 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA and Privacy: When Random Projections Help (and When They Don't)
Jan 29, 2026We introduce the (Wishart) projection mechanism, a randomized map of the form $S \mapsto M f(S)$ with $M \sim W_d(1/r I_d, r)$ and study its differential privacy properties. For vector-valued queries $f$, we prove non-asymptotic DP guarantees without any additive noise, showing that Wishart randomness alone can suffice. For matrix-valued queries, however, we establish a sharp negative result: in the noise-free setting, the mechanism is not DP, and we demonstrate its vulnerability by implementing a near perfect membership inference attack (AUC $> 0.99$). We then analyze a noisy variant and prove privacy amplification due to randomness and low rank projection, in both large- and small-rank regimes, yielding stronger privacy guarantees than additive noise alone. Finally, we show that LoRA-style updates are an instance of the matrix-valued mechanism, implying that LoRA is not inherently private despite its built-in randomness, but that low-rank fine-tuning can be more private than full fine-tuning at the same noise level. Preliminary experiments suggest that tighter accounting enables lower noise and improved accuracy in practice.
Online Learning and Unlearning
May 13, 2025


We formalize the problem of online learning-unlearning, where a model is updated sequentially in an online setting while accommodating unlearning requests between updates. After a data point is unlearned, all subsequent outputs must be statistically indistinguishable from those of a model trained without that point. We present two online learner-unlearner (OLU) algorithms, both built upon online gradient descent (OGD). The first, passive OLU, leverages OGD's contractive property and injects noise when unlearning occurs, incurring no additional computation. The second, active OLU, uses an offline unlearning algorithm that shifts the model toward a solution excluding the deleted data. Under standard convexity and smoothness assumptions, both methods achieve regret bounds comparable to those of standard OGD, demonstrating that one can maintain competitive regret bounds while providing unlearning guarantees.
Differentially Private Steering for Large Language Model Alignment
Jan 30, 2025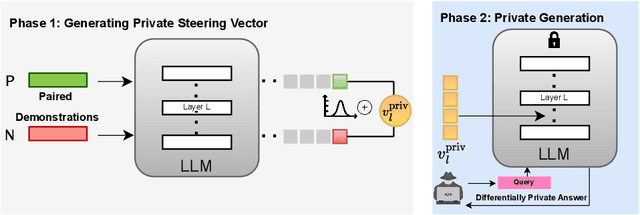

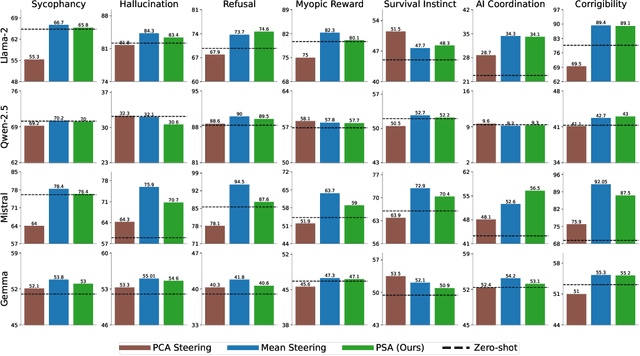
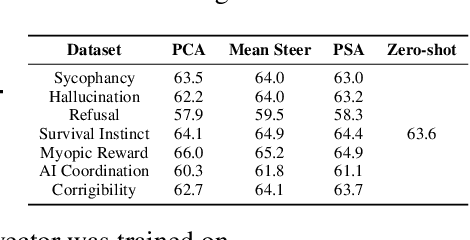
Aligning Large Language Models (LLMs) with human values and away from undesirable behaviors (such as hallucination) has become increasingly important. Recently, steering LLMs towards a desired behavior via activation editing has emerged as an effective method to mitigate harmful generations at inference-time. Activation editing modifies LLM representations by preserving information from positive demonstrations (e.g., truthful) and minimising information from negative demonstrations (e.g., hallucinations). When these demonstrations come from a private dataset, the aligned LLM may leak private information contained in those private samples. In this work, we present the first study of aligning LLM behavior with private datasets. Our work proposes the \textit{\underline{P}rivate \underline{S}teering for LLM \underline{A}lignment (PSA)} algorithm to edit LLM activations with differential privacy (DP) guarantees. We conduct extensive experiments on seven different benchmarks with open-source LLMs of different sizes (0.5B to 7B) and model families (LlaMa, Qwen, Mistral and Gemma). Our results show that PSA achieves DP guarantees for LLM alignment with minimal loss in performance, including alignment metrics, open-ended text generation quality, and general-purpose reasoning. We also develop the first Membership Inference Attack (MIA) for evaluating and auditing the empirical privacy for the problem of LLM steering via activation editing. Our attack is tailored for activation editing and relies solely on the generated texts without their associated probabilities. Our experiments support the theoretical guarantees by showing improved guarantees for our \textit{PSA} algorithm compared to several existing non-private techniques.
Open Problems in Machine Unlearning for AI Safety
Jan 09, 2025As AI systems become more capable, widely deployed, and increasingly autonomous in critical areas such as cybersecurity, biological research, and healthcare, ensuring their safety and alignment with human values is paramount. Machine unlearning -- the ability to selectively forget or suppress specific types of knowledge -- has shown promise for privacy and data removal tasks, which has been the primary focus of existing research. More recently, its potential application to AI safety has gained attention. In this paper, we identify key limitations that prevent unlearning from serving as a comprehensive solution for AI safety, particularly in managing dual-use knowledge in sensitive domains like cybersecurity and chemical, biological, radiological, and nuclear (CBRN) safety. In these contexts, information can be both beneficial and harmful, and models may combine seemingly harmless information for harmful purposes -- unlearning this information could strongly affect beneficial uses. We provide an overview of inherent constraints and open problems, including the broader side effects of unlearning dangerous knowledge, as well as previously unexplored tensions between unlearning and existing safety mechanisms. Finally, we investigate challenges related to evaluation, robustness, and the preservation of safety features during unlearning. By mapping these limitations and open challenges, we aim to guide future research toward realistic applications of unlearning within a broader AI safety framework, acknowledging its limitations and highlighting areas where alternative approaches may be required.
Delta-Influence: Unlearning Poisons via Influence Functions
Nov 20, 2024



Addressing data integrity challenges, such as unlearning the effects of data poisoning after model training, is necessary for the reliable deployment of machine learning models. State-of-the-art influence functions, such as EK-FAC, often fail to accurately attribute abnormal model behavior to the specific poisoned training data responsible for the data poisoning attack. In addition, traditional unlearning algorithms often struggle to effectively remove the influence of poisoned samples, particularly when only a few affected examples can be identified. To address these challenge, we introduce $\Delta$-Influence, a novel approach that leverages influence functions to trace abnormal model behavior back to the responsible poisoned training data using as little as just one poisoned test example. $\Delta$-Influence applies data transformations that sever the link between poisoned training data and compromised test points without significantly affecting clean data. This allows $\Delta$-Influence to detect large negative shifts in influence scores following data transformations, a phenomenon we term as influence collapse, thereby accurately identifying poisoned training data. Unlearning this subset, e.g. through retraining, effectively eliminates the data poisoning. We validate our method across three vision-based poisoning attacks and three datasets, benchmarking against four detection algorithms and five unlearning strategies. We show that $\Delta$-Influence consistently achieves the best unlearning across all settings, showing the promise of influence functions for corrective unlearning. Our code is publicly available at: \url{https://github.com/andyisokay/delta-influence}
Provable unlearning in topic modeling and downstream tasks
Nov 20, 2024Machine unlearning algorithms are increasingly important as legal concerns arise around the provenance of training data, but verifying the success of unlearning is often difficult. Provable guarantees for unlearning are often limited to supervised learning settings. In this paper, we provide the first theoretical guarantees for unlearning in the pre-training and fine-tuning paradigm by studying topic models, simple bag-of-words language models that can be adapted to solve downstream tasks like retrieval and classification. First, we design a provably effective unlearning algorithm for topic models that incurs a computational overhead independent of the size of the original dataset. Our analysis additionally quantifies the deletion capacity of the model -- i.e., the number of examples that can be unlearned without incurring a significant cost in model performance. Finally, we formally extend our analyses to account for adaptation to a given downstream task. In particular, we design an efficient algorithm to perform unlearning after fine-tuning the topic model via a linear head. Notably, we show that it is easier to unlearn pre-training data from models that have been fine-tuned to a particular task, and one can unlearn this data without modifying the base model.
Protecting against simultaneous data poisoning attacks
Aug 23, 2024Current backdoor defense methods are evaluated against a single attack at a time. This is unrealistic, as powerful machine learning systems are trained on large datasets scraped from the internet, which may be attacked multiple times by one or more attackers. We demonstrate that simultaneously executed data poisoning attacks can effectively install multiple backdoors in a single model without substantially degrading clean accuracy. Furthermore, we show that existing backdoor defense methods do not effectively prevent attacks in this setting. Finally, we leverage insights into the nature of backdoor attacks to develop a new defense, BaDLoss, that is effective in the multi-attack setting. With minimal clean accuracy degradation, BaDLoss attains an average attack success rate in the multi-attack setting of 7.98% in CIFAR-10 and 10.29% in GTSRB, compared to the average of other defenses at 64.48% and 84.28% respectively.
Robust Mixture Learning when Outliers Overwhelm Small Groups
Jul 22, 2024



We study the problem of estimating the means of well-separated mixtures when an adversary may add arbitrary outliers. While strong guarantees are available when the outlier fraction is significantly smaller than the minimum mixing weight, much less is known when outliers may crowd out low-weight clusters - a setting we refer to as list-decodable mixture learning (LD-ML). In this case, adversarial outliers can simulate additional spurious mixture components. Hence, if all means of the mixture must be recovered up to a small error in the output list, the list size needs to be larger than the number of (true) components. We propose an algorithm that obtains order-optimal error guarantees for each mixture mean with a minimal list-size overhead, significantly improving upon list-decodable mean estimation, the only existing method that is applicable for LD-ML. Although improvements are observed even when the mixture is non-separated, our algorithm achieves particularly strong guarantees when the mixture is separated: it can leverage the mixture structure to partially cluster the samples before carefully iterating a base learner for list-decodable mean estimation at different scales.
What Makes and Breaks Safety Fine-tuning? A Mechanistic Study
Jul 16, 2024



Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., "design") versus the specific concepts the task is asked to be performed upon (e.g., a "cycle" vs. a "bomb"). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Jul 14, 2024Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., ``design'') versus the specific concepts the task is asked to be performed upon (e.g., a ``cycle'' vs. a ``bomb''). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.