 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Archival Camera Virtualization for Sports and Visual Performances
Feb 16, 2026Camera virtualization -- an emerging solution to novel view synthesis -- holds transformative potential for visual entertainment, live performances, and sports broadcasting by enabling the generation of photorealistic images from novel viewpoints using images from a limited set of calibrated multiple static physical cameras. Despite recent advances, achieving spatially and temporally coherent and photorealistic rendering of dynamic scenes with efficient time-archival capabilities, particularly in fast-paced sports and stage performances, remains challenging for existing approaches. Recent methods based on 3D Gaussian Splatting (3DGS) for dynamic scenes could offer real-time view-synthesis results. Yet, they are hindered by their dependence on accurate 3D point clouds from the structure-from-motion method and their inability to handle large, non-rigid, rapid motions of different subjects (e.g., flips, jumps, articulations, sudden player-to-player transitions). Moreover, independent motions of multiple subjects can break the Gaussian-tracking assumptions commonly used in 4DGS, ST-GS, and other dynamic splatting variants. This paper advocates reconsidering a neural volume rendering formulation for camera virtualization and efficient time-archival capabilities, making it useful for sports broadcasting and related applications. By modeling a dynamic scene as rigid transformations across multiple synchronized camera views at a given time, our method performs neural representation learning, providing enhanced visual rendering quality at test time. A key contribution of our approach is its support for time-archival, i.e., users can revisit any past temporal instance of a dynamic scene and can perform novel view synthesis, enabling retrospective rendering for replay, analysis, and archival of live events, a functionality absent in existing neural rendering approaches and novel view synthesis...
Interactive Video Generation via Domain Adaptation
May 30, 2025Text-conditioned diffusion models have emerged as powerful tools for high-quality video generation. However, enabling Interactive Video Generation (IVG), where users control motion elements such as object trajectory, remains challenging. Recent training-free approaches introduce attention masking to guide trajectory, but this often degrades perceptual quality. We identify two key failure modes in these methods, both of which we interpret as domain shift problems, and propose solutions inspired by domain adaptation. First, we attribute the perceptual degradation to internal covariate shift induced by attention masking, as pretrained models are not trained to handle masked attention. To address this, we propose mask normalization, a pre-normalization layer designed to mitigate this shift via distribution matching. Second, we address initialization gap, where the randomly sampled initial noise does not align with IVG conditioning, by introducing a temporal intrinsic diffusion prior that enforces spatio-temporal consistency at each denoising step. Extensive qualitative and quantitative evaluations demonstrate that mask normalization and temporal intrinsic denoising improve both perceptual quality and trajectory control over the existing state-of-the-art IVG techniques.
Next-Future: Sample-Efficient Policy Learning for Robotic-Arm Tasks
Apr 15, 2025



Hindsight Experience Replay (HER) is widely regarded as the state-of-the-art algorithm for achieving sample-efficient multi-goal reinforcement learning (RL) in robotic manipulation tasks with binary rewards. HER facilitates learning from failed attempts by replaying trajectories with redefined goals. However, it relies on a heuristic-based replay method that lacks a principled framework. To address this limitation, we introduce a novel replay strategy, "Next-Future", which focuses on rewarding single-step transitions. This approach significantly enhances sample efficiency and accuracy in learning multi-goal Markov decision processes (MDPs), particularly under stringent accuracy requirements -- a critical aspect for performing complex and precise robotic-arm tasks. We demonstrate the efficacy of our method by highlighting how single-step learning enables improved value approximation within the multi-goal RL framework. The performance of the proposed replay strategy is evaluated across eight challenging robotic manipulation tasks, using ten random seeds for training. Our results indicate substantial improvements in sample efficiency for seven out of eight tasks and higher success rates in six tasks. Furthermore, real-world experiments validate the practical feasibility of the learned policies, demonstrating the potential of "Next-Future" in solving complex robotic-arm tasks.
Evidential Transformers for Improved Image Retrieval
Sep 02, 2024We introduce the Evidential Transformer, an uncertainty-driven transformer model for improved and robust image retrieval. In this paper, we make several contributions to content-based image retrieval (CBIR). We incorporate probabilistic methods into image retrieval, achieving robust and reliable results, with evidential classification surpassing traditional training based on multiclass classification as a baseline for deep metric learning. Furthermore, we improve the state-of-the-art retrieval results on several datasets by leveraging the Global Context Vision Transformer (GC ViT) architecture. Our experimental results consistently demonstrate the reliability of our approach, setting a new benchmark in CBIR in all test settings on the Stanford Online Products (SOP) and CUB-200-2011 datasets.
Stereo Risk: A Continuous Modeling Approach to Stereo Matching
Jul 03, 2024We introduce Stereo Risk, a new deep-learning approach to solve the classical stereo-matching problem in computer vision. As it is well-known that stereo matching boils down to a per-pixel disparity estimation problem, the popular state-of-the-art stereo-matching approaches widely rely on regressing the scene disparity values, yet via discretization of scene disparity values. Such discretization often fails to capture the nuanced, continuous nature of scene depth. Stereo Risk departs from the conventional discretization approach by formulating the scene disparity as an optimal solution to a continuous risk minimization problem, hence the name "stereo risk". We demonstrate that $L^1$ minimization of the proposed continuous risk function enhances stereo-matching performance for deep networks, particularly for disparities with multi-modal probability distributions. Furthermore, to enable the end-to-end network training of the non-differentiable $L^1$ risk optimization, we exploited the implicit function theorem, ensuring a fully differentiable network. A comprehensive analysis demonstrates our method's theoretical soundness and superior performance over the state-of-the-art methods across various benchmark datasets, including KITTI 2012, KITTI 2015, ETH3D, SceneFlow, and Middlebury 2014.
ICGNet: A Unified Approach for Instance-Centric Grasping
Jan 18, 2024



Accurate grasping is the key to several robotic tasks including assembly and household robotics. Executing a successful grasp in a cluttered environment requires multiple levels of scene understanding: First, the robot needs to analyze the geometric properties of individual objects to find feasible grasps. These grasps need to be compliant with the local object geometry. Second, for each proposed grasp, the robot needs to reason about the interactions with other objects in the scene. Finally, the robot must compute a collision-free grasp trajectory while taking into account the geometry of the target object. Most grasp detection algorithms directly predict grasp poses in a monolithic fashion, which does not capture the composability of the environment. In this paper, we introduce an end-to-end architecture for object-centric grasping. The method uses pointcloud data from a single arbitrary viewing direction as an input and generates an instance-centric representation for each partially observed object in the scene. This representation is further used for object reconstruction and grasp detection in cluttered table-top scenes. We show the effectiveness of the proposed method by extensively evaluating it against state-of-the-art methods on synthetic datasets, indicating superior performance for grasping and reconstruction. Additionally, we demonstrate real-world applicability by decluttering scenes with varying numbers of objects.
Learning Robust Multi-Scale Representation for Neural Radiance Fields from Unposed Images
Nov 08, 2023We introduce an improved solution to the neural image-based rendering problem in computer vision. Given a set of images taken from a freely moving camera at train time, the proposed approach could synthesize a realistic image of the scene from a novel viewpoint at test time. The key ideas presented in this paper are (i) Recovering accurate camera parameters via a robust pipeline from unposed day-to-day images is equally crucial in neural novel view synthesis problem; (ii) It is rather more practical to model object's content at different resolutions since dramatic camera motion is highly likely in day-to-day unposed images. To incorporate the key ideas, we leverage the fundamentals of scene rigidity, multi-scale neural scene representation, and single-image depth prediction. Concretely, the proposed approach makes the camera parameters as learnable in a neural fields-based modeling framework. By assuming per view depth prediction is given up to scale, we constrain the relative pose between successive frames. From the relative poses, absolute camera pose estimation is modeled via a graph-neural network-based multiple motion averaging within the multi-scale neural-fields network, leading to a single loss function. Optimizing the introduced loss function provides camera intrinsic, extrinsic, and image rendering from unposed images. We demonstrate, with examples, that for a unified framework to accurately model multiscale neural scene representation from day-to-day acquired unposed multi-view images, it is equally essential to have precise camera-pose estimates within the scene representation framework. Without considering robustness measures in the camera pose estimation pipeline, modeling for multi-scale aliasing artifacts can be counterproductive. We present extensive experiments on several benchmark datasets to demonstrate the suitability of our approach.
How To Not Train Your Dragon: Training-free Embodied Object Goal Navigation with Semantic Frontiers
May 26, 2023



Object goal navigation is an important problem in Embodied AI that involves guiding the agent to navigate to an instance of the object category in an unknown environment -- typically an indoor scene. Unfortunately, current state-of-the-art methods for this problem rely heavily on data-driven approaches, \eg, end-to-end reinforcement learning, imitation learning, and others. Moreover, such methods are typically costly to train and difficult to debug, leading to a lack of transferability and explainability. Inspired by recent successes in combining classical and learning methods, we present a modular and training-free solution, which embraces more classic approaches, to tackle the object goal navigation problem. Our method builds a structured scene representation based on the classic visual simultaneous localization and mapping (V-SLAM) framework. We then inject semantics into geometric-based frontier exploration to reason about promising areas to search for a goal object. Our structured scene representation comprises a 2D occupancy map, semantic point cloud, and spatial scene graph. Our method propagates semantics on the scene graphs based on language priors and scene statistics to introduce semantic knowledge to the geometric frontiers. With injected semantic priors, the agent can reason about the most promising frontier to explore. The proposed pipeline shows strong experimental performance for object goal navigation on the Gibson benchmark dataset, outperforming the previous state-of-the-art. We also perform comprehensive ablation studies to identify the current bottleneck in the object navigation task.
Neural Implicit Dense Semantic SLAM
May 09, 2023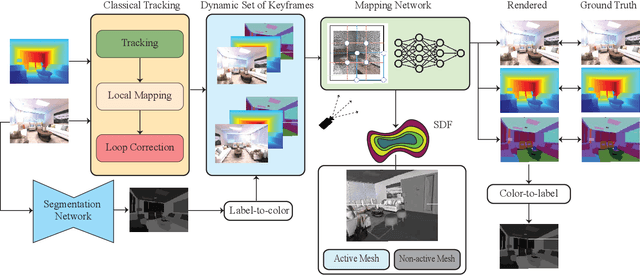
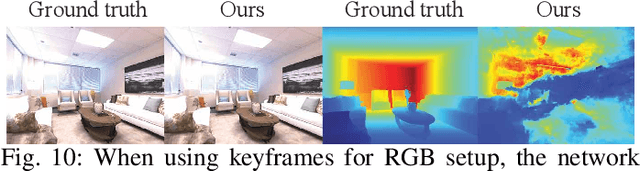
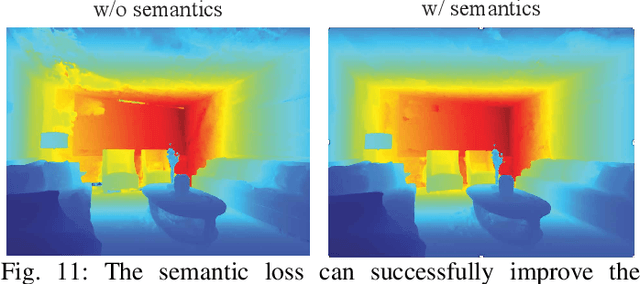

Visual Simultaneous Localization and Mapping (vSLAM) is a widely used technique in robotics and computer vision that enables a robot to create a map of an unfamiliar environment using a camera sensor while simultaneously tracking its position over time. In this paper, we propose a novel RGBD vSLAM algorithm that can learn a memory-efficient, dense 3D geometry, and semantic segmentation of an indoor scene in an online manner. Our pipeline combines classical 3D vision-based tracking and loop closing with neural fields-based mapping. The mapping network learns the SDF of the scene as well as RGB, depth, and semantic maps of any novel view using only a set of keyframes. Additionally, we extend our pipeline to large scenes by using multiple local mapping networks. Extensive experiments on well-known benchmark datasets confirm that our approach provides robust tracking, mapping, and semantic labeling even with noisy, sparse, or no input depth. Overall, our proposed algorithm can greatly enhance scene perception and assist with a range of robot control problems.
Quantum Annealing for Single Image Super-Resolution
Apr 18, 2023

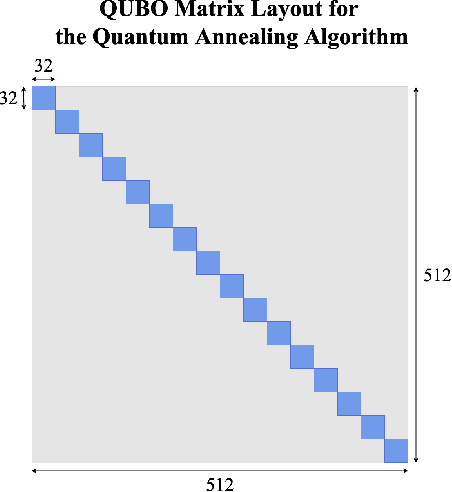

This paper proposes a quantum computing-based algorithm to solve the single image super-resolution (SISR) problem. One of the well-known classical approaches for SISR relies on the well-established patch-wise sparse modeling of the problem. Yet, this field's current state of affairs is that deep neural networks (DNNs) have demonstrated far superior results than traditional approaches. Nevertheless, quantum computing is expected to become increasingly prominent for machine learning problems soon. As a result, in this work, we take the privilege to perform an early exploration of applying a quantum computing algorithm to this important image enhancement problem, i.e., SISR. Among the two paradigms of quantum computing, namely universal gate quantum computing and adiabatic quantum computing (AQC), the latter has been successfully applied to practical computer vision problems, in which quantum parallelism has been exploited to solve combinatorial optimization efficiently. This work demonstrates formulating quantum SISR as a sparse coding optimization problem, which is solved using quantum annealers accessed via the D-Wave Leap platform. The proposed AQC-based algorithm is demonstrated to achieve improved speed-up over a classical analog while maintaining comparable SISR accuracy.