 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIH-Challenge: A Training Dataset to Improve Instruction Hierarchy on Frontier LLMs
Mar 11, 2026Instruction hierarchy (IH) defines how LLMs prioritize system, developer, user, and tool instructions under conflict, providing a concrete, trust-ordered policy for resolving instruction conflicts. IH is key to defending against jailbreaks, system prompt extractions, and agentic prompt injections. However, robust IH behavior is difficult to train: IH failures can be confounded with instruction-following failures, conflicts can be nuanced, and models can learn shortcuts such as overrefusing. We introduce IH-Challenge, a reinforcement learning training dataset, to address these difficulties. Fine-tuning GPT-5-Mini on IH-Challenge with online adversarial example generation improves IH robustness by +10.0% on average across 16 in-distribution, out-of-distribution, and human red-teaming benchmarks (84.1% to 94.1%), reduces unsafe behavior from 6.6% to 0.7% while improving helpfulness on general safety evaluations, and saturates an internal static agentic prompt injection evaluation, with minimal capability regression. We release the IH-Challenge dataset (https://huggingface.co/datasets/openai/ih-challenge) to support future research on robust instruction hierarchy.
OpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
Attention-Only Transformers via Unrolled Subspace Denoising
Jun 04, 2025Despite the popularity of transformers in practice, their architectures are empirically designed and neither mathematically justified nor interpretable. Moreover, as indicated by many empirical studies, some components of transformer architectures may be redundant. To derive a fully interpretable transformer architecture with only necessary components, we contend that the goal of representation learning is to compress a set of noisy initial token representations towards a mixture of low-dimensional subspaces. To compress these noisy token representations, an associated denoising operation naturally takes the form of a multi-head (subspace) self-attention. By unrolling such iterative denoising operations into a deep network, we arrive at a highly compact architecture that consists of \textit{only} self-attention operators with skip connections at each layer. Moreover, we show that each layer performs highly efficient denoising: it improves the signal-to-noise ratio of token representations \textit{at a linear rate} with respect to the number of layers. Despite its simplicity, extensive experiments on vision and language tasks demonstrate that such a transformer achieves performance close to that of standard transformer architectures such as GPT-2 and CRATE.
Scaling Laws in Patchification: An Image Is Worth 50,176 Tokens And More
Feb 06, 2025Since the introduction of Vision Transformer (ViT), patchification has long been regarded as a de facto image tokenization approach for plain visual architectures. By compressing the spatial size of images, this approach can effectively shorten the token sequence and reduce the computational cost of ViT-like plain architectures. In this work, we aim to thoroughly examine the information loss caused by this patchification-based compressive encoding paradigm and how it affects visual understanding. We conduct extensive patch size scaling experiments and excitedly observe an intriguing scaling law in patchification: the models can consistently benefit from decreased patch sizes and attain improved predictive performance, until it reaches the minimum patch size of 1x1, i.e., pixel tokenization. This conclusion is broadly applicable across different vision tasks, various input scales, and diverse architectures such as ViT and the recent Mamba models. Moreover, as a by-product, we discover that with smaller patches, task-specific decoder heads become less critical for dense prediction. In the experiments, we successfully scale up the visual sequence to an exceptional length of 50,176 tokens, achieving a competitive test accuracy of 84.6% with a base-sized model on the ImageNet-1k benchmark. We hope this study can provide insights and theoretical foundations for future works of building non-compressive vision models. Code is available at https://github.com/wangf3014/Patch_Scaling.
Trading Inference-Time Compute for Adversarial Robustness
Jan 31, 2025



We conduct experiments on the impact of increasing inference-time compute in reasoning models (specifically OpenAI o1-preview and o1-mini) on their robustness to adversarial attacks. We find that across a variety of attacks, increased inference-time compute leads to improved robustness. In many cases (with important exceptions), the fraction of model samples where the attack succeeds tends to zero as the amount of test-time compute grows. We perform no adversarial training for the tasks we study, and we increase inference-time compute by simply allowing the models to spend more compute on reasoning, independently of the form of attack. Our results suggest that inference-time compute has the potential to improve adversarial robustness for Large Language Models. We also explore new attacks directed at reasoning models, as well as settings where inference-time compute does not improve reliability, and speculate on the reasons for these as well as ways to address them.
Token Statistics Transformer: Linear-Time Attention via Variational Rate Reduction
Dec 23, 2024



The attention operator is arguably the key distinguishing factor of transformer architectures, which have demonstrated state-of-the-art performance on a variety of tasks. However, transformer attention operators often impose a significant computational burden, with the computational complexity scaling quadratically with the number of tokens. In this work, we propose a novel transformer attention operator whose computational complexity scales linearly with the number of tokens. We derive our network architecture by extending prior work which has shown that a transformer style architecture naturally arises by "white-box" architecture design, where each layer of the network is designed to implement an incremental optimization step of a maximal coding rate reduction objective (MCR$^2$). Specifically, we derive a novel variational form of the MCR$^2$ objective and show that the architecture that results from unrolled gradient descent of this variational objective leads to a new attention module called Token Statistics Self-Attention (TSSA). TSSA has linear computational and memory complexity and radically departs from the typical attention architecture that computes pairwise similarities between tokens. Experiments on vision, language, and long sequence tasks show that simply swapping TSSA for standard self-attention, which we refer to as the Token Statistics Transformer (ToST), achieves competitive performance with conventional transformers while being significantly more computationally efficient and interpretable. Our results also somewhat call into question the conventional wisdom that pairwise similarity style attention mechanisms are critical to the success of transformer architectures. Code will be available at https://github.com/RobinWu218/ToST.
M-VAR: Decoupled Scale-wise Autoregressive Modeling for High-Quality Image Generation
Nov 15, 2024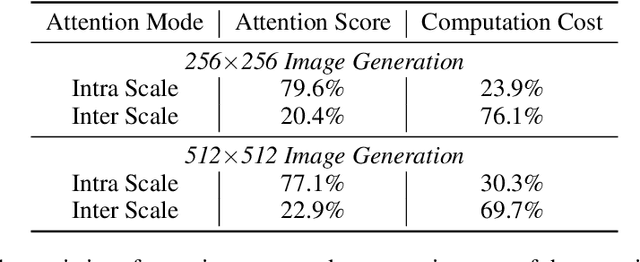



There exists recent work in computer vision, named VAR, that proposes a new autoregressive paradigm for image generation. Diverging from the vanilla next-token prediction, VAR structurally reformulates the image generation into a coarse to fine next-scale prediction. In this paper, we show that this scale-wise autoregressive framework can be effectively decoupled into \textit{intra-scale modeling}, which captures local spatial dependencies within each scale, and \textit{inter-scale modeling}, which models cross-scale relationships progressively from coarse-to-fine scales. This decoupling structure allows to rebuild VAR in a more computationally efficient manner. Specifically, for intra-scale modeling -- crucial for generating high-fidelity images -- we retain the original bidirectional self-attention design to ensure comprehensive modeling; for inter-scale modeling, which semantically connects different scales but is computationally intensive, we apply linear-complexity mechanisms like Mamba to substantially reduce computational overhead. We term this new framework M-VAR. Extensive experiments demonstrate that our method outperforms existing models in both image quality and generation speed. For example, our 1.5B model, with fewer parameters and faster inference speed, outperforms the largest VAR-d30-2B. Moreover, our largest model M-VAR-d32 impressively registers 1.78 FID on ImageNet 256$\times$256 and outperforms the prior-art autoregressive models LlamaGen/VAR by 0.4/0.19 and popular diffusion models LDM/DiT by 1.82/0.49, respectively. Code is avaiable at \url{https://github.com/OliverRensu/MVAR}.
Causal Image Modeling for Efficient Visual Understanding
Oct 10, 2024



In this work, we present a comprehensive analysis of causal image modeling and introduce the Adventurer series models where we treat images as sequences of patch tokens and employ uni-directional language models to learn visual representations. This modeling paradigm allows us to process images in a recurrent formulation with linear complexity relative to the sequence length, which can effectively address the memory and computation explosion issues posed by high-resolution and fine-grained images. In detail, we introduce two simple designs that seamlessly integrate image inputs into the causal inference framework: a global pooling token placed at the beginning of the sequence and a flipping operation between every two layers. Extensive empirical studies demonstrate the significant efficiency and effectiveness of this causal image modeling paradigm. For example, our base-sized Adventurer model attains a competitive test accuracy of 84.0% on the standard ImageNet-1k benchmark with 216 images/s training throughput, which is 5.3 times more efficient than vision transformers to achieve the same result.
Accuracy on the wrong line: On the pitfalls of noisy data for out-of-distribution generalisation
Jun 27, 2024"Accuracy-on-the-line" is a widely observed phenomenon in machine learning, where a model's accuracy on in-distribution (ID) and out-of-distribution (OOD) data is positively correlated across different hyperparameters and data configurations. But when does this useful relationship break down? In this work, we explore its robustness. The key observation is that noisy data and the presence of nuisance features can be sufficient to shatter the Accuracy-on-the-line phenomenon. In these cases, ID and OOD accuracy can become negatively correlated, leading to "Accuracy-on-the-wrong-line". This phenomenon can also occur in the presence of spurious (shortcut) features, which tend to overshadow the more complex signal (core, non-spurious) features, resulting in a large nuisance feature space. Moreover, scaling to larger datasets does not mitigate this undesirable behavior and may even exacerbate it. We formally prove a lower bound on Out-of-distribution (OOD) error in a linear classification model, characterizing the conditions on the noise and nuisance features for a large OOD error. We finally demonstrate this phenomenon across both synthetic and real datasets with noisy data and nuisance features.
A Global Geometric Analysis of Maximal Coding Rate Reduction
Jun 04, 2024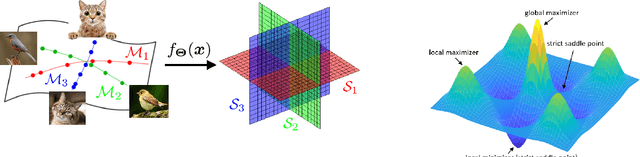
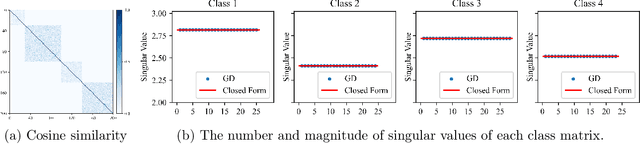
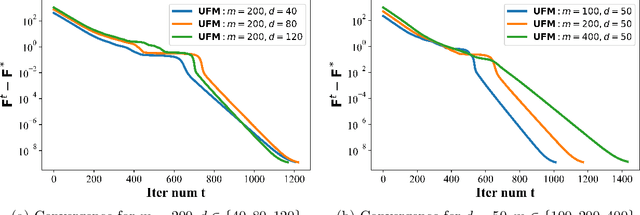
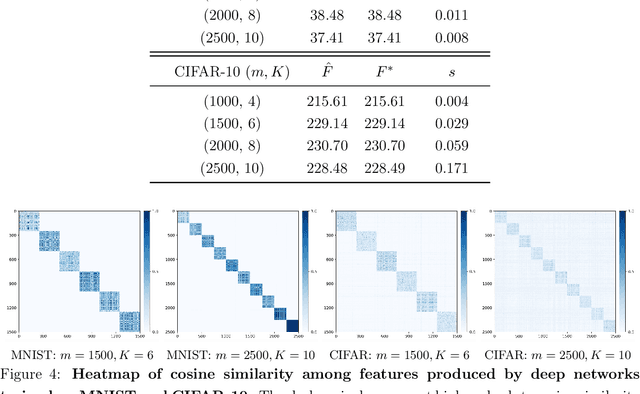
The maximal coding rate reduction (MCR$^2$) objective for learning structured and compact deep representations is drawing increasing attention, especially after its recent usage in the derivation of fully explainable and highly effective deep network architectures. However, it lacks a complete theoretical justification: only the properties of its global optima are known, and its global landscape has not been studied. In this work, we give a complete characterization of the properties of all its local and global optima, as well as other types of critical points. Specifically, we show that each (local or global) maximizer of the MCR$^2$ problem corresponds to a low-dimensional, discriminative, and diverse representation, and furthermore, each critical point of the objective is either a local maximizer or a strict saddle point. Such a favorable landscape makes MCR$^2$ a natural choice of objective for learning diverse and discriminative representations via first-order optimization methods. To validate our theoretical findings, we conduct extensive experiments on both synthetic and real data sets.