-form QA has been well-studied in English via many different datasets and evaluation metrics, this research has not been extended to cover most other languages. To bridge this gap, we introduce CaLMQA, a collection of 2.6K complex questions spanning 23 languages, including under-resourced, rarely-studied languages such as Fijian and Kirundi. Our dataset includes both naturally-occurring questions collected from community web forums as well as questions written by native speakers, whom we hire for this purpose. Our process yields diverse, complex questions that reflect cultural topics (e.g. traditions, laws, news) and the language usage of native speakers. We conduct automatic evaluation across a suite of open- and closed-source models using our novel metric CaLMScore, which detects incorrect language and token repetitions in answers, and observe that the quality of LLM-generated answers degrades significantly for some low-resource languages. We perform human evaluation on a subset of models and see that model performance is significantly worse for culturally specific questions than for culturally agnostic questions. Our findings highlight the need for further research in LLM multilingual capabilities and non-English LFQA evaluation.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024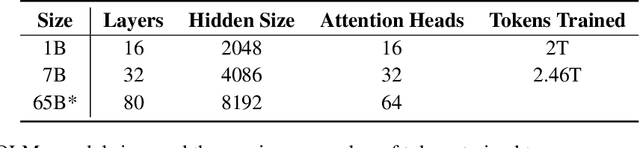
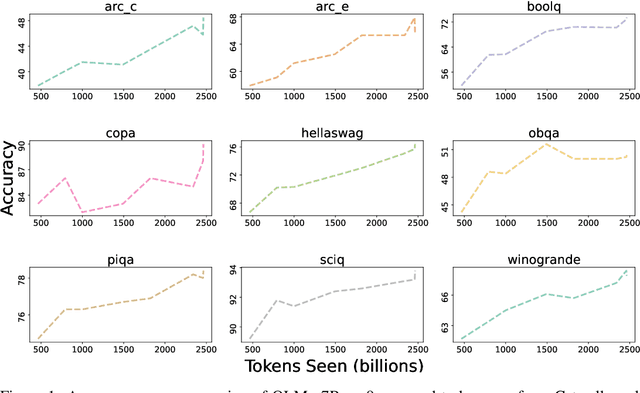
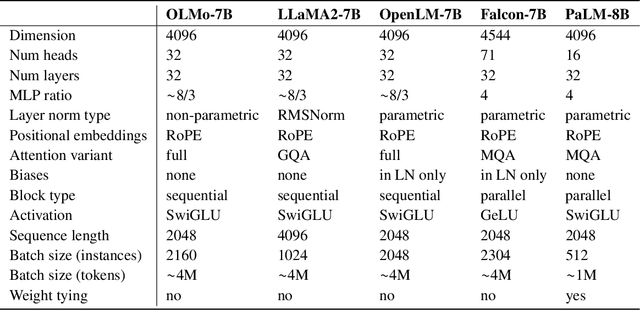
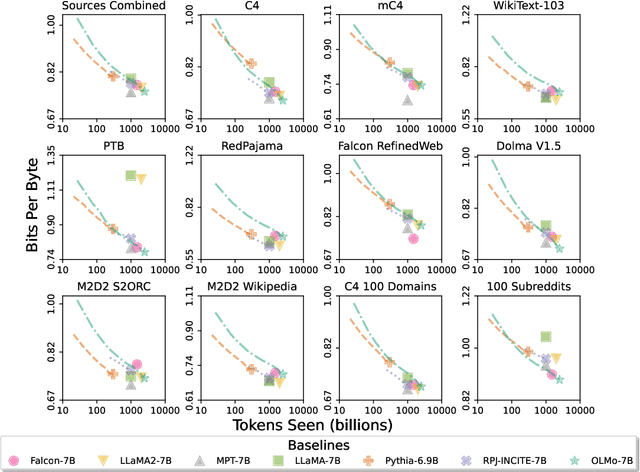
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.