 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA and Privacy: When Random Projections Help (and When They Don't)
Jan 29, 2026We introduce the (Wishart) projection mechanism, a randomized map of the form $S \mapsto M f(S)$ with $M \sim W_d(1/r I_d, r)$ and study its differential privacy properties. For vector-valued queries $f$, we prove non-asymptotic DP guarantees without any additive noise, showing that Wishart randomness alone can suffice. For matrix-valued queries, however, we establish a sharp negative result: in the noise-free setting, the mechanism is not DP, and we demonstrate its vulnerability by implementing a near perfect membership inference attack (AUC $> 0.99$). We then analyze a noisy variant and prove privacy amplification due to randomness and low rank projection, in both large- and small-rank regimes, yielding stronger privacy guarantees than additive noise alone. Finally, we show that LoRA-style updates are an instance of the matrix-valued mechanism, implying that LoRA is not inherently private despite its built-in randomness, but that low-rank fine-tuning can be more private than full fine-tuning at the same noise level. Preliminary experiments suggest that tighter accounting enables lower noise and improved accuracy in practice.
Online Learning and Unlearning
May 13, 2025


We formalize the problem of online learning-unlearning, where a model is updated sequentially in an online setting while accommodating unlearning requests between updates. After a data point is unlearned, all subsequent outputs must be statistically indistinguishable from those of a model trained without that point. We present two online learner-unlearner (OLU) algorithms, both built upon online gradient descent (OGD). The first, passive OLU, leverages OGD's contractive property and injects noise when unlearning occurs, incurring no additional computation. The second, active OLU, uses an offline unlearning algorithm that shifts the model toward a solution excluding the deleted data. Under standard convexity and smoothness assumptions, both methods achieve regret bounds comparable to those of standard OGD, demonstrating that one can maintain competitive regret bounds while providing unlearning guarantees.
Differentially Private Steering for Large Language Model Alignment
Jan 30, 2025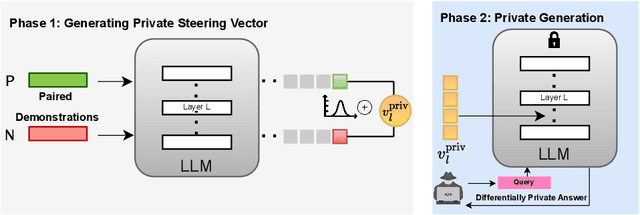

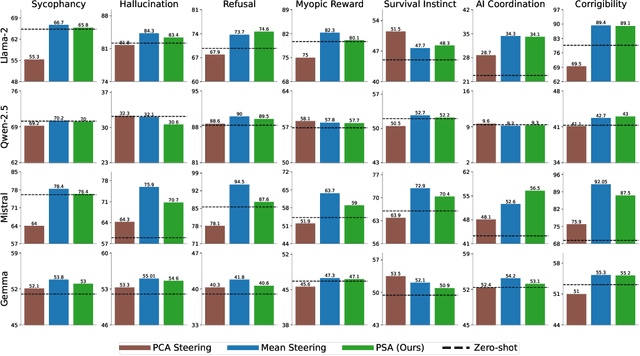
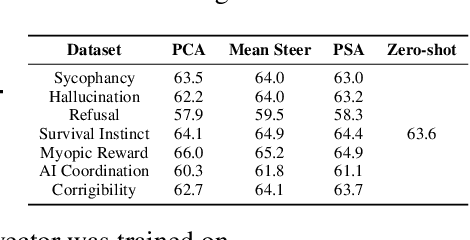
Aligning Large Language Models (LLMs) with human values and away from undesirable behaviors (such as hallucination) has become increasingly important. Recently, steering LLMs towards a desired behavior via activation editing has emerged as an effective method to mitigate harmful generations at inference-time. Activation editing modifies LLM representations by preserving information from positive demonstrations (e.g., truthful) and minimising information from negative demonstrations (e.g., hallucinations). When these demonstrations come from a private dataset, the aligned LLM may leak private information contained in those private samples. In this work, we present the first study of aligning LLM behavior with private datasets. Our work proposes the \textit{\underline{P}rivate \underline{S}teering for LLM \underline{A}lignment (PSA)} algorithm to edit LLM activations with differential privacy (DP) guarantees. We conduct extensive experiments on seven different benchmarks with open-source LLMs of different sizes (0.5B to 7B) and model families (LlaMa, Qwen, Mistral and Gemma). Our results show that PSA achieves DP guarantees for LLM alignment with minimal loss in performance, including alignment metrics, open-ended text generation quality, and general-purpose reasoning. We also develop the first Membership Inference Attack (MIA) for evaluating and auditing the empirical privacy for the problem of LLM steering via activation editing. Our attack is tailored for activation editing and relies solely on the generated texts without their associated probabilities. Our experiments support the theoretical guarantees by showing improved guarantees for our \textit{PSA} algorithm compared to several existing non-private techniques.
Accuracy on the wrong line: On the pitfalls of noisy data for out-of-distribution generalisation
Jun 27, 2024"Accuracy-on-the-line" is a widely observed phenomenon in machine learning, where a model's accuracy on in-distribution (ID) and out-of-distribution (OOD) data is positively correlated across different hyperparameters and data configurations. But when does this useful relationship break down? In this work, we explore its robustness. The key observation is that noisy data and the presence of nuisance features can be sufficient to shatter the Accuracy-on-the-line phenomenon. In these cases, ID and OOD accuracy can become negatively correlated, leading to "Accuracy-on-the-wrong-line". This phenomenon can also occur in the presence of spurious (shortcut) features, which tend to overshadow the more complex signal (core, non-spurious) features, resulting in a large nuisance feature space. Moreover, scaling to larger datasets does not mitigate this undesirable behavior and may even exacerbate it. We formally prove a lower bound on Out-of-distribution (OOD) error in a linear classification model, characterizing the conditions on the noise and nuisance features for a large OOD error. We finally demonstrate this phenomenon across both synthetic and real datasets with noisy data and nuisance features.
Provable Privacy with Non-Private Pre-Processing
Mar 19, 2024When analysing Differentially Private (DP) machine learning pipelines, the potential privacy cost of data-dependent pre-processing is frequently overlooked in privacy accounting. In this work, we propose a general framework to evaluate the additional privacy cost incurred by non-private data-dependent pre-processing algorithms. Our framework establishes upper bounds on the overall privacy guarantees by utilising two new technical notions: a variant of DP termed Smooth DP and the bounded sensitivity of the pre-processing algorithms. In addition to the generic framework, we provide explicit overall privacy guarantees for multiple data-dependent pre-processing algorithms, such as data imputation, quantization, deduplication and PCA, when used in combination with several DP algorithms. Notably, this framework is also simple to implement, allowing direct integration into existing DP pipelines.
PILLAR: How to make semi-private learning more effective
Jun 06, 2023In Semi-Supervised Semi-Private (SP) learning, the learner has access to both public unlabelled and private labelled data. We propose a computationally efficient algorithm that, under mild assumptions on the data, provably achieves significantly lower private labelled sample complexity and can be efficiently run on real-world datasets. For this purpose, we leverage the features extracted by networks pre-trained on public (labelled or unlabelled) data, whose distribution can significantly differ from the one on which SP learning is performed. To validate its empirical effectiveness, we propose a wide variety of experiments under tight privacy constraints ($\epsilon = 0.1$) and with a focus on low-data regimes. In all of these settings, our algorithm exhibits significantly improved performance over available baselines that use similar amounts of public data.
How unfair is private learning ?
Jun 08, 2022

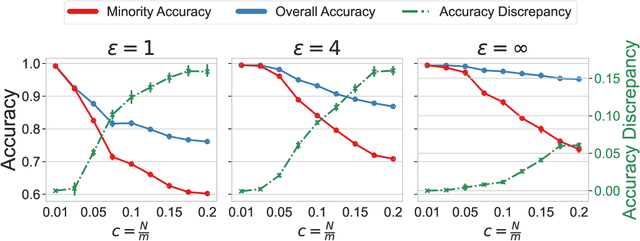
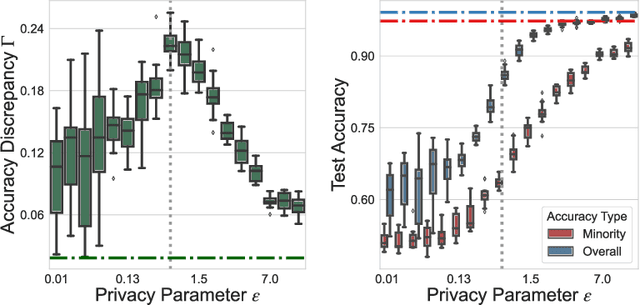
As machine learning algorithms are deployed on sensitive data in critical decision making processes, it is becoming increasingly important that they are also private and fair. In this paper, we show that, when the data has a long-tailed structure, it is not possible to build accurate learning algorithms that are both private and results in higher accuracy on minority subpopulations. We further show that relaxing overall accuracy can lead to good fairness even with strict privacy requirements. To corroborate our theoretical results in practice, we provide an extensive set of experimental results using a variety of synthetic, vision~(\cifar and CelebA), and tabular~(Law School) datasets and learning algorithms.