 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense Force Estimation with an Event-based Optical Tactile Sensor
Jun 08, 2026Humans rely on spatially dense, geometry and force-aware tactile feedback at high temporal resolution for dexterous manipulation. While vision-based tactile sensors enable dense force estimation, they are limited by camera frame rates, motion blur, and data bandwidth. Event-based optical tactile sensors offer an attractive alternative with microsecond temporal resolution and low motion blur, but existing methods are restricted to predicting only net forces. We introduce the first framework for dense 3D force field reconstruction using event-based optical tactile sensors. Our approach estimates 3D surface displacements from event data and maps them to forces via the inverse Finite Elements Method (iFEM). Shear displacements are recovered through the proposed event-based marker tracking algorithm, while normal displacements are predicted by a convolutional neural network trained on a collected dataset of synchronized force-displacement-event data. Experiments demonstrate accurate reconstruction of physically grounded forces, achieving a mean absolute error of (0.14 N, 0.10 N, 0.93 N) over force ranges up to (4 N, 4 N, 20 N), while operating at an average of 100 Hz. This work constitutes a first step toward enabling dense force feedback for high-frequency control in robotic grasping and dexterous manipulation.
VR-DAgger: Immersive VR for Dexterous Data Collection and Uncertainty-Guided On-Policy Correction
May 26, 2026Learning from demonstrations is effective for robotic manipulation, but collecting sufficient task-specific data remains a major bottleneck. Under distribution shift, small errors compound, performance degrades, and expert time is often spent on redundant, low-value corrections instead of the few critical failure cases.
FunFact: Building Probabilistic Functional 3D Scene Graphs via Factor-Graph Reasoning
Apr 04, 2026Recent work in 3D scene understanding is moving beyond purely spatial analysis toward functional scene understanding. However, existing methods often consider functional relationships between object pairs in isolation, failing to capture the scene-wide interdependence that humans use to resolve ambiguity. We introduce FunFact, a framework for constructing probabilistic open-vocabulary functional 3D scene graphs from posed RGB-D images. FunFact first builds an object- and part-centric 3D map and uses foundation models to propose semantically plausible functional relations. These candidates are converted into factor graph variables and constrained by both LLM-derived common-sense priors and geometric priors. This formulation enables joint probabilistic inference over all functional edges and their marginals, yielding substantially better calibrated confidence scores. To benchmark this setting, we introduce FunThor, a synthetic dataset based on AI2-THOR with part-level geometry and rule-based functional annotations. Experiments on SceneFun3D, FunGraph3D, and FunThor show that FunFact improves node and relation discovery recall and significantly reduces calibration error for ambiguous relations, highlighting the benefits of holistic probabilistic modeling for functional scene understanding. See our project page at https://funfact-scenegraph.github.io/
What Matters for Simulation to Online Reinforcement Learning on Real Robots
Feb 23, 2026We investigate what specific design choices enable successful online reinforcement learning (RL) on physical robots. Across 100 real-world training runs on three distinct robotic platforms, we systematically ablate algorithmic, systems, and experimental decisions that are typically left implicit in prior work. We find that some widely used defaults can be harmful, while a set of robust, readily adopted design choices within standard RL practice yield stable learning across tasks and hardware. These results provide the first large-sample empirical study of such design choices, enabling practitioners to deploy online RL with lower engineering effort.
DexEvolve: Evolutionary Optimization for Robust and Diverse Dexterous Grasp Synthesis
Feb 16, 2026Dexterous grasping is fundamental to robotics, yet data-driven grasp prediction heavily relies on large, diverse datasets that are costly to generate and typically limited to a narrow set of gripper morphologies. Analytical grasp synthesis can be used to scale data collection, but necessary simplifying assumptions often yield physically infeasible grasps that need to be filtered in high-fidelity simulators, significantly reducing the total number of grasps and their diversity. We propose a scalable generate-and-refine pipeline for synthesizing large-scale, diverse, and physically feasible grasps. Instead of using high-fidelity simulators solely for verification and filtering, we leverage them as an optimization stage that continuously improves grasp quality without discarding precomputed candidates. More specifically, we initialize an evolutionary search with a seed set of analytically generated, potentially suboptimal grasps. We then refine these proposals directly in a high-fidelity simulator (Isaac Sim) using an asynchronous, gradient-free evolutionary algorithm, improving stability while maintaining diversity. In addition, this refinement stage can be guided toward human preferences and/or domain-specific quality metrics without requiring a differentiable objective. We further distill the refined grasp distribution into a diffusion model for robust real-world deployment, and highlight the role of diversity for both effective training and during deployment. Experiments on a newly introduced Handles dataset and a DexGraspNet subset demonstrate that our approach achieves over 120 distinct stable grasps per object (a 1.7-6x improvement over unrefined analytical methods) while outperforming diffusion-based alternatives by 46-60\% in unique grasp coverage.
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
GraspQP: Differentiable Optimization of Force Closure for Diverse and Robust Dexterous Grasping
Aug 20, 2025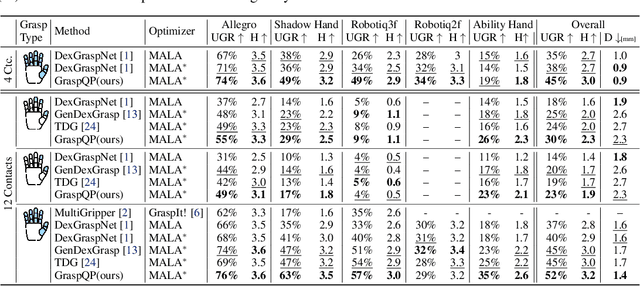
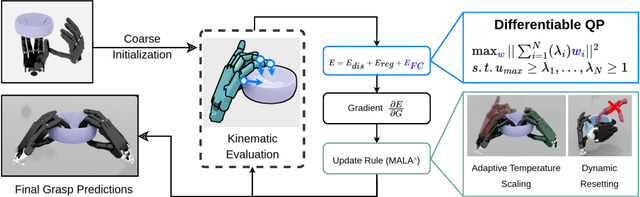


Dexterous robotic hands enable versatile interactions due to the flexibility and adaptability of multi-fingered designs, allowing for a wide range of task-specific grasp configurations in diverse environments. However, to fully exploit the capabilities of dexterous hands, access to diverse and high-quality grasp data is essential -- whether for developing grasp prediction models from point clouds, training manipulation policies, or supporting high-level task planning with broader action options. Existing approaches for dataset generation typically rely on sampling-based algorithms or simplified force-closure analysis, which tend to converge to power grasps and often exhibit limited diversity. In this work, we propose a method to synthesize large-scale, diverse, and physically feasible grasps that extend beyond simple power grasps to include refined manipulations, such as pinches and tri-finger precision grasps. We introduce a rigorous, differentiable energy formulation of force closure, implicitly defined through a Quadratic Program (QP). Additionally, we present an adjusted optimization method (MALA*) that improves performance by dynamically rejecting gradient steps based on the distribution of energy values across all samples. We extensively evaluate our approach and demonstrate significant improvements in both grasp diversity and the stability of final grasp predictions. Finally, we provide a new, large-scale grasp dataset for 5,700 objects from DexGraspNet, comprising five different grippers and three distinct grasp types. Dataset and Code:https://graspqp.github.io/
Experience is the Best Teacher: Grounding VLMs for Robotics through Self-Generated Memory
Jul 22, 2025Vision-language models (VLMs) have been widely adopted in robotics to enable autonomous planning. However, grounding VLMs, originally trained on internet data, to diverse real-world robots remains a challenge. This paper presents ExpTeach, a framework that grounds VLMs to physical robots by building a self-generated memory of real-world experiences. In ExpTeach, the VLM autonomously plans actions, verifies outcomes, reflects on failures, and adapts robot behaviors in a closed loop. The self-generated experiences during this process are then summarized into a long-term memory, enabling retrieval of learned knowledge to guide future tasks via retrieval-augmented generation (RAG). Additionally, ExpTeach enhances the spatial understanding of VLMs with an on-demand image annotation module. In experiments, we show that reflection improves success rates from 36% to 84% on four challenging robotic tasks and observe the emergence of intelligent object interactions, including creative tool use. Across extensive tests on 12 real-world scenarios (including eight unseen ones), we find that grounding with long-term memory boosts single-trial success rates from 22% to 80%, demonstrating the effectiveness and generalizability of ExpTeach.
Spot-On: A Mixed Reality Interface for Multi-Robot Cooperation
May 28, 2025


Recent progress in mixed reality (MR) and robotics is enabling increasingly sophisticated forms of human-robot collaboration. Building on these developments, we introduce a novel MR framework that allows multiple quadruped robots to operate in semantically diverse environments via a MR interface. Our system supports collaborative tasks involving drawers, swing doors, and higher-level infrastructure such as light switches. A comprehensive user study verifies both the design and usability of our app, with participants giving a "good" or "very good" rating in almost all cases. Overall, our approach provides an effective and intuitive framework for MR-based multi-robot collaboration in complex, real-world scenarios.
Next-Future: Sample-Efficient Policy Learning for Robotic-Arm Tasks
Apr 15, 2025



Hindsight Experience Replay (HER) is widely regarded as the state-of-the-art algorithm for achieving sample-efficient multi-goal reinforcement learning (RL) in robotic manipulation tasks with binary rewards. HER facilitates learning from failed attempts by replaying trajectories with redefined goals. However, it relies on a heuristic-based replay method that lacks a principled framework. To address this limitation, we introduce a novel replay strategy, "Next-Future", which focuses on rewarding single-step transitions. This approach significantly enhances sample efficiency and accuracy in learning multi-goal Markov decision processes (MDPs), particularly under stringent accuracy requirements -- a critical aspect for performing complex and precise robotic-arm tasks. We demonstrate the efficacy of our method by highlighting how single-step learning enables improved value approximation within the multi-goal RL framework. The performance of the proposed replay strategy is evaluated across eight challenging robotic manipulation tasks, using ten random seeds for training. Our results indicate substantial improvements in sample efficiency for seven out of eight tasks and higher success rates in six tasks. Furthermore, real-world experiments validate the practical feasibility of the learned policies, demonstrating the potential of "Next-Future" in solving complex robotic-arm tasks.