 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation
Aug 18, 2025Developing large language models is expensive and involves making decisions with small experiments, typically by evaluating on large, multi-task evaluation suites. In this work, we analyze specific properties which make a benchmark more reliable for such decisions, and interventions to design higher-quality evaluation benchmarks. We introduce two key metrics that show differences in current benchmarks: signal, a benchmark's ability to separate better models from worse models, and noise, a benchmark's sensitivity to random variability between training steps. We demonstrate that benchmarks with a better signal-to-noise ratio are more reliable when making decisions at small scale, and those with less noise have lower scaling law prediction error. These results suggest that improving signal or noise will lead to more useful benchmarks, so we introduce three interventions designed to directly affect signal or noise. For example, we propose that switching to a metric that has better signal and noise (e.g., perplexity rather than accuracy) leads to better reliability and improved scaling law error. We also find that filtering noisy subtasks, to improve an aggregate signal-to-noise ratio, leads to more reliable multi-task evaluations. We also find that averaging the output of a model's intermediate checkpoints to reduce noise leads to consistent improvements. We conclude by recommending that those creating new benchmarks, or selecting which existing benchmarks to use, aim for high signal and low noise. We use 30 benchmarks for these experiments, and 375 open-weight language models from 60M to 32B parameters, resulting in a new, publicly available dataset of 900K evaluation benchmark results, totaling 200M instances.
2 OLMo 2 Furious
Dec 31, 2024



We present OLMo 2, the next generation of our fully open language models. OLMo 2 includes dense autoregressive models with improved architecture and training recipe, pretraining data mixtures, and instruction tuning recipes. Our modified model architecture and training recipe achieve both better training stability and improved per-token efficiency. Our updated pretraining data mixture introduces a new, specialized data mix called Dolmino Mix 1124, which significantly improves model capabilities across many downstream task benchmarks when introduced via late-stage curriculum training (i.e. specialized data during the annealing phase of pretraining). Finally, we incorporate best practices from T\"ulu 3 to develop OLMo 2-Instruct, focusing on permissive data and extending our final-stage reinforcement learning with verifiable rewards (RLVR). Our OLMo 2 base models sit at the Pareto frontier of performance to compute, often matching or outperforming open-weight only models like Llama 3.1 and Qwen 2.5 while using fewer FLOPs and with fully transparent training data, code, and recipe. Our fully open OLMo 2-Instruct models are competitive with or surpassing open-weight only models of comparable size, including Qwen 2.5, Llama 3.1 and Gemma 2. We release all OLMo 2 artifacts openly -- models at 7B and 13B scales, both pretrained and post-trained, including their full training data, training code and recipes, training logs and thousands of intermediate checkpoints. The final instruction model is available on the Ai2 Playground as a free research demo.
TÜLU 3: Pushing Frontiers in Open Language Model Post-Training
Nov 22, 2024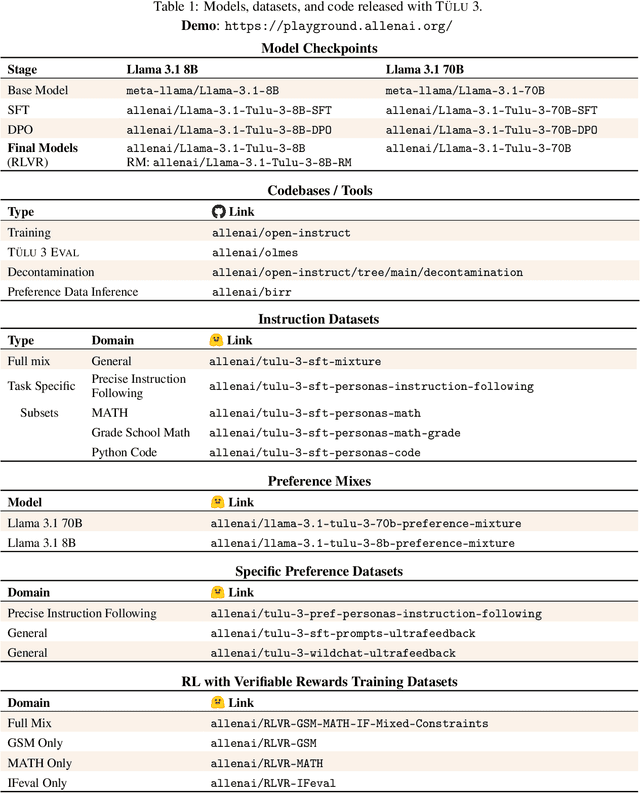



Language model post-training is applied to refine behaviors and unlock new skills across a wide range of recent language models, but open recipes for applying these techniques lag behind proprietary ones. The underlying training data and recipes for post-training are simultaneously the most important pieces of the puzzle and the portion with the least transparency. To bridge this gap, we introduce T\"ULU 3, a family of fully-open state-of-the-art post-trained models, alongside its data, code, and training recipes, serving as a comprehensive guide for modern post-training techniques. T\"ULU 3, which builds on Llama 3.1 base models, achieves results surpassing the instruct versions of Llama 3.1, Qwen 2.5, Mistral, and even closed models such as GPT-4o-mini and Claude 3.5-Haiku. The training algorithms for our models include supervised finetuning (SFT), Direct Preference Optimization (DPO), and a novel method we call Reinforcement Learning with Verifiable Rewards (RLVR). With T\"ULU 3, we introduce a multi-task evaluation scheme for post-training recipes with development and unseen evaluations, standard benchmark implementations, and substantial decontamination of existing open datasets on said benchmarks. We conclude with analysis and discussion of training methods that did not reliably improve performance. In addition to the T\"ULU 3 model weights and demo, we release the complete recipe -- including datasets for diverse core skills, a robust toolkit for data curation and evaluation, the training code and infrastructure, and, most importantly, a detailed report for reproducing and further adapting the T\"ULU 3 approach to more domains.
SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs
Oct 17, 2024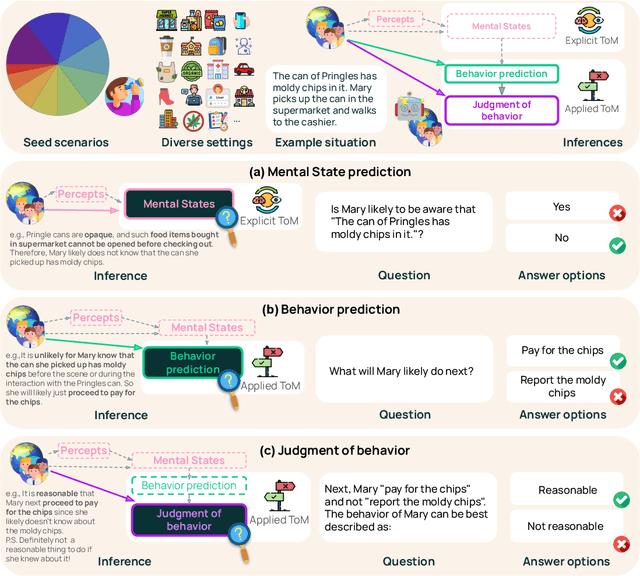

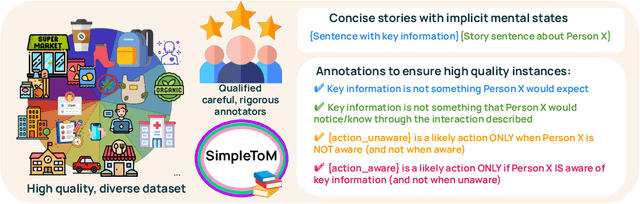
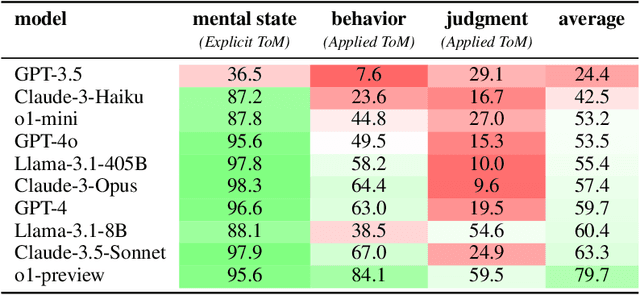
While prior work has explored whether large language models (LLMs) possess a "theory of mind" (ToM) - the ability to attribute mental states to oneself and others - there has been little work testing whether LLMs can implicitly apply such knowledge to predict behavior, or to judge whether an observed behavior is rational. Such skills are critical for appropriate interaction in social environments. We create a new dataset, SimpleTom, containing concise, diverse stories (e.g., "The can of Pringles has moldy chips in it. Mary picks up the can in the supermarket and walks to the cashier."), each with three questions that test different degrees of ToM reasoning, asking models to predict (a) mental state ("Is Mary aware of the mold?"), (b) behavior ("Will Mary pay for the chips or report the mold?"), and (c) judgment ("Mary paid for the chips. Was that reasonable?"). To our knowledge, SimpleToM is the first dataset to systematically explore downstream reasoning requiring knowledge of mental states in realistic scenarios. Our experimental results are intriguing: While most models can reliably predict mental state on our dataset (a), they often fail to correctly predict the behavior (b), and fare even worse at judging whether given behaviors are reasonable (c), despite being correctly aware of the protagonist's mental state should make such secondary predictions obvious. We further show that we can help models do better at (b) and (c) via interventions such as reminding the model of its earlier mental state answer and mental-state-specific chain-of-thought prompting, raising the action prediction accuracies (e.g., from 49.5% to 93.5% for GPT-4o) and judgment accuracies (e.g., from 15.3% to 94.7% in GPT-4o). While this shows that models can be coaxed to perform well, it requires task-specific interventions, and the natural model performances remain low, a cautionary tale for LLM deployment.
OLMoE: Open Mixture-of-Experts Language Models
Sep 03, 2024



We introduce OLMoE, a fully open, state-of-the-art language model leveraging sparse Mixture-of-Experts (MoE). OLMoE-1B-7B has 7 billion (B) parameters but uses only 1B per input token. We pretrain it on 5 trillion tokens and further adapt it to create OLMoE-1B-7B-Instruct. Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B. We present various experiments on MoE training, analyze routing in our model showing high specialization, and open-source all aspects of our work: model weights, training data, code, and logs.
OLMES: A Standard for Language Model Evaluations
Jun 12, 2024



Progress in AI is often demonstrated by new models claiming improved performance on tasks measuring model capabilities. Evaluating language models in particular is challenging, as small changes to how a model is evaluated on a task can lead to large changes in measured performance. There is no common standard setup, so different models are evaluated on the same tasks in different ways, leading to claims about which models perform best not being reproducible. We propose OLMES, a completely documented, practical, open standard for reproducible LLM evaluations. In developing this standard, we identify and review the varying factors in evaluation practices adopted by the community - such as details of prompt formatting, choice of in-context examples, probability normalizations, and task formulation. In particular, OLMES supports meaningful comparisons between smaller base models that require the unnatural "cloze" formulation of multiple-choice questions against larger models that can utilize the original formulation. OLMES includes well-considered recommendations guided by results from existing literature as well as new experiments investigating open questions.
WorldValuesBench: A Large-Scale Benchmark Dataset for Multi-Cultural Value Awareness of Language Models
Apr 25, 2024



The awareness of multi-cultural human values is critical to the ability of language models (LMs) to generate safe and personalized responses. However, this awareness of LMs has been insufficiently studied, since the computer science community lacks access to the large-scale real-world data about multi-cultural values. In this paper, we present WorldValuesBench, a globally diverse, large-scale benchmark dataset for the multi-cultural value prediction task, which requires a model to generate a rating response to a value question based on demographic contexts. Our dataset is derived from an influential social science project, World Values Survey (WVS), that has collected answers to hundreds of value questions (e.g., social, economic, ethical) from 94,728 participants worldwide. We have constructed more than 20 million examples of the type "(demographic attributes, value question) $\rightarrow$ answer" from the WVS responses. We perform a case study using our dataset and show that the task is challenging for strong open and closed-source models. On merely $11.1\%$, $25.0\%$, $72.2\%$, and $75.0\%$ of the questions, Alpaca-7B, Vicuna-7B-v1.5, Mixtral-8x7B-Instruct-v0.1, and GPT-3.5 Turbo can respectively achieve $<0.2$ Wasserstein 1-distance from the human normalized answer distributions. WorldValuesBench opens up new research avenues in studying limitations and opportunities in multi-cultural value awareness of LMs.
PROC2PDDL: Open-Domain Planning Representations from Texts
Feb 29, 2024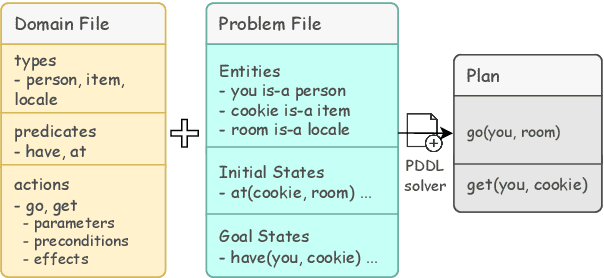
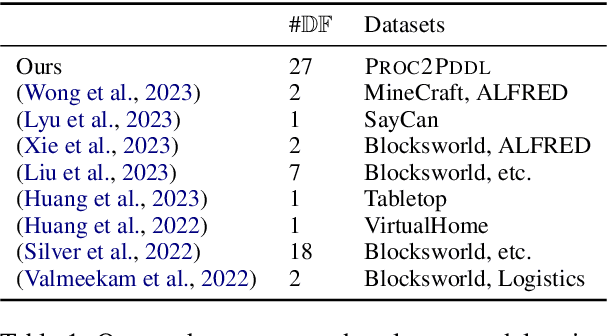

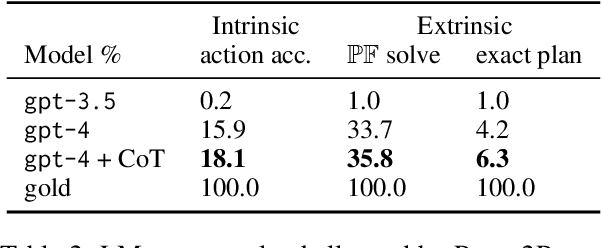
Planning in a text-based environment continues to be a major challenge for AI systems. Recent approaches have used language models to predict a planning domain definition (e.g., PDDL) but have only been evaluated in closed-domain simulated environments. To address this, we present Proc2PDDL , the first dataset containing open-domain procedural texts paired with expert-annotated PDDL representations. Using this dataset, we evaluate state-of-the-art models on defining the preconditions and effects of actions. We show that Proc2PDDL is highly challenging, with GPT-3.5's success rate close to 0% and GPT-4's around 35%. Our analysis shows both syntactic and semantic errors, indicating LMs' deficiency in both generating domain-specific prgorams and reasoning about events. We hope this analysis and dataset helps future progress towards integrating the best of LMs and formal planning.
OLMo: Accelerating the Science of Language Models
Feb 07, 2024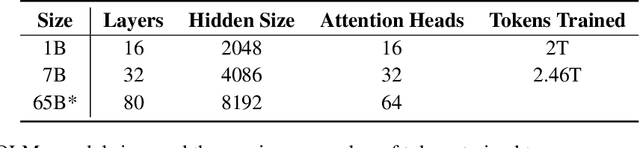
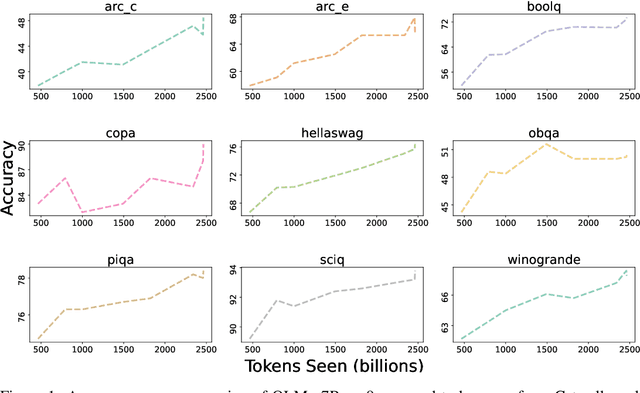
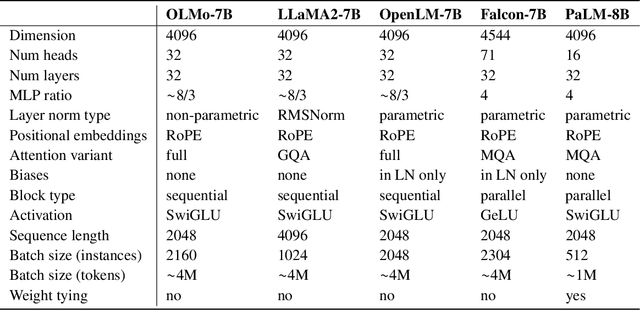
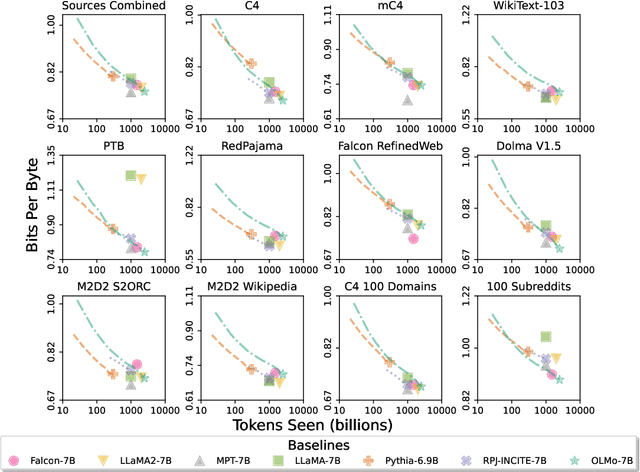
Language models (LMs) have become ubiquitous in both NLP research and in commercial product offerings. As their commercial importance has surged, the most powerful models have become closed off, gated behind proprietary interfaces, with important details of their training data, architectures, and development undisclosed. Given the importance of these details in scientifically studying these models, including their biases and potential risks, we believe it is essential for the research community to have access to powerful, truly open LMs. To this end, this technical report details the first release of OLMo, a state-of-the-art, truly Open Language Model and its framework to build and study the science of language modeling. Unlike most prior efforts that have only released model weights and inference code, we release OLMo and the whole framework, including training data and training and evaluation code. We hope this release will empower and strengthen the open research community and inspire a new wave of innovation.