 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGovernance-Aware Agent Telemetry for Closed-Loop Enforcement in Multi-Agent AI Systems
Apr 06, 2026Enterprise multi-agent AI systems produce thousands of inter-agent interactions per hour, yet existing observability tools capture these dependencies without enforcing anything. OpenTelemetry and Langfuse collect telemetry but treat governance as a downstream analytics concern, not a real-time enforcement target. The result is an "observe-but-do-not-act" gap where policy violations are detected only after damage is done. We present Governance-Aware Agent Telemetry (GAAT), a reference architecture that closes the loop between telemetry collection and automated policy enforcement for multi-agent systems. GAAT introduces (1) a Governance Telemetry Schema (GTS) extending OpenTelemetry with governance attributes; (2) a real-time policy violation detection engine using OPA-compatible declarative rules under sub-200 ms latency; (3) a Governance Enforcement Bus (GEB) with graduated interventions; and (4) a Trusted Telemetry Plane with cryptographic provenance.
AI Telephone Surveying: Automating Quantitative Data Collection with an AI Interviewer
Jul 23, 2025With the rise of voice-enabled artificial intelligence (AI) systems, quantitative survey researchers have access to a new data-collection mode: AI telephone surveying. By using AI to conduct phone interviews, researchers can scale quantitative studies while balancing the dual goals of human-like interactivity and methodological rigor. Unlike earlier efforts that used interactive voice response (IVR) technology to automate these surveys, voice AI enables a more natural and adaptive respondent experience as it is more robust to interruptions, corrections, and other idiosyncrasies of human speech. We built and tested an AI system to conduct quantitative surveys based on large language models (LLM), automatic speech recognition (ASR), and speech synthesis technologies. The system was specifically designed for quantitative research, and strictly adhered to research best practices like question order randomization, answer order randomization, and exact wording. To validate the system's effectiveness, we deployed it to conduct two pilot surveys with the SSRS Opinion Panel and followed-up with a separate human-administered survey to assess respondent experiences. We measured three key metrics: the survey completion rates, break-off rates, and respondent satisfaction scores. Our results suggest that shorter instruments and more responsive AI interviewers may contribute to improvements across all three metrics studied.
Multi-Step Consistency Models: Fast Generation with Theoretical Guarantees
May 02, 2025Consistency models have recently emerged as a compelling alternative to traditional SDE based diffusion models, offering a significant acceleration in generation by producing high quality samples in very few steps. Despite their empirical success, a proper theoretic justification for their speed up is still lacking. In this work, we provide the analysis which bridges this gap, showing that given a consistency model which can map the input at a given time to arbitrary timestamps along the reverse trajectory, one can achieve KL divergence of order $ O(\varepsilon^2) $ using only $ O\left(\log\left(\frac{d}{\varepsilon}\right)\right) $ iterations with constant step size, where d is the data dimension. Additionally, under minimal assumptions on the data distribution an increasingly common setting in recent diffusion model analyses we show that a similar KL convergence guarantee can be obtained, with the number of steps scaling as $ O\left(d \log\left(\frac{d}{\varepsilon}\right)\right) $. Going further, we also provide a theoretical analysis for estimation of such consistency models, concluding that accurate learning is feasible using small discretization steps, both in smooth and non smooth settings. Notably, our results for the non smooth case yield best in class convergence rates compared to existing SDE or ODE based analyses under minimal assumptions.
Bayesian Quantum Orthogonal Neural Networks for Anomaly Detection
Apr 25, 2025Identification of defects or anomalies in 3D objects is a crucial task to ensure correct functionality. In this work, we combine Bayesian learning with recent developments in quantum and quantum-inspired machine learning, specifically orthogonal neural networks, to tackle this anomaly detection problem for an industrially relevant use case. Bayesian learning enables uncertainty quantification of predictions, while orthogonality in weight matrices enables smooth training. We develop orthogonal (quantum) versions of 3D convolutional neural networks and show that these models can successfully detect anomalies in 3D objects. To test the feasibility of incorporating quantum computers into a quantum-enhanced anomaly detection pipeline, we perform hardware experiments with our models on IBM's 127-qubit Brisbane device, testing the effect of noise and limited measurement shots.
Training-efficient density quantum machine learning
May 30, 2024Quantum machine learning requires powerful, flexible and efficiently trainable models to be successful in solving challenging problems. In this work, we present density quantum neural networks, a learning model incorporating randomisation over a set of trainable unitaries. These models generalise quantum neural networks using parameterised quantum circuits, and allow a trade-off between expressibility and efficient trainability, particularly on quantum hardware. We demonstrate the flexibility of the formalism by applying it to two recently proposed model families. The first are commuting-block quantum neural networks (QNNs) which are efficiently trainable but may be limited in expressibility. The second are orthogonal (Hamming-weight preserving) quantum neural networks which provide well-defined and interpretable transformations on data but are challenging to train at scale on quantum devices. Density commuting QNNs improve capacity with minimal gradient complexity overhead, and density orthogonal neural networks admit a quadratic-to-constant gradient query advantage with minimal to no performance loss. We conduct numerical experiments on synthetic translationally invariant data and MNIST image data with hyperparameter optimisation to support our findings. Finally, we discuss the connection to post-variational quantum neural networks, measurement-based quantum machine learning and the dropout mechanism.
Improving Generalization via Meta-Learning on Hard Samples
Mar 29, 2024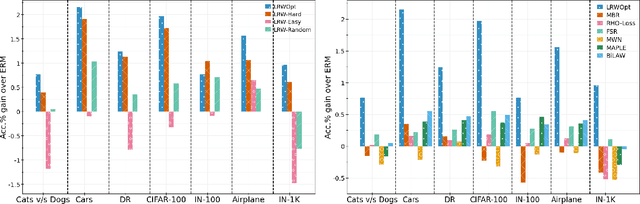

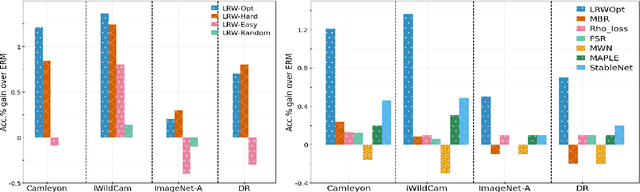
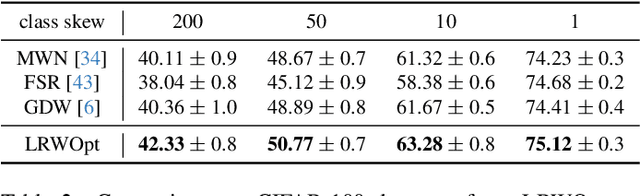
Learned reweighting (LRW) approaches to supervised learning use an optimization criterion to assign weights for training instances, in order to maximize performance on a representative validation dataset. We pose and formalize the problem of optimized selection of the validation set used in LRW training, to improve classifier generalization. In particular, we show that using hard-to-classify instances in the validation set has both a theoretical connection to, and strong empirical evidence of generalization. We provide an efficient algorithm for training this meta-optimized model, as well as a simple train-twice heuristic for careful comparative study. We demonstrate that LRW with easy validation data performs consistently worse than LRW with hard validation data, establishing the validity of our meta-optimization problem. Our proposed algorithm outperforms a wide range of baselines on a range of datasets and domain shift challenges (Imagenet-1K, CIFAR-100, Clothing-1M, CAMELYON, WILDS, etc.), with ~1% gains using VIT-B on Imagenet. We also show that using naturally hard examples for validation (Imagenet-R / Imagenet-A) in LRW training for Imagenet improves performance on both clean and naturally hard test instances by 1-2%. Secondary analyses show that using hard validation data in an LRW framework improves margins on test data, hinting at the mechanism underlying our empirical gains. We believe this work opens up new research directions for the meta-optimization of meta-learning in a supervised learning context.
Learning Robust Multi-Scale Representation for Neural Radiance Fields from Unposed Images
Nov 08, 2023We introduce an improved solution to the neural image-based rendering problem in computer vision. Given a set of images taken from a freely moving camera at train time, the proposed approach could synthesize a realistic image of the scene from a novel viewpoint at test time. The key ideas presented in this paper are (i) Recovering accurate camera parameters via a robust pipeline from unposed day-to-day images is equally crucial in neural novel view synthesis problem; (ii) It is rather more practical to model object's content at different resolutions since dramatic camera motion is highly likely in day-to-day unposed images. To incorporate the key ideas, we leverage the fundamentals of scene rigidity, multi-scale neural scene representation, and single-image depth prediction. Concretely, the proposed approach makes the camera parameters as learnable in a neural fields-based modeling framework. By assuming per view depth prediction is given up to scale, we constrain the relative pose between successive frames. From the relative poses, absolute camera pose estimation is modeled via a graph-neural network-based multiple motion averaging within the multi-scale neural-fields network, leading to a single loss function. Optimizing the introduced loss function provides camera intrinsic, extrinsic, and image rendering from unposed images. We demonstrate, with examples, that for a unified framework to accurately model multiscale neural scene representation from day-to-day acquired unposed multi-view images, it is equally essential to have precise camera-pose estimates within the scene representation framework. Without considering robustness measures in the camera pose estimation pipeline, modeling for multi-scale aliasing artifacts can be counterproductive. We present extensive experiments on several benchmark datasets to demonstrate the suitability of our approach.
Efficiently Robustify Pre-trained Models
Sep 14, 2023A recent trend in deep learning algorithms has been towards training large scale models, having high parameter count and trained on big dataset. However, robustness of such large scale models towards real-world settings is still a less-explored topic. In this work, we first benchmark the performance of these models under different perturbations and datasets thereby representing real-world shifts, and highlight their degrading performance under these shifts. We then discuss on how complete model fine-tuning based existing robustification schemes might not be a scalable option given very large scale networks and can also lead them to forget some of the desired characterstics. Finally, we propose a simple and cost-effective method to solve this problem, inspired by knowledge transfer literature. It involves robustifying smaller models, at a lower computation cost, and then use them as teachers to tune a fraction of these large scale networks, reducing the overall computational overhead. We evaluate our proposed method under various vision perturbations including ImageNet-C,R,S,A datasets and also for transfer learning, zero-shot evaluation setups on different datasets. Benchmark results show that our method is able to induce robustness to these large scale models efficiently, requiring significantly lower time and also preserves the transfer learning, zero-shot properties of the original model which none of the existing methods are able to achieve.
Enhanced Stable View Synthesis
Mar 30, 2023We introduce an approach to enhance the novel view synthesis from images taken from a freely moving camera. The introduced approach focuses on outdoor scenes where recovering accurate geometric scaffold and camera pose is challenging, leading to inferior results using the state-of-the-art stable view synthesis (SVS) method. SVS and related methods fail for outdoor scenes primarily due to (i) over-relying on the multiview stereo (MVS) for geometric scaffold recovery and (ii) assuming COLMAP computed camera poses as the best possible estimates, despite it being well-studied that MVS 3D reconstruction accuracy is limited to scene disparity and camera-pose accuracy is sensitive to key-point correspondence selection. This work proposes a principled way to enhance novel view synthesis solutions drawing inspiration from the basics of multiple view geometry. By leveraging the complementary behavior of MVS and monocular depth, we arrive at a better scene depth per view for nearby and far points, respectively. Moreover, our approach jointly refines camera poses with image-based rendering via multiple rotation averaging graph optimization. The recovered scene depth and the camera-pose help better view-dependent on-surface feature aggregation of the entire scene. Extensive evaluation of our approach on the popular benchmark dataset, such as Tanks and Temples, shows substantial improvement in view synthesis results compared to the prior art. For instance, our method shows 1.5 dB of PSNR improvement on the Tank and Temples. Similar statistics are observed when tested on other benchmark datasets such as FVS, Mip-NeRF 360, and DTU.
Learning on non-stationary data with re-weighting
Dec 12, 2022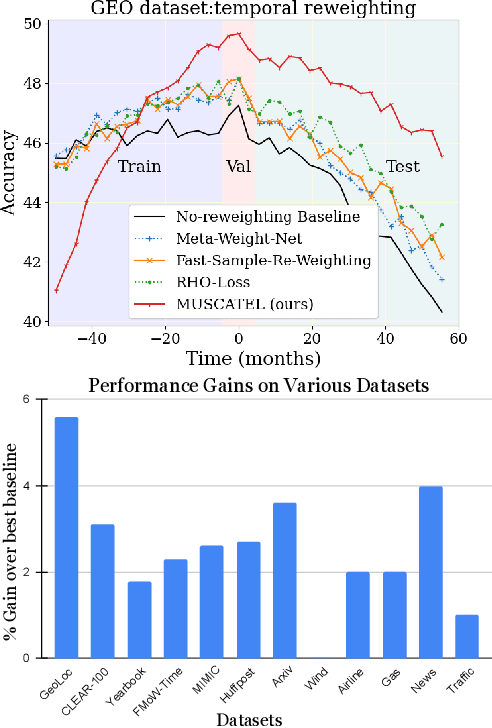
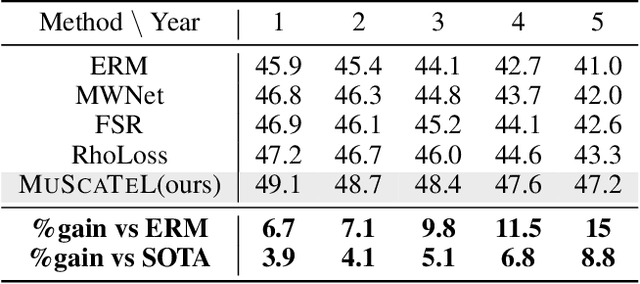
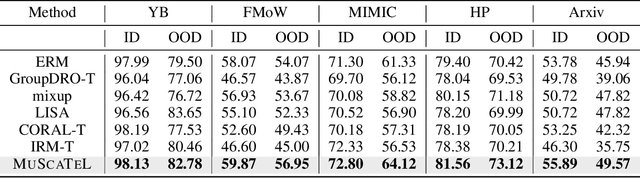
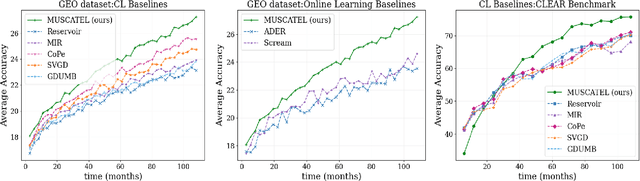
Many real-world learning scenarios face the challenge of slow concept drift, where data distributions change gradually over time. In this setting, we pose the problem of learning temporally sensitive importance weights for training data, in order to optimize predictive accuracy. We propose a class of temporal reweighting functions that can capture multiple timescales of change in the data, as well as instance-specific characteristics. We formulate a bi-level optimization criterion, and an associated meta-learning algorithm, by which these weights can be learned. In particular, our formulation trains an auxiliary network to output weights as a function of training instances, thereby compactly representing the instance weights. We validate our temporal reweighting scheme on a large real-world dataset of 39M images spread over a 9 year period. Our extensive experiments demonstrate the necessity of instance-based temporal reweighting in the dataset, and achieve significant improvements to classical batch-learning approaches. Further, our proposal easily generalizes to a streaming setting and shows significant gains compared to recent continual learning methods.