 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
OLMoTrace: Tracing Language Model Outputs Back to Trillions of Training Tokens
Apr 09, 2025We present OLMoTrace, the first system that traces the outputs of language models back to their full, multi-trillion-token training data in real time. OLMoTrace finds and shows verbatim matches between segments of language model output and documents in the training text corpora. Powered by an extended version of infini-gram (Liu et al., 2024), our system returns tracing results within a few seconds. OLMoTrace can help users understand the behavior of language models through the lens of their training data. We showcase how it can be used to explore fact checking, hallucination, and the creativity of language models. OLMoTrace is publicly available and fully open-source.
CHIME: LLM-Assisted Hierarchical Organization of Scientific Studies for Literature Review Support
Jul 23, 2024



Literature review requires researchers to synthesize a large amount of information and is increasingly challenging as the scientific literature expands. In this work, we investigate the potential of LLMs for producing hierarchical organizations of scientific studies to assist researchers with literature review. We define hierarchical organizations as tree structures where nodes refer to topical categories and every node is linked to the studies assigned to that category. Our naive LLM-based pipeline for hierarchy generation from a set of studies produces promising yet imperfect hierarchies, motivating us to collect CHIME, an expert-curated dataset for this task focused on biomedicine. Given the challenging and time-consuming nature of building hierarchies from scratch, we use a human-in-the-loop process in which experts correct errors (both links between categories and study assignment) in LLM-generated hierarchies. CHIME contains 2,174 LLM-generated hierarchies covering 472 topics, and expert-corrected hierarchies for a subset of 100 topics. Expert corrections allow us to quantify LLM performance, and we find that while they are quite good at generating and organizing categories, their assignment of studies to categories could be improved. We attempt to train a corrector model with human feedback which improves study assignment by 12.6 F1 points. We release our dataset and models to encourage research on developing better assistive tools for literature review.
OLMES: A Standard for Language Model Evaluations
Jun 12, 2024



Progress in AI is often demonstrated by new models claiming improved performance on tasks measuring model capabilities. Evaluating language models in particular is challenging, as small changes to how a model is evaluated on a task can lead to large changes in measured performance. There is no common standard setup, so different models are evaluated on the same tasks in different ways, leading to claims about which models perform best not being reproducible. We propose OLMES, a completely documented, practical, open standard for reproducible LLM evaluations. In developing this standard, we identify and review the varying factors in evaluation practices adopted by the community - such as details of prompt formatting, choice of in-context examples, probability normalizations, and task formulation. In particular, OLMES supports meaningful comparisons between smaller base models that require the unnatural "cloze" formulation of multiple-choice questions against larger models that can utilize the original formulation. OLMES includes well-considered recommendations guided by results from existing literature as well as new experiments investigating open questions.
KIWI: A Dataset of Knowledge-Intensive Writing Instructions for Answering Research Questions
Mar 06, 2024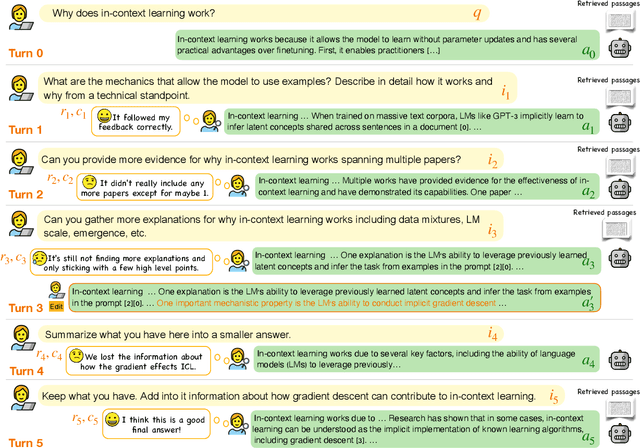

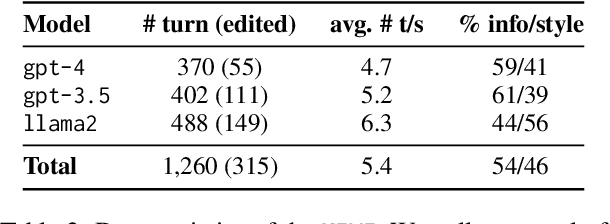
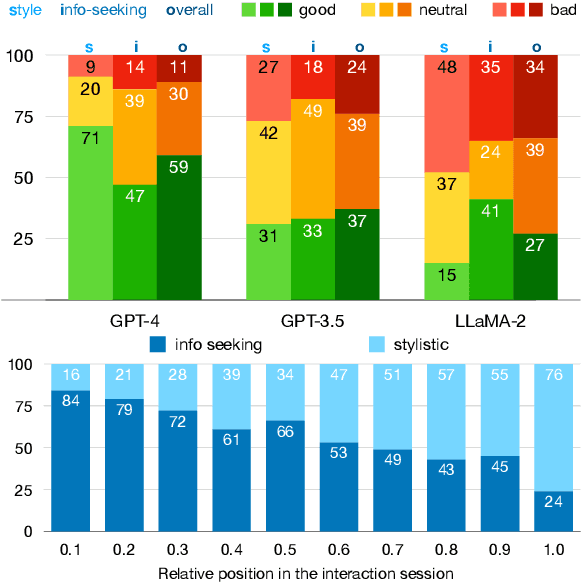
Large language models (LLMs) adapted to follow user instructions are now widely deployed as conversational agents. In this work, we examine one increasingly common instruction-following task: providing writing assistance to compose a long-form answer. To evaluate the capabilities of current LLMs on this task, we construct KIWI, a dataset of knowledge-intensive writing instructions in the scientific domain. Given a research question, an initial model-generated answer and a set of relevant papers, an expert annotator iteratively issues instructions for the model to revise and improve its answer. We collect 1,260 interaction turns from 234 interaction sessions with three state-of-the-art LLMs. Each turn includes a user instruction, a model response, and a human evaluation of the model response. Through a detailed analysis of the collected responses, we find that all models struggle to incorporate new information into an existing answer, and to perform precise and unambiguous edits. Further, we find that models struggle to judge whether their outputs successfully followed user instructions, with accuracy at least 10 points short of human agreement. Our findings indicate that KIWI will be a valuable resource to measure progress and improve LLMs' instruction-following capabilities for knowledge intensive writing tasks.
CARE: Extracting Experimental Findings From Clinical Literature
Nov 16, 2023Extracting fine-grained experimental findings from literature can provide massive utility for scientific applications. Prior work has focused on developing annotation schemas and datasets for limited aspects of this problem, leading to simpler information extraction datasets which do not capture the real-world complexity and nuance required for this task. Focusing on biomedicine, this work presents CARE (Clinical Aggregation-oriented Result Extraction) -- a new IE dataset for the task of extracting clinical findings. We develop a new annotation schema capturing fine-grained findings as n-ary relations between entities and attributes, which includes phenomena challenging for current IE systems such as discontinuous entity spans, nested relations, and variable arity n-ary relations. Using this schema, we collect extensive annotations for 700 abstracts from two sources: clinical trials and case reports. We also benchmark the performance of various state-of-the-art IE systems on our dataset, including extractive models and generative LLMs in fully supervised and limited data settings. Our results demonstrate the difficulty of our dataset -- even SOTA models such as GPT4 struggle, particularly on relation extraction. We release our annotation schema and CARE to encourage further research on extracting and aggregating scientific findings from literature.
ARIES: A Corpus of Scientific Paper Edits Made in Response to Peer Reviews
Jun 21, 2023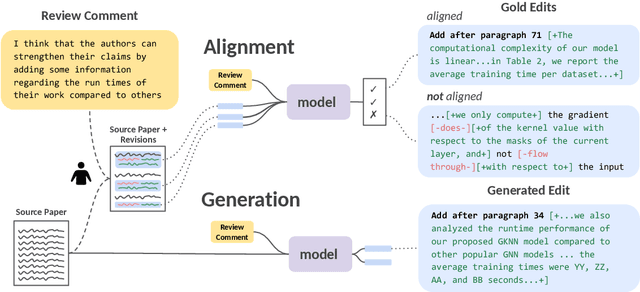
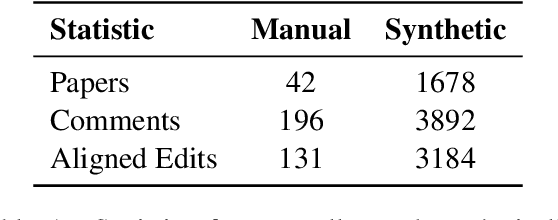

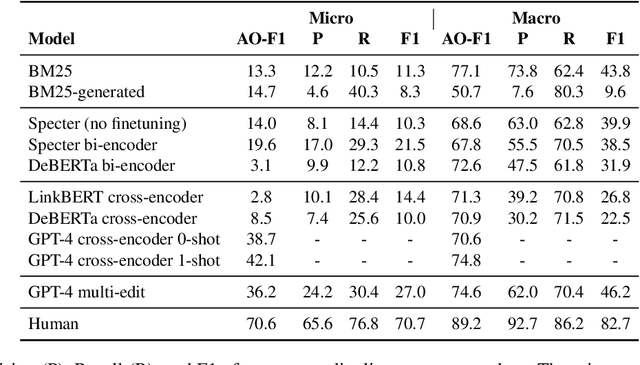
Revising scientific papers based on peer feedback is a challenging task that requires not only deep scientific knowledge and reasoning, but also the ability to recognize the implicit requests in high-level feedback and to choose the best of many possible ways to update the manuscript in response. We introduce this task for large language models and release ARIES, a dataset of review comments and their corresponding paper edits, to enable training and evaluating models. We study two versions of the task: comment-edit alignment and edit generation, and evaluate several baselines, including GPT-4. We find that models struggle even to identify the edits that correspond to a comment, especially in cases where the comment is phrased in an indirect way or where the edit addresses the spirit of a comment but not the precise request. When tasked with generating edits, GPT-4 often succeeds in addressing comments on a surface level, but it rigidly follows the wording of the feedback rather than the underlying intent, and includes fewer technical details than human-written edits. We hope that our formalization, dataset, and analysis will form a foundation for future work in this area.
S2abEL: A Dataset for Entity Linking from Scientific Tables
Apr 30, 2023



Entity linking (EL) is the task of linking a textual mention to its corresponding entry in a knowledge base, and is critical for many knowledge-intensive NLP applications. When applied to tables in scientific papers, EL is a step toward large-scale scientific knowledge bases that could enable advanced scientific question answering and analytics. We present the first dataset for EL in scientific tables. EL for scientific tables is especially challenging because scientific knowledge bases can be very incomplete, and disambiguating table mentions typically requires understanding the papers's tet in addition to the table. Our dataset, S2abEL, focuses on EL in machine learning results tables and includes hand-labeled cell types, attributed sources, and entity links from the PaperswithCode taxonomy for 8,429 cells from 732 tables. We introduce a neural baseline method designed for EL on scientific tables containing many out-of-knowledge-base mentions, and show that it significantly outperforms a state-of-the-art generic table EL method. The best baselines fall below human performance, and our analysis highlights avenues for improvement.
The Semantic Reader Project: Augmenting Scholarly Documents through AI-Powered Interactive Reading Interfaces
Mar 25, 2023



Scholarly publications are key to the transfer of knowledge from scholars to others. However, research papers are information-dense, and as the volume of the scientific literature grows, the need for new technology to support the reading process grows. In contrast to the process of finding papers, which has been transformed by Internet technology, the experience of reading research papers has changed little in decades. The PDF format for sharing research papers is widely used due to its portability, but it has significant downsides including: static content, poor accessibility for low-vision readers, and difficulty reading on mobile devices. This paper explores the question "Can recent advances in AI and HCI power intelligent, interactive, and accessible reading interfaces -- even for legacy PDFs?" We describe the Semantic Reader Project, a collaborative effort across multiple institutions to explore automatic creation of dynamic reading interfaces for research papers. Through this project, we've developed ten research prototype interfaces and conducted usability studies with more than 300 participants and real-world users showing improved reading experiences for scholars. We've also released a production reading interface for research papers that will incorporate the best features as they mature. We structure this paper around challenges scholars and the public face when reading research papers -- Discovery, Efficiency, Comprehension, Synthesis, and Accessibility -- and present an overview of our progress and remaining open challenges.
LongEval: Guidelines for Human Evaluation of Faithfulness in Long-form Summarization
Jan 30, 2023



While human evaluation remains best practice for accurately judging the faithfulness of automatically-generated summaries, few solutions exist to address the increased difficulty and workload when evaluating long-form summaries. Through a survey of 162 papers on long-form summarization, we first shed light on current human evaluation practices surrounding long-form summaries. We find that 73% of these papers do not perform any human evaluation on model-generated summaries, while other works face new difficulties that manifest when dealing with long documents (e.g., low inter-annotator agreement). Motivated by our survey, we present LongEval, a set of guidelines for human evaluation of faithfulness in long-form summaries that addresses the following challenges: (1) How can we achieve high inter-annotator agreement on faithfulness scores? (2) How can we minimize annotator workload while maintaining accurate faithfulness scores? and (3) Do humans benefit from automated alignment between summary and source snippets? We deploy LongEval in annotation studies on two long-form summarization datasets in different domains (SQuALITY and PubMed), and we find that switching to a finer granularity of judgment (e.g., clause-level) reduces inter-annotator variance in faithfulness scores (e.g., std-dev from 18.5 to 6.8). We also show that scores from a partial annotation of fine-grained units highly correlates with scores from a full annotation workload (0.89 Kendall's tau using 50% judgments). We release our human judgments, annotation templates, and our software as a Python library for future research.