 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Ambiguity: Aleatoric Uncertainty Quantification in LLMs for Safe Medical Question Answering
Jan 24, 2026The deployment of Large Language Models in Medical Question Answering is severely hampered by ambiguous user queries, a significant safety risk that demonstrably reduces answer accuracy in high-stakes healthcare settings. In this paper, we formalize this challenge by linking input ambiguity to aleatoric uncertainty (AU), which is the irreducible uncertainty arising from underspecified input. To facilitate research in this direction, we construct CV-MedBench, the first benchmark designed for studying input ambiguity in Medical QA. Using this benchmark, we analyze AU from a representation engineering perspective, revealing that AU is linearly encoded in LLM's internal activation patterns. Leveraging this insight, we introduce a novel AU-guided "Clarify-Before-Answer" framework, which incorporates AU-Probe - a lightweight module that detects input ambiguity directly from hidden states. Unlike existing uncertainty estimation methods, AU-Probe requires neither LLM fine-tuning nor multiple forward passes, enabling an efficient mechanism to proactively request user clarification and significantly enhance safety. Extensive experiments across four open LLMs demonstrate the effectiveness of our QA framework, with an average accuracy improvement of 9.48% over baselines. Our framework provides an efficient and robust solution for safe Medical QA, strengthening the reliability of health-related applications. The code is available at https://github.com/yaokunliu/AU-Med.git, and the CV-MedBench dataset is released on Hugging Face at https://huggingface.co/datasets/yaokunl/CV-MedBench.
FCMBench: A Comprehensive Financial Credit Multimodal Benchmark for Real-world Applications
Jan 06, 2026As multimodal AI becomes widely used for credit risk assessment and document review, a domain-specific benchmark is urgently needed that (1) reflects documents and workflows specific to financial credit applications, (2) includes credit-specific understanding and real-world robustness, and (3) preserves privacy compliance without sacrificing practical utility. Here, we introduce FCMBench-V1.0 -- a large-scale financial credit multimodal benchmark for real-world applications, covering 18 core certificate types, with 4,043 privacy-compliant images and 8,446 QA samples. The FCMBench evaluation framework consists of three dimensions: Perception, Reasoning, and Robustness, including 3 foundational perception tasks, 4 credit-specific reasoning tasks that require decision-oriented understanding of visual evidence, and 10 real-world acquisition artifact types for robustness stress testing. To reconcile compliance with realism, we construct all samples via a closed synthesis-capture pipeline: we manually synthesize document templates with virtual content and capture scenario-aware images in-house. This design also mitigates pre-training data leakage by avoiding web-sourced or publicly released images. FCMBench can effectively discriminate performance disparities and robustness across modern vision-language models. Extensive experiments were conducted on 23 state-of-the-art vision-language models (VLMs) from 14 top AI companies and research institutes. Among them, Gemini 3 Pro achieves the best F1(\%) score as a commercial model (64.61), Qwen3-VL-235B achieves the best score as an open-source baseline (57.27), and our financial credit-specific model, Qfin-VL-Instruct, achieves the top overall score (64.92). Robustness evaluations show that even top-performing models suffer noticeable performance drops under acquisition artifacts.
Abstract 3D Perception for Spatial Intelligence in Vision-Language Models
Nov 14, 2025Vision-language models (VLMs) struggle with 3D-related tasks such as spatial cognition and physical understanding, which are crucial for real-world applications like robotics and embodied agents. We attribute this to a modality gap between the 3D tasks and the 2D training of VLM, which led to inefficient retrieval of 3D information from 2D input. To bridge this gap, we introduce SandboxVLM, a simple yet effective framework that leverages abstract bounding boxes to encode geometric structure and physical kinematics for VLM. Specifically, we design a 3D Sandbox reconstruction and perception pipeline comprising four stages: generating multi-view priors with abstract control, proxy elevation, multi-view voting and clustering, and 3D-aware reasoning. Evaluated in zero-shot settings across multiple benchmarks and VLM backbones, our approach consistently improves spatial intelligence, achieving an 8.3\% gain on SAT Real compared with baseline methods for instance. These results demonstrate that equipping VLMs with a 3D abstraction substantially enhances their 3D reasoning ability without additional training, suggesting new possibilities for general-purpose embodied intelligence.
RoboTAG: End-to-end Robot Configuration Estimation via Topological Alignment Graph
Nov 11, 2025Estimating robot pose from a monocular RGB image is a challenge in robotics and computer vision. Existing methods typically build networks on top of 2D visual backbones and depend heavily on labeled data for training, which is often scarce in real-world scenarios, causing a sim-to-real gap. Moreover, these approaches reduce the 3D-based problem to 2D domain, neglecting the 3D priors. To address these, we propose Robot Topological Alignment Graph (RoboTAG), which incorporates a 3D branch to inject 3D priors while enabling co-evolution of the 2D and 3D representations, alleviating the reliance on labels. Specifically, the RoboTAG consists of a 3D branch and a 2D branch, where nodes represent the states of the camera and robot system, and edges capture the dependencies between these variables or denote alignments between them. Closed loops are then defined in the graph, on which a consistency supervision across branches can be applied. This design allows us to utilize in-the-wild images as training data without annotations. Experimental results demonstrate that our method is effective across robot types, highlighting its potential to alleviate the data bottleneck in robotics.
AssoCiAm: A Benchmark for Evaluating Association Thinking while Circumventing Ambiguity
Sep 18, 2025Recent advancements in multimodal large language models (MLLMs) have garnered significant attention, offering a promising pathway toward artificial general intelligence (AGI). Among the essential capabilities required for AGI, creativity has emerged as a critical trait for MLLMs, with association serving as its foundation. Association reflects a model' s ability to think creatively, making it vital to evaluate and understand. While several frameworks have been proposed to assess associative ability, they often overlook the inherent ambiguity in association tasks, which arises from the divergent nature of associations and undermines the reliability of evaluations. To address this issue, we decompose ambiguity into two types-internal ambiguity and external ambiguity-and introduce AssoCiAm, a benchmark designed to evaluate associative ability while circumventing the ambiguity through a hybrid computational method. We then conduct extensive experiments on MLLMs, revealing a strong positive correlation between cognition and association. Additionally, we observe that the presence of ambiguity in the evaluation process causes MLLMs' behavior to become more random-like. Finally, we validate the effectiveness of our method in ensuring more accurate and reliable evaluations. See Project Page for the data and codes.
Perceiving and Acting in First-Person: A Dataset and Benchmark for Egocentric Human-Object-Human Interactions
Aug 06, 2025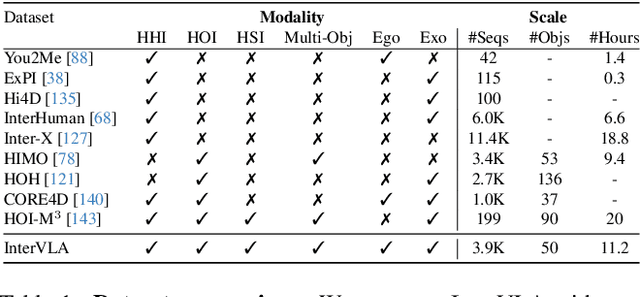

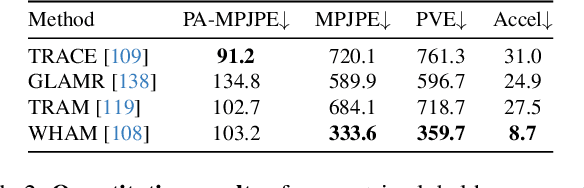

Learning action models from real-world human-centric interaction datasets is important towards building general-purpose intelligent assistants with efficiency. However, most existing datasets only offer specialist interaction category and ignore that AI assistants perceive and act based on first-person acquisition. We urge that both the generalist interaction knowledge and egocentric modality are indispensable. In this paper, we embed the manual-assisted task into a vision-language-action framework, where the assistant provides services to the instructor following egocentric vision and commands. With our hybrid RGB-MoCap system, pairs of assistants and instructors engage with multiple objects and the scene following GPT-generated scripts. Under this setting, we accomplish InterVLA, the first large-scale human-object-human interaction dataset with 11.4 hours and 1.2M frames of multimodal data, spanning 2 egocentric and 5 exocentric videos, accurate human/object motions and verbal commands. Furthermore, we establish novel benchmarks on egocentric human motion estimation, interaction synthesis, and interaction prediction with comprehensive analysis. We believe that our InterVLA testbed and the benchmarks will foster future works on building AI agents in the physical world.
Contrast-Prior Enhanced Duality for Mask-Free Shadow Removal
Jul 29, 2025



Existing shadow removal methods often rely on shadow masks, which are challenging to acquire in real-world scenarios. Exploring intrinsic image cues, such as local contrast information, presents a potential alternative for guiding shadow removal in the absence of explicit masks. However, the cue's inherent ambiguity becomes a critical limitation in complex scenes, where it can fail to distinguish true shadows from low-reflectance objects and intricate background textures. To address this motivation, we propose the Adaptive Gated Dual-Branch Attention (AGBA) mechanism. AGBA dynamically filters and re-weighs the contrast prior to effectively disentangle shadow features from confounding visual elements. Furthermore, to tackle the persistent challenge of restoring soft shadow boundaries and fine-grained details, we introduce a diffusion-based Frequency-Contrast Fusion Network (FCFN) that leverages high-frequency and contrast cues to guide the generative process. Extensive experiments demonstrate that our method achieves state-of-the-art results among mask-free approaches while maintaining competitive performance relative to mask-based methods.
Component Adaptive Clustering for Generalized Category Discovery
Jul 02, 2025



Generalized Category Discovery (GCD) tackles the challenging problem of categorizing unlabeled images into both known and novel classes within a partially labeled dataset, without prior knowledge of the number of unknown categories. Traditional methods often rely on rigid assumptions, such as predefining the number of classes, which limits their ability to handle the inherent variability and complexity of real-world data. To address these shortcomings, we propose AdaGCD, a cluster-centric contrastive learning framework that incorporates Adaptive Slot Attention (AdaSlot) into the GCD framework. AdaSlot dynamically determines the optimal number of slots based on data complexity, removing the need for predefined slot counts. This adaptive mechanism facilitates the flexible clustering of unlabeled data into known and novel categories by dynamically allocating representational capacity. By integrating adaptive representation with dynamic slot allocation, our method captures both instance-specific and spatially clustered features, improving class discovery in open-world scenarios. Extensive experiments on public and fine-grained datasets validate the effectiveness of our framework, emphasizing the advantages of leveraging spatial local information for category discovery in unlabeled image datasets.
An Explainable AI Framework for Dynamic Resource Management in Vehicular Network Slicing
Jun 13, 2025Effective resource management and network slicing are essential to meet the diverse service demands of vehicular networks, including Enhanced Mobile Broadband (eMBB) and Ultra-Reliable and Low-Latency Communications (URLLC). This paper introduces an Explainable Deep Reinforcement Learning (XRL) framework for dynamic network slicing and resource allocation in vehicular networks, built upon a near-real-time RAN intelligent controller. By integrating a feature-based approach that leverages Shapley values and an attention mechanism, we interpret and refine the decisions of our reinforcementlearning agents, addressing key reliability challenges in vehicular communication systems. Simulation results demonstrate that our approach provides clear, real-time insights into the resource allocation process and achieves higher interpretability precision than a pure attention mechanism. Furthermore, the Quality of Service (QoS) satisfaction for URLLC services increased from 78.0% to 80.13%, while that for eMBB services improved from 71.44% to 73.21%.
Serendipitous Recommendation with Multimodal LLM
Jun 09, 2025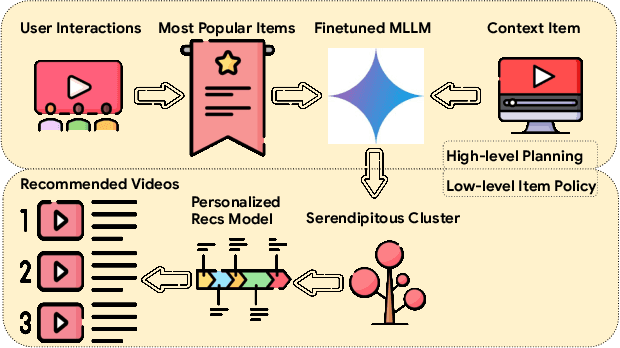
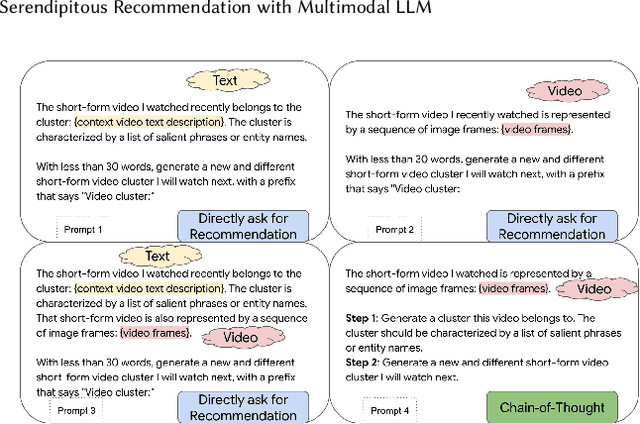
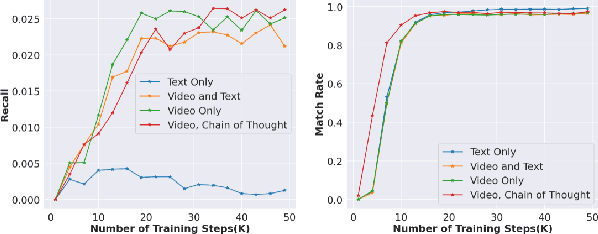
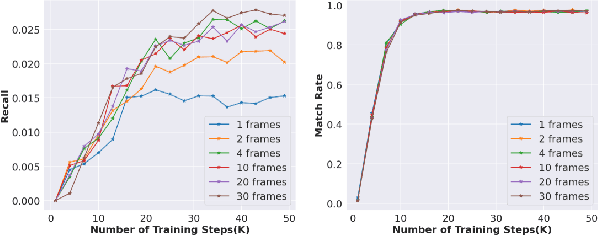
Conventional recommendation systems succeed in identifying relevant content but often fail to provide users with surprising or novel items. Multimodal Large Language Models (MLLMs) possess the world knowledge and multimodal understanding needed for serendipity, but their integration into billion-item-scale platforms presents significant challenges. In this paper, we propose a novel hierarchical framework where fine-tuned MLLMs provide high-level guidance to conventional recommendation models, steering them towards more serendipitous suggestions. This approach leverages MLLM strengths in understanding multimodal content and user interests while retaining the efficiency of traditional models for item-level recommendation. This mitigates the complexity of applying MLLMs directly to vast action spaces. We also demonstrate a chain-of-thought strategy enabling MLLMs to discover novel user interests by first understanding video content and then identifying relevant yet unexplored interest clusters. Through live experiments within a commercial short-form video platform serving billions of users, we show that our MLLM-powered approach significantly improves both recommendation serendipity and user satisfaction.