Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow unfair is private learning ?
Paper and Code
Jun 08, 2022

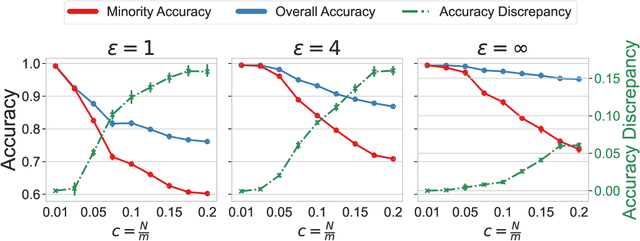
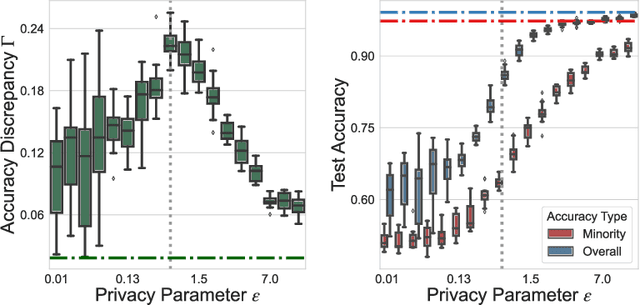
As machine learning algorithms are deployed on sensitive data in critical decision making processes, it is becoming increasingly important that they are also private and fair. In this paper, we show that, when the data has a long-tailed structure, it is not possible to build accurate learning algorithms that are both private and results in higher accuracy on minority subpopulations. We further show that relaxing overall accuracy can lead to good fairness even with strict privacy requirements. To corroborate our theoretical results in practice, we provide an extensive set of experimental results using a variety of synthetic, vision~(\cifar and CelebA), and tabular~(Law School) datasets and learning algorithms.
* Accepted as an Oral paper in UAI '2022
View paper on
 OpenReview
OpenReview