 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?
Mar 26, 2026Beneath the stunning visual fidelity of modern AIGC models lies a "logical desert", where systems fail tasks that require physical, causal, or complex spatial reasoning. Current evaluations largely rely on superficial metrics or fragmented benchmarks, creating a ``performance mirage'' that overlooks the generative process. To address this, we introduce ViGoR Vision-G}nerative Reasoning-centric Benchmark), a unified framework designed to dismantle this mirage. ViGoR distinguishes itself through four key innovations: 1) holistic cross-modal coverage bridging Image-to-Image and Video tasks; 2) a dual-track mechanism evaluating both intermediate processes and final results; 3) an evidence-grounded automated judge ensuring high human alignment; and 4) granular diagnostic analysis that decomposes performance into fine-grained cognitive dimensions. Experiments on over 20 leading models reveal that even state-of-the-art systems harbor significant reasoning deficits, establishing ViGoR as a critical ``stress test'' for the next generation of intelligent vision models. The demo have been available at https://vincenthancoder.github.io/ViGoR-Bench/
MagicFight: Personalized Martial Arts Combat Video Generation
Jan 05, 2026Amid the surge in generic text-to-video generation, the field of personalized human video generation has witnessed notable advancements, primarily concentrated on single-person scenarios. However, to our knowledge, the domain of two-person interactions, particularly in the context of martial arts combat, remains uncharted. We identify a significant gap: existing models for single-person dancing generation prove insufficient for capturing the subtleties and complexities of two engaged fighters, resulting in challenges such as identity confusion, anomalous limbs, and action mismatches. To address this, we introduce a pioneering new task, Personalized Martial Arts Combat Video Generation. Our approach, MagicFight, is specifically crafted to overcome these hurdles. Given this pioneering task, we face a lack of appropriate datasets. Thus, we generate a bespoke dataset using the game physics engine Unity, meticulously crafting a multitude of 3D characters, martial arts moves, and scenes designed to represent the diversity of combat. MagicFight refines and adapts existing models and strategies to generate high-fidelity two-person combat videos that maintain individual identities and ensure seamless, coherent action sequences, thereby laying the groundwork for future innovations in the realm of interactive video content creation. Website: https://MingfuYAN.github.io/MagicFight/ Dataset: https://huggingface.co/datasets/MingfuYAN/KungFu-Fiesta
STAR: STacked AutoRegressive Scheme for Unified Multimodal Learning
Dec 15, 2025
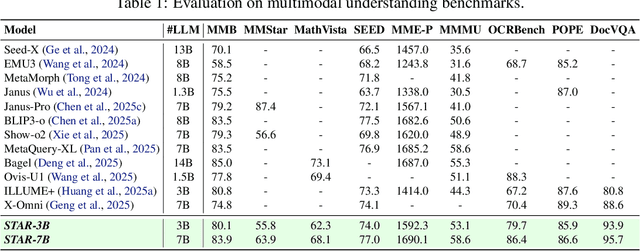
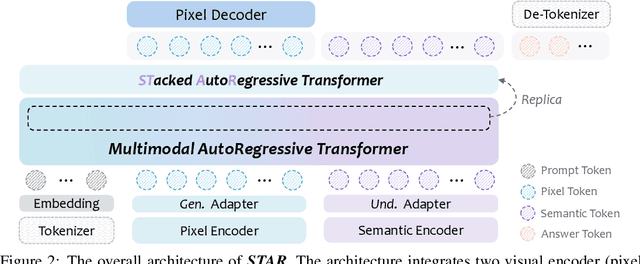
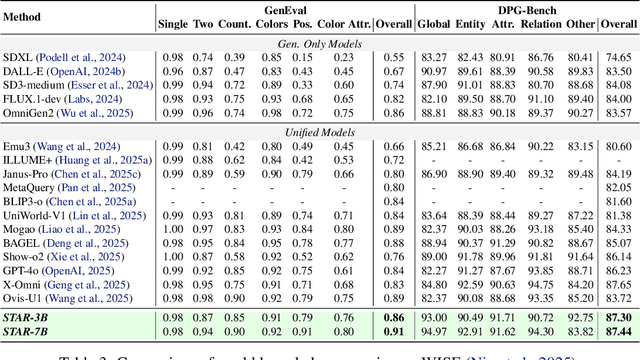
Multimodal large language models (MLLMs) play a pivotal role in advancing the quest for general artificial intelligence. However, achieving unified target for multimodal understanding and generation remains challenging due to optimization conflicts and performance trade-offs. To effectively enhance generative performance while preserving existing comprehension capabilities, we introduce STAR: a STacked AutoRegressive scheme for task-progressive unified multimodal learning. This approach decomposes multimodal learning into multiple stages: understanding, generation, and editing. By freezing the parameters of the fundamental autoregressive (AR) model and progressively stacking isomorphic AR modules, it avoids cross-task interference while expanding the model's capabilities. Concurrently, we introduce a high-capacity VQ to enhance the granularity of image representations and employ an implicit reasoning mechanism to improve generation quality under complex conditions. Experiments demonstrate that STAR achieves state-of-the-art performance on GenEval (0.91), DPG-Bench (87.44), and ImgEdit (4.34), validating its efficacy for unified multimodal learning.
Contrast-Prior Enhanced Duality for Mask-Free Shadow Removal
Jul 29, 2025



Existing shadow removal methods often rely on shadow masks, which are challenging to acquire in real-world scenarios. Exploring intrinsic image cues, such as local contrast information, presents a potential alternative for guiding shadow removal in the absence of explicit masks. However, the cue's inherent ambiguity becomes a critical limitation in complex scenes, where it can fail to distinguish true shadows from low-reflectance objects and intricate background textures. To address this motivation, we propose the Adaptive Gated Dual-Branch Attention (AGBA) mechanism. AGBA dynamically filters and re-weighs the contrast prior to effectively disentangle shadow features from confounding visual elements. Furthermore, to tackle the persistent challenge of restoring soft shadow boundaries and fine-grained details, we introduce a diffusion-based Frequency-Contrast Fusion Network (FCFN) that leverages high-frequency and contrast cues to guide the generative process. Extensive experiments demonstrate that our method achieves state-of-the-art results among mask-free approaches while maintaining competitive performance relative to mask-based methods.
Component Adaptive Clustering for Generalized Category Discovery
Jul 02, 2025



Generalized Category Discovery (GCD) tackles the challenging problem of categorizing unlabeled images into both known and novel classes within a partially labeled dataset, without prior knowledge of the number of unknown categories. Traditional methods often rely on rigid assumptions, such as predefining the number of classes, which limits their ability to handle the inherent variability and complexity of real-world data. To address these shortcomings, we propose AdaGCD, a cluster-centric contrastive learning framework that incorporates Adaptive Slot Attention (AdaSlot) into the GCD framework. AdaSlot dynamically determines the optimal number of slots based on data complexity, removing the need for predefined slot counts. This adaptive mechanism facilitates the flexible clustering of unlabeled data into known and novel categories by dynamically allocating representational capacity. By integrating adaptive representation with dynamic slot allocation, our method captures both instance-specific and spatially clustered features, improving class discovery in open-world scenarios. Extensive experiments on public and fine-grained datasets validate the effectiveness of our framework, emphasizing the advantages of leveraging spatial local information for category discovery in unlabeled image datasets.
M4V: Multi-Modal Mamba for Text-to-Video Generation
Jun 12, 2025Text-to-video generation has significantly enriched content creation and holds the potential to evolve into powerful world simulators. However, modeling the vast spatiotemporal space remains computationally demanding, particularly when employing Transformers, which incur quadratic complexity in sequence processing and thus limit practical applications. Recent advancements in linear-time sequence modeling, particularly the Mamba architecture, offer a more efficient alternative. Nevertheless, its plain design limits its direct applicability to multi-modal and spatiotemporal video generation tasks. To address these challenges, we introduce M4V, a Multi-Modal Mamba framework for text-to-video generation. Specifically, we propose a multi-modal diffusion Mamba (MM-DiM) block that enables seamless integration of multi-modal information and spatiotemporal modeling through a multi-modal token re-composition design. As a result, the Mamba blocks in M4V reduce FLOPs by 45% compared to the attention-based alternative when generating videos at 768$\times$1280 resolution. Additionally, to mitigate the visual quality degradation in long-context autoregressive generation processes, we introduce a reward learning strategy that further enhances per-frame visual realism. Extensive experiments on text-to-video benchmarks demonstrate M4V's ability to produce high-quality videos while significantly lowering computational costs. Code and models will be publicly available at https://huangjch526.github.io/M4V_project.
The Tenth NTIRE 2025 Efficient Super-Resolution Challenge Report
Apr 14, 2025This paper presents a comprehensive review of the NTIRE 2025 Challenge on Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance the development of deep models that optimize key computational metrics, i.e., runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on the $\operatorname{DIV2K\_LSDIR\_valid}$ dataset and 26.99 dB on the $\operatorname{DIV2K\_LSDIR\_test}$ dataset. A robust participation saw \textbf{244} registered entrants, with \textbf{43} teams submitting valid entries. This report meticulously analyzes these methods and results, emphasizing groundbreaking advancements in state-of-the-art single-image ESR techniques. The analysis highlights innovative approaches and establishes benchmarks for future research in the field.
Leveraging Contrast Information for Efficient Document Shadow Removal
Apr 01, 2025Document shadows are a major obstacle in the digitization process. Due to the dense information in text and patterns covered by shadows, document shadow removal requires specialized methods. Existing document shadow removal methods, although showing some progress, still rely on additional information such as shadow masks or lack generalization and effectiveness across different shadow scenarios. This often results in incomplete shadow removal or loss of original document content and tones. Moreover, these methods tend to underutilize the information present in the original shadowed document image. In this paper, we refocus our approach on the document images themselves, which inherently contain rich information.We propose an end-to-end document shadow removal method guided by contrast representation, following a coarse-to-fine refinement approach. By extracting document contrast information, we can effectively and quickly locate shadow shapes and positions without the need for additional masks. This information is then integrated into the refined shadow removal process, providing better guidance for network-based removal and feature fusion. Extensive qualitative and quantitative experiments show that our method achieves state-of-the-art performance.
FlexVAR: Flexible Visual Autoregressive Modeling without Residual Prediction
Feb 27, 2025This work challenges the residual prediction paradigm in visual autoregressive modeling and presents FlexVAR, a new Flexible Visual AutoRegressive image generation paradigm. FlexVAR facilitates autoregressive learning with ground-truth prediction, enabling each step to independently produce plausible images. This simple, intuitive approach swiftly learns visual distributions and makes the generation process more flexible and adaptable. Trained solely on low-resolution images ($\leq$ 256px), FlexVAR can: (1) Generate images of various resolutions and aspect ratios, even exceeding the resolution of the training images. (2) Support various image-to-image tasks, including image refinement, in/out-painting, and image expansion. (3) Adapt to various autoregressive steps, allowing for faster inference with fewer steps or enhancing image quality with more steps. Our 1.0B model outperforms its VAR counterpart on the ImageNet 256$\times$256 benchmark. Moreover, when zero-shot transfer the image generation process with 13 steps, the performance further improves to 2.08 FID, outperforming state-of-the-art autoregressive models AiM/VAR by 0.25/0.28 FID and popular diffusion models LDM/DiT by 1.52/0.19 FID, respectively. When transferring our 1.0B model to the ImageNet 512$\times$512 benchmark in a zero-shot manner, FlexVAR achieves competitive results compared to the VAR 2.3B model, which is a fully supervised model trained at 512$\times$512 resolution.
Dual-Schedule Inversion: Training- and Tuning-Free Inversion for Real Image Editing
Dec 15, 2024



Text-conditional image editing is a practical AIGC task that has recently emerged with great commercial and academic value. For real image editing, most diffusion model-based methods use DDIM Inversion as the first stage before editing. However, DDIM Inversion often results in reconstruction failure, leading to unsatisfactory performance for downstream editing. To address this problem, we first analyze why the reconstruction via DDIM Inversion fails. We then propose a new inversion and sampling method named Dual-Schedule Inversion. We also design a classifier to adaptively combine Dual-Schedule Inversion with different editing methods for user-friendly image editing. Our work can achieve superior reconstruction and editing performance with the following advantages: 1) It can reconstruct real images perfectly without fine-tuning, and its reversibility is guaranteed mathematically. 2) The edited object/scene conforms to the semantics of the text prompt. 3) The unedited parts of the object/scene retain the original identity.