 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDreamWorld: Unified World Modeling in Video Generation
Feb 28, 2026Despite impressive progress in video generation, existing models remain limited to surface-level plausibility, lacking a coherent and unified understanding of the world. Prior approaches typically incorporate only a single form of world-related knowledge or rely on rigid alignment strategies to introduce additional knowledge. However, aligning the single world knowledge is insufficient to constitute a world model that requires jointly modeling multiple heterogeneous dimensions (e.g., physical commonsense, 3D and temporal consistency). To address this limitation, we introduce \textbf{DreamWorld}, a unified framework that integrates complementary world knowledge into video generators via a \textbf{Joint World Modeling Paradigm}, jointly predicting video pixels and features from foundation models to capture temporal dynamics, spatial geometry, and semantic consistency. However, naively optimizing these heterogeneous objectives can lead to visual instability and temporal flickering. To mitigate this issue, we propose \textit{Consistent Constraint Annealing (CCA)} to progressively regulate world-level constraints during training, and \textit{Multi-Source Inner-Guidance} to enforce learned world priors at inference. Extensive evaluations show that DreamWorld improves world consistency, outperforming Wan2.1 by 2.26 points on VBench. Code will be made publicly available at \href{https://github.com/ABU121111/DreamWorld}{\textcolor{mypink}{\textbf{Github}}}.
Dual-Branch Center-Surrounding Contrast: Rethinking Contrastive Learning for 3D Point Clouds
Dec 09, 2025



Most existing self-supervised learning (SSL) approaches for 3D point clouds are dominated by generative methods based on Masked Autoencoders (MAE). However, these generative methods have been proven to struggle to capture high-level discriminative features effectively, leading to poor performance on linear probing and other downstream tasks. In contrast, contrastive methods excel in discriminative feature representation and generalization ability on image data. Despite this, contrastive learning (CL) in 3D data remains scarce. Besides, simply applying CL methods designed for 2D data to 3D fails to effectively learn 3D local details. To address these challenges, we propose a novel Dual-Branch \textbf{C}enter-\textbf{S}urrounding \textbf{Con}trast (CSCon) framework. Specifically, we apply masking to the center and surrounding parts separately, constructing dual-branch inputs with center-biased and surrounding-biased representations to better capture rich geometric information. Meanwhile, we introduce a patch-level contrastive loss to further enhance both high-level information and local sensitivity. Under the FULL and ALL protocols, CSCon achieves performance comparable to generative methods; under the MLP-LINEAR, MLP-3, and ONLY-NEW protocols, our method attains state-of-the-art results, even surpassing cross-modal approaches. In particular, under the MLP-LINEAR protocol, our method outperforms the baseline (Point-MAE) by \textbf{7.9\%}, \textbf{6.7\%}, and \textbf{10.3\%} on the three variants of ScanObjectNN, respectively. The code will be made publicly available.
VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
Decentralized Arena: Towards Democratic and Scalable Automatic Evaluation of Language Models
May 19, 2025



The recent explosion of large language models (LLMs), each with its own general or specialized strengths, makes scalable, reliable benchmarking more urgent than ever. Standard practices nowadays face fundamental trade-offs: closed-ended question-based benchmarks (eg MMLU) struggle with saturation as newer models emerge, while crowd-sourced leaderboards (eg Chatbot Arena) rely on costly and slow human judges. Recently, automated methods (eg LLM-as-a-judge) shed light on the scalability, but risk bias by relying on one or a few "authority" models. To tackle these issues, we propose Decentralized Arena (dearena), a fully automated framework leveraging collective intelligence from all LLMs to evaluate each other. It mitigates single-model judge bias by democratic, pairwise evaluation, and remains efficient at scale through two key components: (1) a coarse-to-fine ranking algorithm for fast incremental insertion of new models with sub-quadratic complexity, and (2) an automatic question selection strategy for the construction of new evaluation dimensions. Across extensive experiments across 66 LLMs, dearena attains up to 97% correlation with human judgements, while significantly reducing the cost. Our code and data will be publicly released on https://github.com/maitrix-org/de-arena.
PCP-MAE: Learning to Predict Centers for Point Masked Autoencoders
Aug 16, 2024Masked autoencoder has been widely explored in point cloud self-supervised learning, whereby the point cloud is generally divided into visible and masked parts. These methods typically include an encoder accepting visible patches (normalized) and corresponding patch centers (position) as input, with the decoder accepting the output of the encoder and the centers (position) of the masked parts to reconstruct each point in the masked patches. Then, the pre-trained encoders are used for downstream tasks. In this paper, we show a motivating empirical result that when directly feeding the centers of masked patches to the decoder without information from the encoder, it still reconstructs well. In other words, the centers of patches are important and the reconstruction objective does not necessarily rely on representations of the encoder, thus preventing the encoder from learning semantic representations. Based on this key observation, we propose a simple yet effective method, i.e., learning to Predict Centers for Point Masked AutoEncoders (PCP-MAE) which guides the model to learn to predict the significant centers and use the predicted centers to replace the directly provided centers. Specifically, we propose a Predicting Center Module (PCM) that shares parameters with the original encoder with extra cross-attention to predict centers. Our method is of high pre-training efficiency compared to other alternatives and achieves great improvement over Point-MAE, particularly outperforming it by 5.50%, 6.03%, and 5.17% on three variants of ScanObjectNN. The code will be made publicly available.
Pi-fusion: Physics-informed diffusion model for learning fluid dynamics
Jun 06, 2024Physics-informed deep learning has been developed as a novel paradigm for learning physical dynamics recently. While general physics-informed deep learning methods have shown early promise in learning fluid dynamics, they are difficult to generalize in arbitrary time instants in real-world scenario, where the fluid motion can be considered as a time-variant trajectory involved large-scale particles. Inspired by the advantage of diffusion model in learning the distribution of data, we first propose Pi-fusion, a physics-informed diffusion model for predicting the temporal evolution of velocity and pressure field in fluid dynamics. Physics-informed guidance sampling is proposed in the inference procedure of Pi-fusion to improve the accuracy and interpretability of learning fluid dynamics. Furthermore, we introduce a training strategy based on reciprocal learning to learn the quasiperiodical pattern of fluid motion and thus improve the generalizability of the model. The proposed approach are then evaluated on both synthetic and real-world dataset, by comparing it with state-of-the-art physics-informed deep learning methods. Experimental results show that the proposed approach significantly outperforms existing methods for predicting temporal evolution of velocity and pressure field, confirming its strong generalization by drawing probabilistic inference of forward process and physics-informed guidance sampling. The proposed Pi-fusion can also be generalized in learning other physical dynamics governed by partial differential equations.
Unified Batch Normalization: Identifying and Alleviating the Feature Condensation in Batch Normalization and a Unified Framework
Nov 27, 2023



Batch Normalization (BN) has become an essential technique in contemporary neural network design, enhancing training stability. Specifically, BN employs centering and scaling operations to standardize features along the batch dimension and uses an affine transformation to recover features. Although standard BN has shown its capability to improve deep neural network training and convergence, it still exhibits inherent limitations in certain cases. Most existing techniques that enhance BN consider a single or a few aspects of BN. In this paper, we first identify problems with BN from a feature perspective and explore that feature condensation exists in the learning when employing BN, which negatively affects testing performance. To tackle this problem, we propose a two-stage unified framework called Unified Batch Normalization (UBN). In the first stage, we utilize a simple feature condensation threshold to alleviate the feature condensation, which hinders inappropriate statistic updates in normalization. In the second stage, we unify various normalization variants to boost each component of BN. Our experimental results reveal that UBN significantly enhances performance across different visual backbones and notably expedites network training convergence, particularly in early training stages. Notably, our method improved about 3% in top-1 accuracy on ImageNet classification with large batch sizes, showing the effectiveness of our approach in real-world scenarios.
Hyperspectral Images Classification Based on Multi-scale Residual Network
May 12, 2020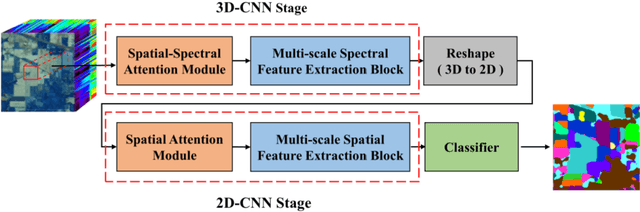
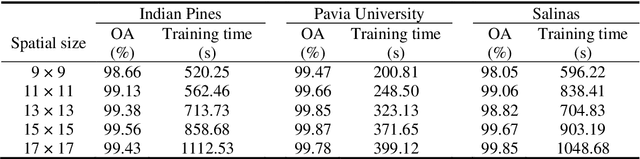
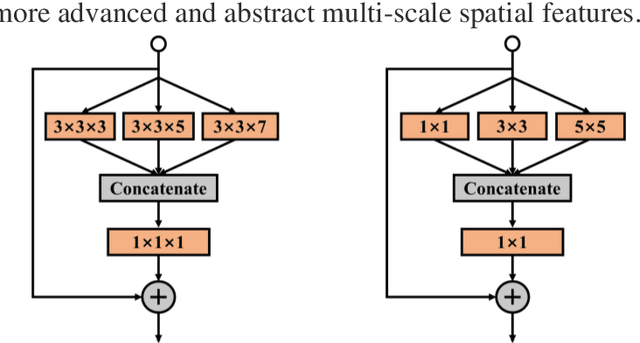
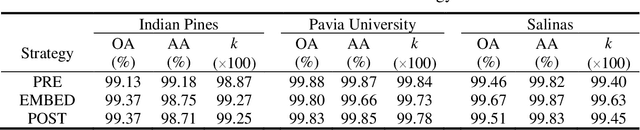
Because hyperspectral remote sensing images contain a lot of redundant information and the data structure is highly non-linear, leading to low classification accuracy of traditional machine learning methods. The latest research shows that hyperspectral image classification based on deep convolutional neural network has high accuracy. However, when a small amount of data is used for training, the classification accuracy of deep learning methods is greatly reduced. In order to solve the problem of low classification accuracy of existing algorithms on small samples of hyperspectral images, a multi-scale residual network is proposed. The multi-scale extraction and fusion of spatial and spectral features is realized by adding a branch structure into the residual block and using convolution kernels of different sizes in the branch. The spatial and spectral information contained in hyperspectral images are fully utilized to improve the classification accuracy. In addition, in order to improve the speed and prevent overfitting, the model uses dynamic learning rate, BN and Dropout strategies. The experimental results show that the overall classification accuracy of this method is 99.07% and 99.96% respectively in the data set of Indian Pines and Pavia University, which is better than other algorithms.