 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmo Hybrid: From Theory to Practice and Back
Apr 07, 2026Recent work has demonstrated the potential of non-transformer language models, especially linear recurrent neural networks (RNNs) and hybrid models that mix recurrence and attention. Yet there is no consensus on whether the potential benefits of these new architectures justify the risk and effort of scaling them up. To address this, we provide evidence for the advantages of hybrid models over pure transformers on several fronts. First, theoretically, we show that hybrid models do not merely inherit the expressivity of transformers and linear RNNs, but can express tasks beyond both, such as code execution. Putting this theory to practice, we train Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B but with the sliding window layers replaced by Gated DeltaNet layers. We show that Olmo Hybrid outperforms Olmo 3 across standard pretraining and mid-training evaluations, demonstrating the benefit of hybrid models in a controlled, large-scale setting. We find that the hybrid model scales significantly more efficiently than the transformer, explaining its higher performance. However, its unclear why greater expressivity on specific formal problems should result in better scaling or superior performance on downstream tasks unrelated to those problems. To explain this apparent gap, we return to theory and argue why increased expressivity should translate to better scaling efficiency, completing the loop. Overall, our results suggest that hybrid models mixing attention and recurrent layers are a powerful extension to the language modeling paradigm: not merely to reduce memory during inference, but as a fundamental way to obtain more expressive models that scale better during pretraining.
TurnWise: The Gap between Single- and Multi-turn Language Model Capabilities
Mar 17, 2026Multi-turn conversations are a common and critical mode of language model interaction. However, current open training and evaluation data focus on single-turn settings, failing to capture the additional dimension of these longer interactions. To understand this multi-/single-turn gap, we first introduce a new benchmark, TurnWiseEval, for multi-turn capabilities that is directly comparable to single-turn chat evaluation. Our evaluation isolates multi-turn specific conversational ability through pairwise comparison to equivalent single-turn settings. We additionally introduce our synthetic multi-turn data pipeline TurnWiseData which allows the scalable generation of multi-turn training data. Our experiments with Olmo 3 show that training with multi-turn data is vital to achieving strong multi-turn chat performance, and that including as little as 10k multi-turn conversations during post-training can lead to a 12% improvement on TurnWiseEval.
Meta-Reinforcement Learning with Self-Reflection for Agentic Search
Mar 11, 2026This paper introduces MR-Search, an in-context meta reinforcement learning (RL) formulation for agentic search with self-reflection. Instead of optimizing a policy within a single independent episode with sparse rewards, MR-Search trains a policy that conditions on past episodes and adapts its search strategy across episodes. MR-Search learns to learn a search strategy with self-reflection, allowing search agents to improve in-context exploration at test-time. Specifically, MR-Search performs cross-episode exploration by generating explicit self-reflections after each episode and leveraging them as additional context to guide subsequent attempts, thereby promoting more effective exploration during test-time. We further introduce a multi-turn RL algorithm that estimates a dense relative advantage at the turn level, enabling fine-grained credit assignment on each episode. Empirical results across various benchmarks demonstrate the advantages of MR-Search over baselines based RL, showing strong generalization and relative improvements of 9.2% to 19.3% across eight benchmarks. Our code and data are available at https://github.com/tengxiao1/MR-Search.
Learning to Detect Language Model Training Data via Active Reconstruction
Feb 22, 2026Detecting LLM training data is generally framed as a membership inference attack (MIA) problem. However, conventional MIAs operate passively on fixed model weights, using log-likelihoods or text generations. In this work, we introduce \textbf{Active Data Reconstruction Attack} (ADRA), a family of MIA that actively induces a model to reconstruct a given text through training. We hypothesize that training data are \textit{more reconstructible} than non-members, and the difference in their reconstructibility can be exploited for membership inference. Motivated by findings that reinforcement learning (RL) sharpens behaviors already encoded in weights, we leverage on-policy RL to actively elicit data reconstruction by finetuning a policy initialized from the target model. To effectively use RL for MIA, we design reconstruction metrics and contrastive rewards. The resulting algorithms, \textsc{ADRA} and its adaptive variant \textsc{ADRA+}, improve both reconstruction and detection given a pool of candidate data. Experiments show that our methods consistently outperform existing MIAs in detecting pre-training, post-training, and distillation data, with an average improvement of 10.7\% over the previous runner-up. In particular, \MethodPlus~improves over Min-K\%++ by 18.8\% on BookMIA for pre-training detection and by 7.6\% on AIME for post-training detection.
Small Reward Models via Backward Inference
Feb 14, 2026Reward models (RMs) play a central role throughout the language model (LM) pipeline, particularly in non-verifiable domains. However, the dominant LLM-as-a-Judge paradigm relies on the strong reasoning capabilities of large models, while alternative approaches require reference responses or explicit rubrics, limiting flexibility and broader accessibility. In this work, we propose FLIP (FLipped Inference for Prompt reconstruction), a reference-free and rubric-free reward modeling approach that reformulates reward modeling through backward inference: inferring the instruction that would most plausibly produce a given response. The similarity between the inferred and the original instructions is then used as the reward signal. Evaluations across four domains using 13 small language models show that FLIP outperforms LLM-as-a-Judge baselines by an average of 79.6%. Moreover, FLIP substantially improves downstream performance in extrinsic evaluations under test-time scaling via parallel sampling and GRPO training. We further find that FLIP is particularly effective for longer outputs and robust to common forms of reward hacking. By explicitly exploiting the validation-generation gap, FLIP enables reliable reward modeling in downscaled regimes where judgment methods fail. Code available at https://github.com/yikee/FLIP.
Olmix: A Framework for Data Mixing Throughout LM Development
Feb 12, 2026Data mixing -- determining the ratios of data from different domains -- is a first-order concern for training language models (LMs). While existing mixing methods show promise, they fall short when applied during real-world LM development. We present Olmix, a framework that addresses two such challenges. First, the configuration space for developing a mixing method is not well understood -- design choices across existing methods lack justification or consensus and overlook practical issues like data constraints. We conduct a comprehensive empirical study of this space, identifying which design choices lead to a strong mixing method. Second, in practice, the domain set evolves throughout LM development as datasets are added, removed, partitioned, and revised -- a problem setting largely unaddressed by existing works, which assume fixed domains. We study how to efficiently recompute the mixture after the domain set is updated, leveraging information from past mixtures. We introduce mixture reuse, a mechanism that reuses existing ratios and recomputes ratios only for domains affected by the update. Over a sequence of five domain-set updates mirroring real-world LM development, mixture reuse matches the performance of fully recomputing the mix after each update with 74% less compute and improves over training without mixing by 11.6% on downstream tasks.
MentorCollab: Selective Large-to-Small Inference-Time Guidance for Efficient Reasoning
Feb 05, 2026Large reasoning models (LRMs) achieve strong performance by producing long chains of thought, but their inference costs are high and often generate redundant reasoning. Small language models (SLMs) are far more efficient, yet struggle on multi-step reasoning tasks. A natural idea is to let a large model guide a small one at inference time as a mentor, yet existing collaboration methods often promote imitation, resulting in verbose reasoning without consistent error correction. We propose MentorCollab, an inference-time collaboration method in which an LRM selectively and sparsely guides an SLM, rather than taking over generation. At randomly sampled token positions, we probe for divergences between the two models and use a lightweight verifier to decide whether the SLM should follow a short lookahead segment from its mentor or continue on its own. Across 15 SLM--LRM pairs and 3 domains (math reasoning, general knowledge, and commonsense reasoning), our method improves performance in 12 settings, with average gains of 3.0% and up to 8.0%, while adopting only having 18.4% tokens generated by the expensive mentor model on average. We find that short segments and selective probing are sufficient for effective collaboration. Our results show that selective inference-time guidance restores large-model reasoning ability without substantial inference overhead.
Olmo 3
Dec 15, 2025We introduce Olmo 3, a family of state-of-the-art, fully-open language models at the 7B and 32B parameter scales. Olmo 3 model construction targets long-context reasoning, function calling, coding, instruction following, general chat, and knowledge recall. This release includes the entire model flow, i.e., the full lifecycle of the family of models, including every stage, checkpoint, data point, and dependency used to build it. Our flagship model, Olmo 3 Think 32B, is the strongest fully-open thinking model released to-date.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025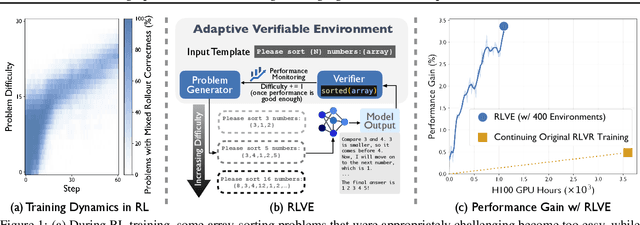

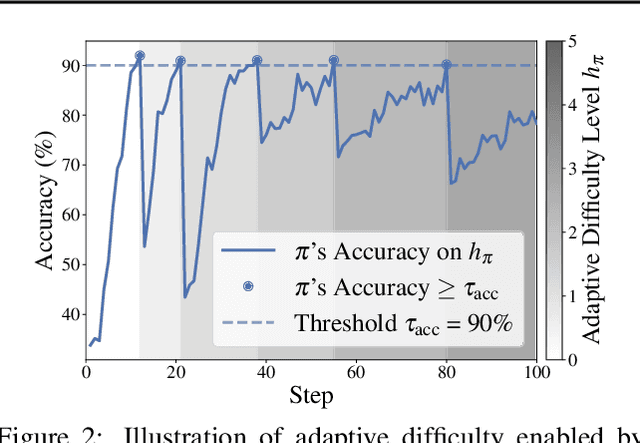
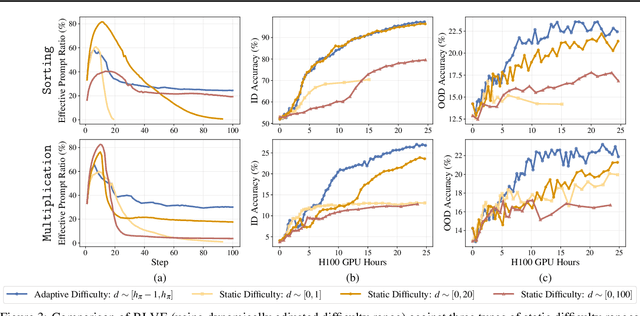
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Signal and Noise: A Framework for Reducing Uncertainty in Language Model Evaluation
Aug 18, 2025Developing large language models is expensive and involves making decisions with small experiments, typically by evaluating on large, multi-task evaluation suites. In this work, we analyze specific properties which make a benchmark more reliable for such decisions, and interventions to design higher-quality evaluation benchmarks. We introduce two key metrics that show differences in current benchmarks: signal, a benchmark's ability to separate better models from worse models, and noise, a benchmark's sensitivity to random variability between training steps. We demonstrate that benchmarks with a better signal-to-noise ratio are more reliable when making decisions at small scale, and those with less noise have lower scaling law prediction error. These results suggest that improving signal or noise will lead to more useful benchmarks, so we introduce three interventions designed to directly affect signal or noise. For example, we propose that switching to a metric that has better signal and noise (e.g., perplexity rather than accuracy) leads to better reliability and improved scaling law error. We also find that filtering noisy subtasks, to improve an aggregate signal-to-noise ratio, leads to more reliable multi-task evaluations. We also find that averaging the output of a model's intermediate checkpoints to reduce noise leads to consistent improvements. We conclude by recommending that those creating new benchmarks, or selecting which existing benchmarks to use, aim for high signal and low noise. We use 30 benchmarks for these experiments, and 375 open-weight language models from 60M to 32B parameters, resulting in a new, publicly available dataset of 900K evaluation benchmark results, totaling 200M instances.