 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinually self-improving AI
Mar 18, 2026Modern language model-based AI systems are remarkably powerful, yet their capabilities remain fundamentally capped by their human creators in three key ways. First, although a model's weights can be updated via fine-tuning, acquiring new knowledge from small, specialized corpora after pretraining remains highly data-inefficient. Second, the training of these systems relies heavily on finite, human-generated data from across history. Third, the pipelines used to train AI models are confined by the algorithms that human researchers can discover and explore. This thesis takes a small step toward overcoming these inherent limitations, presenting three chapters aimed at breaking these dependencies to create continually self-improving AI. First, to overcome this data-efficiency barrier in knowledge acquisition, we propose a synthetic data approach that diversifies and amplifies small corpora into rich knowledge representations, enabling a model to effectively update its parameters from limited source material. Second, to reduce reliance on human data, we show that given a fixed amount of such data, the model can self-generate synthetic data to bootstrap its fundamental pretraining capabilities without distillation from any off-the-shelf, instruction-tuned LM. Finally, to transcend human-engineered training paradigms, we demonstrate that by scaling search during test time over the space of algorithms, AI can search over a larger space of learning algorithm configurations than human researchers can explore manually.
Towards Execution-Grounded Automated AI Research
Jan 20, 2026Automated AI research holds great potential to accelerate scientific discovery. However, current LLMs often generate plausible-looking but ineffective ideas. Execution grounding may help, but it is unclear whether automated execution is feasible and whether LLMs can learn from the execution feedback. To investigate these, we first build an automated executor to implement ideas and launch large-scale parallel GPU experiments to verify their effectiveness. We then convert two realistic research problems - LLM pre-training and post-training - into execution environments and demonstrate that our automated executor can implement a large fraction of the ideas sampled from frontier LLMs. We analyze two methods to learn from the execution feedback: evolutionary search and reinforcement learning. Execution-guided evolutionary search is sample-efficient: it finds a method that significantly outperforms the GRPO baseline (69.4% vs 48.0%) on post-training, and finds a pre-training recipe that outperforms the nanoGPT baseline (19.7 minutes vs 35.9 minutes) on pre-training, all within just ten search epochs. Frontier LLMs often generate meaningful algorithmic ideas during search, but they tend to saturate early and only occasionally exhibit scaling trends. Reinforcement learning from execution reward, on the other hand, suffers from mode collapse. It successfully improves the average reward of the ideator model but not the upper-bound, due to models converging on simple ideas. We thoroughly analyze the executed ideas and training dynamics to facilitate future efforts towards execution-grounded automated AI research.
Synthetic bootstrapped pretraining
Sep 17, 2025We introduce Synthetic Bootstrapped Pretraining (SBP), a language model (LM) pretraining procedure that first learns a model of relations between documents from the pretraining dataset and then leverages it to synthesize a vast new corpus for joint training. While the standard pretraining teaches LMs to learn causal correlations among tokens within a single document, it is not designed to efficiently model the rich, learnable inter-document correlations that can potentially lead to better performance. We validate SBP by designing a compute-matched pretraining setup and pretrain a 3B-parameter model on up to 1T tokens from scratch. We find SBP consistently improves upon a strong repetition baseline and delivers a significant fraction of performance improvement attainable by an oracle upper bound with access to 20x more unique data. Qualitative analysis reveals that the synthesized documents go beyond mere paraphrases -- SBP first abstracts a core concept from the seed material and then crafts a new narration on top of it. Besides strong empirical performance, SBP admits a natural Bayesian interpretation: the synthesizer implicitly learns to abstract the latent concepts shared between related documents.
s1: Simple test-time scaling
Jan 31, 2025



Test-time scaling is a promising new approach to language modeling that uses extra test-time compute to improve performance. Recently, OpenAI's o1 model showed this capability but did not publicly share its methodology, leading to many replication efforts. We seek the simplest approach to achieve test-time scaling and strong reasoning performance. First, we curate a small dataset s1K of 1,000 questions paired with reasoning traces relying on three criteria we validate through ablations: difficulty, diversity, and quality. Second, we develop budget forcing to control test-time compute by forcefully terminating the model's thinking process or lengthening it by appending "Wait" multiple times to the model's generation when it tries to end. This can lead the model to double-check its answer, often fixing incorrect reasoning steps. After supervised finetuning the Qwen2.5-32B-Instruct language model on s1K and equipping it with budget forcing, our model s1 exceeds o1-preview on competition math questions by up to 27% (MATH and AIME24). Further, scaling s1 with budget forcing allows extrapolating beyond its performance without test-time intervention: from 50% to 57% on AIME24. Our model, data, and code are open-source at https://github.com/simplescaling/s1.
Synthetic continued pretraining
Sep 11, 2024



Pretraining on large-scale, unstructured internet text has enabled language models to acquire a significant amount of world knowledge. However, this knowledge acquisition is data-inefficient -- to learn a given fact, models must be trained on hundreds to thousands of diverse representations of it. This poses a challenge when adapting a pretrained model to a small corpus of domain-specific documents, where each fact may appear rarely or only once. We propose to bridge this gap with synthetic continued pretraining: using the small domain-specific corpus to synthesize a large corpus more amenable to learning, and then performing continued pretraining on the synthesized corpus. We instantiate this proposal with EntiGraph, a synthetic data augmentation algorithm that extracts salient entities from the source documents and then generates diverse text by drawing connections between the sampled entities. Synthetic continued pretraining using EntiGraph enables a language model to answer questions and follow generic instructions related to the source documents without access to them. If instead, the source documents are available at inference time, we show that the knowledge acquired through our approach compounds with retrieval-augmented generation. To better understand these results, we build a simple mathematical model of EntiGraph, and show how synthetic data augmentation can "rearrange" knowledge to enable more data-efficient learning.
Bellman Conformal Inference: Calibrating Prediction Intervals For Time Series
Feb 09, 2024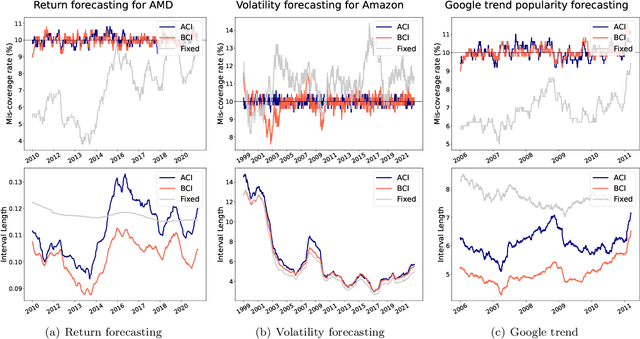
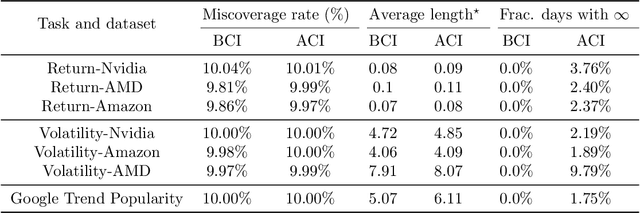
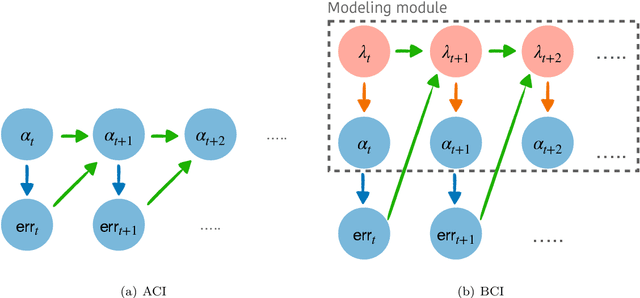
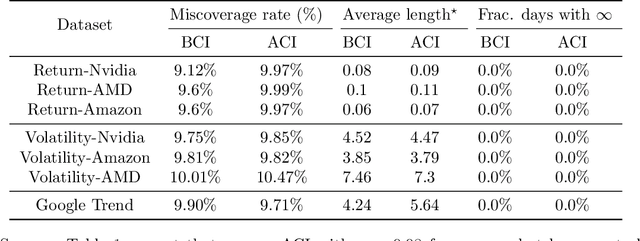
We introduce Bellman Conformal Inference (BCI), a framework that wraps around any time series forecasting models and provides approximately calibrated prediction intervals. Unlike existing methods, BCI is able to leverage multi-step ahead forecasts and explicitly optimize the average interval lengths by solving a one-dimensional stochastic control problem (SCP) at each time step. In particular, we use the dynamic programming algorithm to find the optimal policy for the SCP. We prove that BCI achieves long-term coverage under arbitrary distribution shifts and temporal dependence, even with poor multi-step ahead forecasts. We find empirically that BCI avoids uninformative intervals that have infinite lengths and generates substantially shorter prediction intervals in multiple applications when compared with existing methods.
ResMem: Learn what you can and memorize the rest
Feb 03, 2023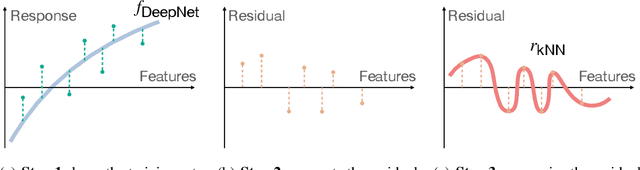

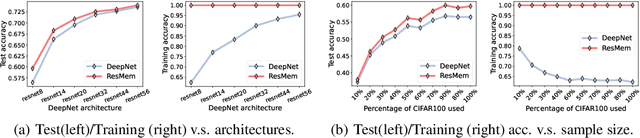
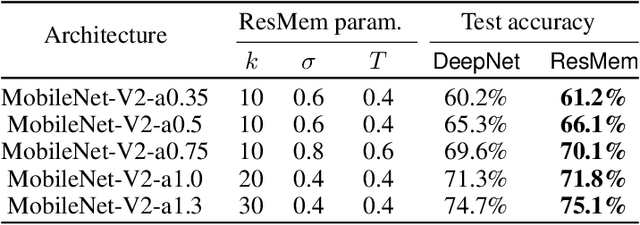
The impressive generalization performance of modern neural networks is attributed in part to their ability to implicitly memorize complex training patterns. Inspired by this, we explore a novel mechanism to improve model generalization via explicit memorization. Specifically, we propose the residual-memorization (ResMem) algorithm, a new method that augments an existing prediction model (e.g. a neural network) by fitting the model's residuals with a $k$-nearest neighbor based regressor. The final prediction is then the sum of the original model and the fitted residual regressor. By construction, ResMem can explicitly memorize the training labels. Empirically, we show that ResMem consistently improves the test set generalization of the original prediction model across various standard vision and natural language processing benchmarks. Theoretically, we formulate a stylized linear regression problem and rigorously show that ResMem results in a more favorable test risk over the base predictor.
Predicting Out-of-Distribution Error with the Projection Norm
Feb 11, 2022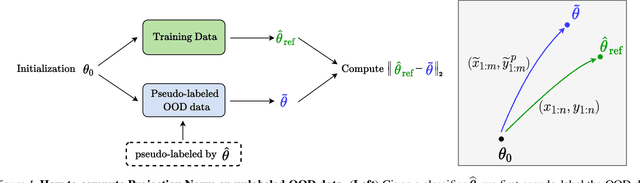
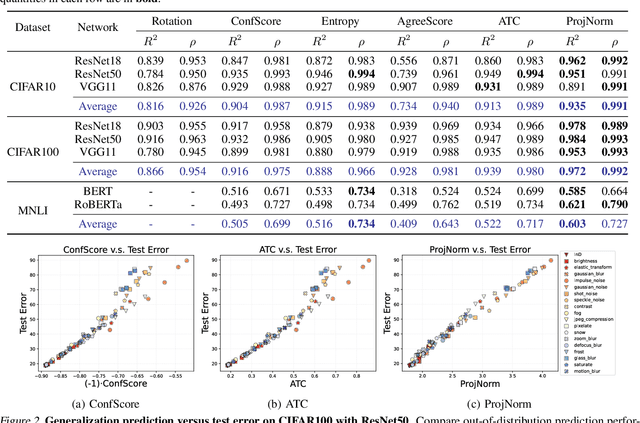
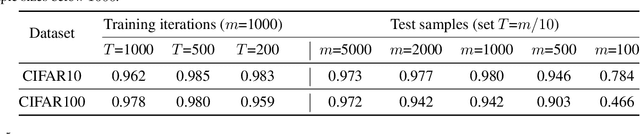

We propose a metric -- Projection Norm -- to predict a model's performance on out-of-distribution (OOD) data without access to ground truth labels. Projection Norm first uses model predictions to pseudo-label test samples and then trains a new model on the pseudo-labels. The more the new model's parameters differ from an in-distribution model, the greater the predicted OOD error. Empirically, our approach outperforms existing methods on both image and text classification tasks and across different network architectures. Theoretically, we connect our approach to a bound on the test error for overparameterized linear models. Furthermore, we find that Projection Norm is the only approach that achieves non-trivial detection performance on adversarial examples. Our code is available at https://github.com/yaodongyu/ProjNorm.
Understanding Generalization in Adversarial Training via the Bias-Variance Decomposition
Mar 17, 2021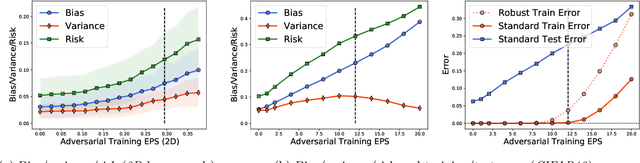
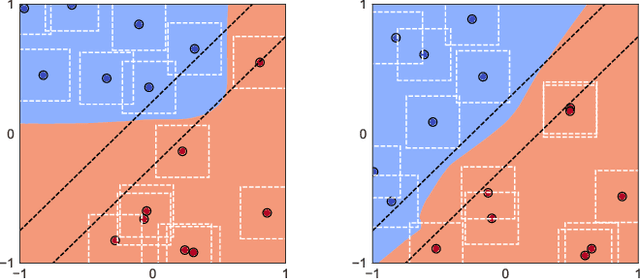
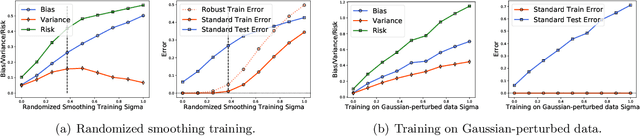
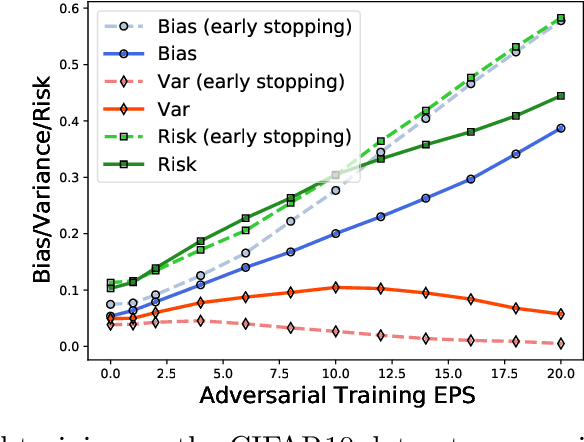
Adversarially trained models exhibit a large generalization gap: they can interpolate the training set even for large perturbation radii, but at the cost of large test error on clean samples. To investigate this gap, we decompose the test risk into its bias and variance components. We find that the bias increases monotonically with perturbation size and is the dominant term in the risk. Meanwhile, the variance is unimodal, peaking near the interpolation threshold for the training set. In contrast, we show that popular explanations for the generalization gap instead predict the variance to be monotonic, which leaves an unresolved mystery. We show that the same unimodal variance appears in a simple high-dimensional logistic regression problem, as well as for randomized smoothing. Overall, our results highlight the power of bias-variance decompositions in modern settings--by providing two measurements instead of one, they can rule out some theories and clarify others.
Exact Gap between Generalization Error and Uniform Convergence in Random Feature Models
Mar 08, 2021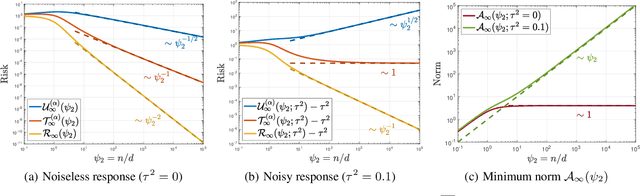
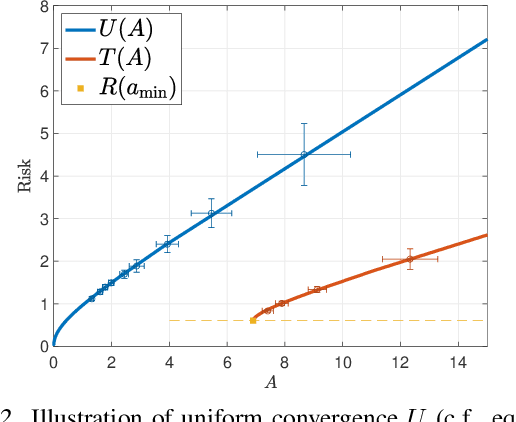
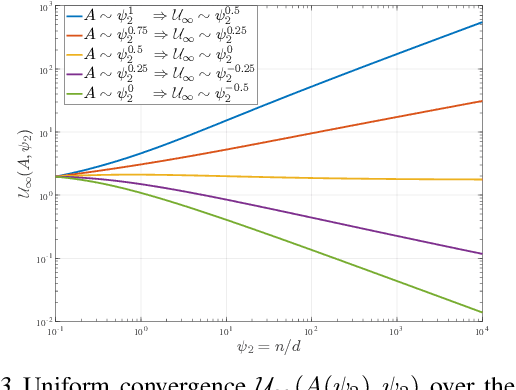
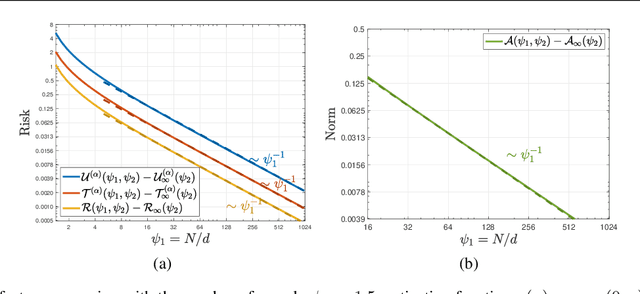
Recent work showed that there could be a large gap between the classical uniform convergence bound and the actual test error of zero-training-error predictors (interpolators) such as deep neural networks. To better understand this gap, we study the uniform convergence in the nonlinear random feature model and perform a precise theoretical analysis on how uniform convergence depends on the sample size and the number of parameters. We derive and prove analytical expressions for three quantities in this model: 1) classical uniform convergence over norm balls, 2) uniform convergence over interpolators in the norm ball (recently proposed by Zhou et al. (2020)), and 3) the risk of minimum norm interpolator. We show that, in the setting where the classical uniform convergence bound is vacuous (diverges to $\infty$), uniform convergence over the interpolators still gives a non-trivial bound of the test error of interpolating solutions. We also showcase a different setting where classical uniform convergence bound is non-vacuous, but uniform convergence over interpolators can give an improved sample complexity guarantee. Our result provides a first exact comparison between the test errors and uniform convergence bounds for interpolators beyond simple linear models.