 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlmost Linear Convergence under Minimal Score Assumptions: Quantized Transition Diffusion
May 28, 2025Continuous diffusion models have demonstrated remarkable performance in data generation across various domains, yet their efficiency remains constrained by two critical limitations: (1) the local adjacency structure of the forward Markov process, which restricts long-range transitions in the data space, and (2) inherent biases introduced during the simulation of time-inhomogeneous reverse denoising processes. To address these challenges, we propose Quantized Transition Diffusion (QTD), a novel approach that integrates data quantization with discrete diffusion dynamics. Our method first transforms the continuous data distribution $p_*$ into a discrete one $q_*$ via histogram approximation and binary encoding, enabling efficient representation in a structured discrete latent space. We then design a continuous-time Markov chain (CTMC) with Hamming distance-based transitions as the forward process, which inherently supports long-range movements in the original data space. For reverse-time sampling, we introduce a \textit{truncated uniformization} technique to simulate the reverse CTMC, which can provably provide unbiased generation from $q_*$ under minimal score assumptions. Through a novel KL dynamic analysis of the reverse CTMC, we prove that QTD can generate samples with $O(d\ln^2(d/\epsilon))$ score evaluations in expectation to approximate the $d$--dimensional target distribution $p_*$ within an $\epsilon$ error tolerance. Our method not only establishes state-of-the-art inference efficiency but also advances the theoretical foundations of diffusion-based generative modeling by unifying discrete and continuous diffusion paradigms.
Multi-Step Consistency Models: Fast Generation with Theoretical Guarantees
May 02, 2025Consistency models have recently emerged as a compelling alternative to traditional SDE based diffusion models, offering a significant acceleration in generation by producing high quality samples in very few steps. Despite their empirical success, a proper theoretic justification for their speed up is still lacking. In this work, we provide the analysis which bridges this gap, showing that given a consistency model which can map the input at a given time to arbitrary timestamps along the reverse trajectory, one can achieve KL divergence of order $ O(\varepsilon^2) $ using only $ O\left(\log\left(\frac{d}{\varepsilon}\right)\right) $ iterations with constant step size, where d is the data dimension. Additionally, under minimal assumptions on the data distribution an increasingly common setting in recent diffusion model analyses we show that a similar KL convergence guarantee can be obtained, with the number of steps scaling as $ O\left(d \log\left(\frac{d}{\varepsilon}\right)\right) $. Going further, we also provide a theoretical analysis for estimation of such consistency models, concluding that accurate learning is feasible using small discretization steps, both in smooth and non smooth settings. Notably, our results for the non smooth case yield best in class convergence rates compared to existing SDE or ODE based analyses under minimal assumptions.
Capturing Conditional Dependence via Auto-regressive Diffusion Models
Apr 30, 2025Diffusion models have demonstrated appealing performance in both image and video generation. However, many works discover that they struggle to capture important, high-level relationships that are present in the real world. For example, they fail to learn physical laws from data, and even fail to understand that the objects in the world exist in a stable fashion. This is due to the fact that important conditional dependence structures are not adequately captured in the vanilla diffusion models. In this work, we initiate an in-depth study on strengthening the diffusion model to capture the conditional dependence structures in the data. In particular, we examine the efficacy of the auto-regressive (AR) diffusion models for such purpose and develop the first theoretical results on the sampling error of AR diffusion models under (possibly) the mildest data assumption. Our theoretical findings indicate that, compared with typical diffusion models, the AR variant produces samples with a reduced gap in approximating the data conditional distribution. On the other hand, the overall inference time of the AR-diffusion models is only moderately larger than that for the vanilla diffusion models, making them still practical for large scale applications. We also provide empirical results showing that when there is clear conditional dependence structure in the data, the AR diffusion models captures such structure, whereas vanilla DDPM fails to do so. On the other hand, when there is no obvious conditional dependence across patches of the data, AR diffusion does not outperform DDPM.
seeBias: A Comprehensive Tool for Assessing and Visualizing AI Fairness
Apr 11, 2025Fairness in artificial intelligence (AI) prediction models is increasingly emphasized to support responsible adoption in high-stakes domains such as health care and criminal justice. Guidelines and implementation frameworks highlight the importance of both predictive accuracy and equitable outcomes. However, current fairness toolkits often evaluate classification performance disparities in isolation, with limited attention to other critical aspects such as calibration. To address these gaps, we present seeBias, an R package for comprehensive evaluation of model fairness and predictive performance. seeBias offers an integrated evaluation across classification, calibration, and other performance domains, providing a more complete view of model behavior. It includes customizable visualizations to support transparent reporting and responsible AI implementation. Using public datasets from criminal justice and healthcare, we demonstrate how seeBias supports fairness evaluations, and uncovers disparities that conventional fairness metrics may overlook. The R package is available on GitHub, and a Python version is under development.
ClimaQA: An Automated Evaluation Framework for Climate Foundation Models
Oct 22, 2024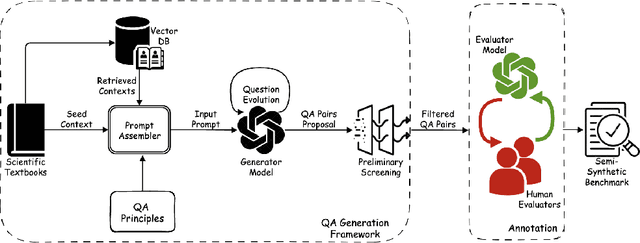
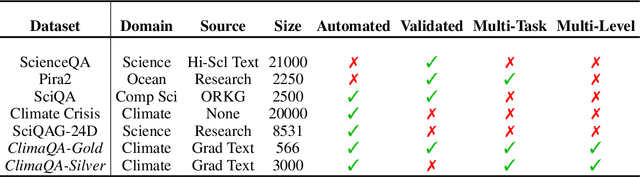

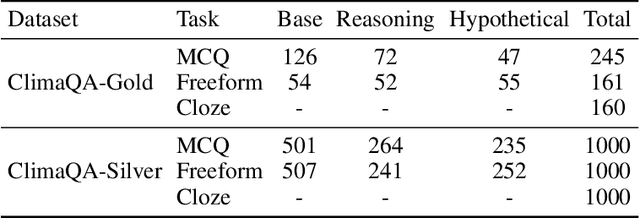
The use of foundation models in climate science has recently gained significant attention. However, a critical issue remains: the lack of a comprehensive evaluation framework capable of assessing the quality and scientific validity of model outputs. To address this issue, we develop ClimaGen (Climate QA Generator), an automated algorithmic framework that generates question-answer pairs from graduate textbooks with climate scientists in the loop. As a result, we present ClimaQA-Gold, an expert-annotated benchmark dataset alongside ClimaQA-Silver, a large-scale, comprehensive synthetic QA dataset for climate science. Finally, we develop evaluation strategies and compare different Large Language Models (LLMs) on our benchmarks. Our results offer novel insights into various approaches used to enhance climate foundation models.
Accuracy on the wrong line: On the pitfalls of noisy data for out-of-distribution generalisation
Jun 27, 2024"Accuracy-on-the-line" is a widely observed phenomenon in machine learning, where a model's accuracy on in-distribution (ID) and out-of-distribution (OOD) data is positively correlated across different hyperparameters and data configurations. But when does this useful relationship break down? In this work, we explore its robustness. The key observation is that noisy data and the presence of nuisance features can be sufficient to shatter the Accuracy-on-the-line phenomenon. In these cases, ID and OOD accuracy can become negatively correlated, leading to "Accuracy-on-the-wrong-line". This phenomenon can also occur in the presence of spurious (shortcut) features, which tend to overshadow the more complex signal (core, non-spurious) features, resulting in a large nuisance feature space. Moreover, scaling to larger datasets does not mitigate this undesirable behavior and may even exacerbate it. We formally prove a lower bound on Out-of-distribution (OOD) error in a linear classification model, characterizing the conditions on the noise and nuisance features for a large OOD error. We finally demonstrate this phenomenon across both synthetic and real datasets with noisy data and nuisance features.
Faster Sampling without Isoperimetry via Diffusion-based Monte Carlo
Jan 12, 2024



To sample from a general target distribution $p_*\propto e^{-f_*}$ beyond the isoperimetric condition, Huang et al. (2023) proposed to perform sampling through reverse diffusion, giving rise to Diffusion-based Monte Carlo (DMC). Specifically, DMC follows the reverse SDE of a diffusion process that transforms the target distribution to the standard Gaussian, utilizing a non-parametric score estimation. However, the original DMC algorithm encountered high gradient complexity, resulting in an exponential dependency on the error tolerance $\epsilon$ of the obtained samples. In this paper, we demonstrate that the high complexity of DMC originates from its redundant design of score estimation, and proposed a more efficient algorithm, called RS-DMC, based on a novel recursive score estimation method. In particular, we first divide the entire diffusion process into multiple segments and then formulate the score estimation step (at any time step) as a series of interconnected mean estimation and sampling subproblems accordingly, which are correlated in a recursive manner. Importantly, we show that with a proper design of the segment decomposition, all sampling subproblems will only need to tackle a strongly log-concave distribution, which can be very efficient to solve using the Langevin-based samplers with a provably rapid convergence rate. As a result, we prove that the gradient complexity of RS-DMC only has a quasi-polynomial dependency on $\epsilon$, which significantly improves exponential gradient complexity in Huang et al. (2023). Furthermore, under commonly used dissipative conditions, our algorithm is provably much faster than the popular Langevin-based algorithms. Our algorithm design and theoretical framework illuminate a novel direction for addressing sampling problems, which could be of broader applicability in the community.
Tractable MCMC for Private Learning with Pure and Gaussian Differential Privacy
Oct 23, 2023Posterior sampling, i.e., exponential mechanism to sample from the posterior distribution, provides $\varepsilon$-pure differential privacy (DP) guarantees and does not suffer from potentially unbounded privacy breach introduced by $(\varepsilon,\delta)$-approximate DP. In practice, however, one needs to apply approximate sampling methods such as Markov chain Monte Carlo (MCMC), thus re-introducing the unappealing $\delta$-approximation error into the privacy guarantees. To bridge this gap, we propose the Approximate SAample Perturbation (abbr. ASAP) algorithm which perturbs an MCMC sample with noise proportional to its Wasserstein-infinity ($W_\infty$) distance from a reference distribution that satisfies pure DP or pure Gaussian DP (i.e., $\delta=0$). We then leverage a Metropolis-Hastings algorithm to generate the sample and prove that the algorithm converges in W$_\infty$ distance. We show that by combining our new techniques with a careful localization step, we obtain the first nearly linear-time algorithm that achieves the optimal rates in the DP-ERM problem with strongly convex and smooth losses.
Linear Convergence of Black-Box Variational Inference: Should We Stick the Landing?
Jul 27, 2023

We prove that black-box variational inference (BBVI) with control variates, particularly the sticking-the-landing (STL) estimator, converges at a geometric (traditionally called "linear") rate under perfect variational family specification. In particular, we prove a quadratic bound on the gradient variance of the STL estimator, one which encompasses misspecified variational families. Combined with previous works on the quadratic variance condition, this directly implies convergence of BBVI with the use of projected stochastic gradient descent. We also improve existing analysis on the regular closed-form entropy gradient estimators, which enables comparison against the STL estimator and provides explicit non-asymptotic complexity guarantees for both.
Monte Carlo Sampling without Isoperimetry: A Reverse Diffusion Approach
Jul 05, 2023



The efficacy of modern generative models is commonly contingent upon the precision of score estimation along the diffusion path, with a focus on diffusion models and their ability to generate high-quality data samples. This study delves into the potentialities of posterior sampling through reverse diffusion. An examination of the sampling literature reveals that score estimation can be transformed into a mean estimation problem via the decomposition of the transition kernel. By estimating the mean of the auxiliary distribution, the reverse diffusion process can give rise to a novel posterior sampling algorithm, which diverges from traditional gradient-based Markov Chain Monte Carlo (MCMC) methods. We provide the convergence analysis in total variation distance and demonstrate that the isoperimetric dependency of the proposed algorithm is comparatively lower than that observed in conventional MCMC techniques, which justifies the superior performance for high dimensional sampling with error tolerance. Our analytical framework offers fresh perspectives on the complexity of score estimation at various time points, as denoted by the properties of the auxiliary distribution.