 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
MathOdyssey: Benchmarking Mathematical Problem-Solving Skills in Large Language Models Using Odyssey Math Data
Jun 26, 2024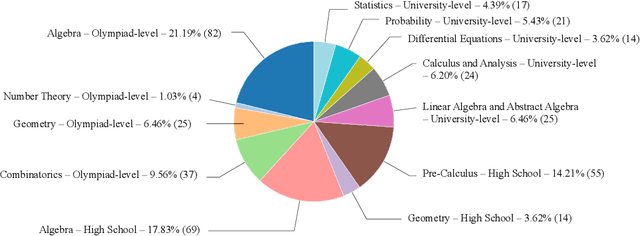
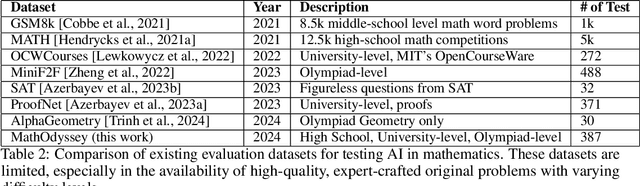

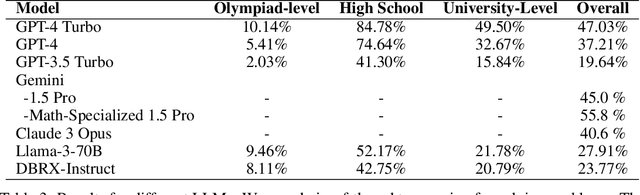
Large language models (LLMs) have significantly advanced natural language understanding and demonstrated strong problem-solving abilities. Despite these successes, most LLMs still struggle with solving mathematical problems due to the intricate reasoning required. This paper investigates the mathematical problem-solving capabilities of LLMs using the newly developed "MathOdyssey" dataset. The dataset includes diverse mathematical problems at high school and university levels, created by experts from notable institutions to rigorously test LLMs in advanced problem-solving scenarios and cover a wider range of subject areas. By providing the MathOdyssey dataset as a resource to the AI community, we aim to contribute to the understanding and improvement of AI capabilities in complex mathematical problem-solving. We conduct benchmarking on open-source models, such as Llama-3 and DBRX-Instruct, and closed-source models from the GPT series and Gemini models. Our results indicate that while LLMs perform well on routine and moderately difficult tasks, they face significant challenges with Olympiad-level problems and complex university-level questions. Our analysis shows a narrowing performance gap between open-source and closed-source models, yet substantial challenges remain, particularly with the most demanding problems. This study highlights the ongoing need for research to enhance the mathematical reasoning of LLMs. The dataset, results, and code are publicly available.
Enhancing the Efficiency and Accuracy of Underlying Asset Reviews in Structured Finance: The Application of Multi-agent Framework
May 07, 2024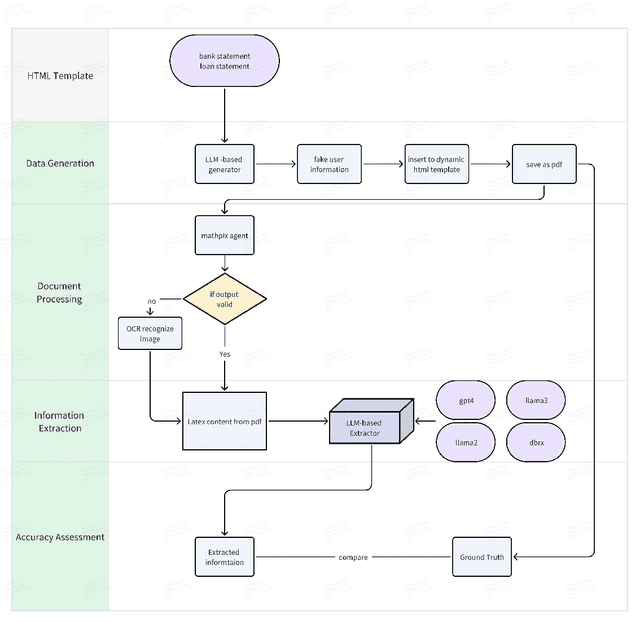
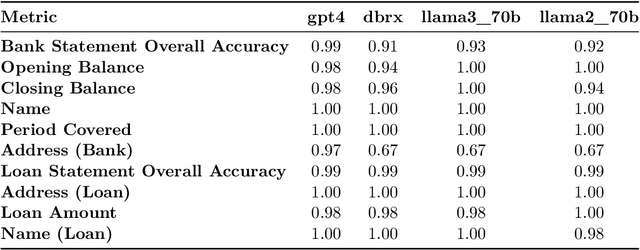
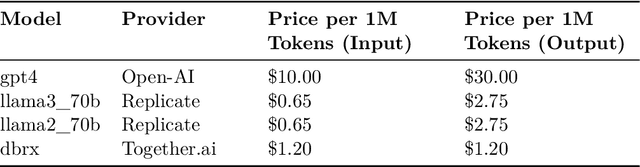
Structured finance, which involves restructuring diverse assets into securities like MBS, ABS, and CDOs, enhances capital market efficiency but presents significant due diligence challenges. This study explores the integration of artificial intelligence (AI) with traditional asset review processes to improve efficiency and accuracy in structured finance. Using both open-sourced and close-sourced large language models (LLMs), we demonstrate that AI can automate the verification of information between loan applications and bank statements effectively. While close-sourced models such as GPT-4 show superior performance, open-sourced models like LLAMA3 offer a cost-effective alternative. Dual-agent systems further increase accuracy, though this comes with higher operational costs. This research highlights AI's potential to minimize manual errors and streamline due diligence, suggesting a broader application of AI in financial document analysis and risk management.
Inherent limitations of LLMs regarding spatial information
Dec 05, 2023



Despite the significant advancements in natural language processing capabilities demonstrated by large language models such as ChatGPT, their proficiency in comprehending and processing spatial information, especially within the domains of 2D and 3D route planning, remains notably underdeveloped. This paper investigates the inherent limitations of ChatGPT and similar models in spatial reasoning and navigation-related tasks, an area critical for applications ranging from autonomous vehicle guidance to assistive technologies for the visually impaired. In this paper, we introduce a novel evaluation framework complemented by a baseline dataset, meticulously crafted for this study. This dataset is structured around three key tasks: plotting spatial points, planning routes in two-dimensional (2D) spaces, and devising pathways in three-dimensional (3D) environments. We specifically developed this dataset to assess the spatial reasoning abilities of ChatGPT. Our evaluation reveals key insights into the model's capabilities and limitations in spatial understanding.
Local Byte Fusion for Neural Machine Translation
May 23, 2022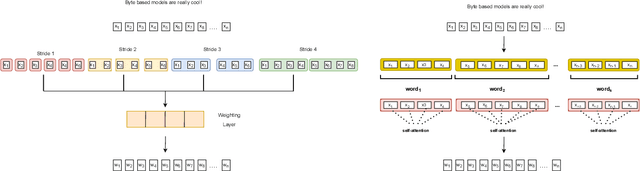
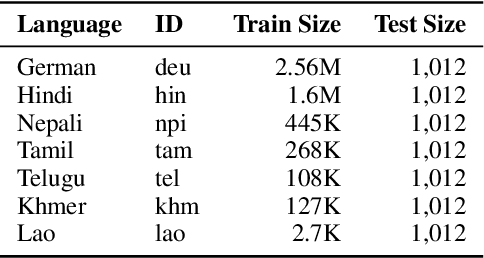
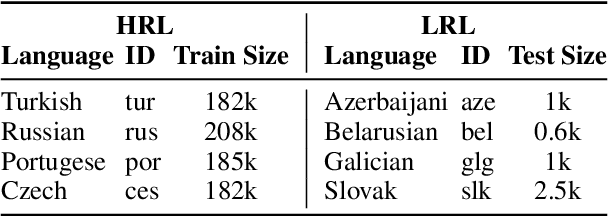
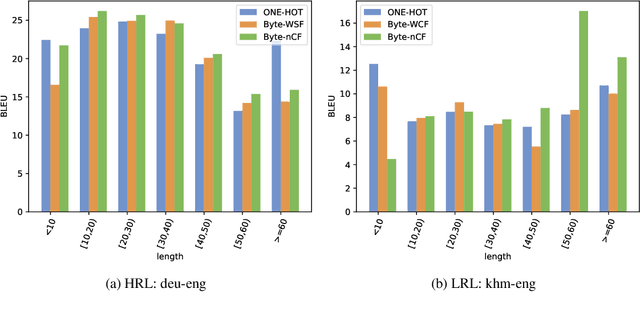
Subword tokenization schemes are the dominant technique used in current NLP models. However, such schemes can be rigid and tokenizers built on one corpus do not adapt well to other parallel corpora. It has also been observed that in multilingual corpora, subword tokenization schemes over-segment low-resource languages leading to a drop in translation performance. A simple alternative to subword tokenizers is byte-based methods i.e. tokenization into byte sequences using encoding schemes such as UTF-8. Byte tokens often represent inputs at a sub-character granularity i.e. one character can be represented by a sequence of multiple byte tokens. This results in byte sequences that are significantly longer than character sequences. Enforcing aggregation of local information in the lower layers can guide the model to build higher-level semantic information. We propose a Local Byte Fusion (LOBEF) method for byte-based machine translation -- utilizing byte $n$-gram and word boundaries -- to aggregate local semantic information. Extensive experiments on multilingual translation, zero-shot cross-lingual transfer, and domain adaptation reveal a consistent improvement over traditional byte-based models and even over subword techniques. Further analysis also indicates that our byte-based models are parameter-efficient and can be trained faster than subword models.
RASAT: Integrating Relational Structures into Pretrained Seq2Seq Model for Text-to-SQL
May 14, 2022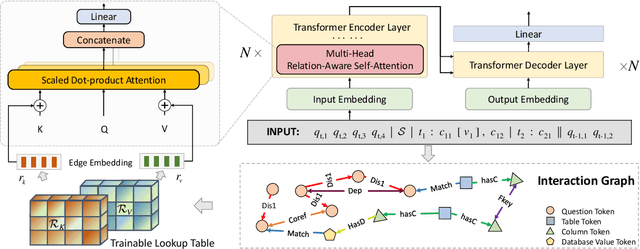
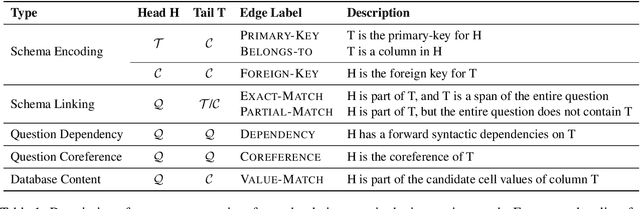
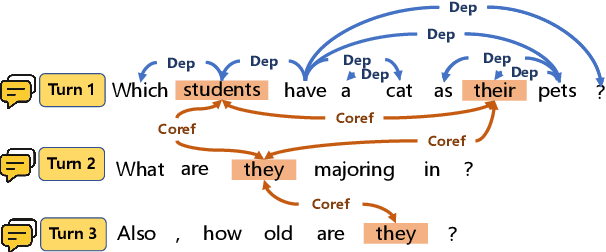
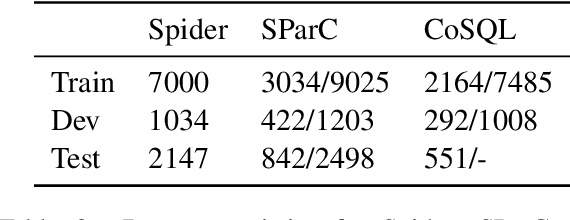
Relational structures such as schema linking and schema encoding have been validated as a key component to qualitatively translating natural language into SQL queries. However, introducing these structural relations comes with prices: they often result in a specialized model structure, which largely prohibits the use of large pretrained models in text-to-SQL. To address this problem, we propose RASAT: a Transformer seq2seq architecture augmented with relation-aware self-attention that could leverage a variety of relational structures while at the meantime being able to effectively inherit the pretrained parameters from the T5 model. Our model is able to incorporate almost all types of existing relations in the literature, and in addition, we propose to introduce co-reference relations for the multi-turn scenario. Experimental results on three widely used text-to-SQL datasets, covering both single-turn and multi-turn scenarios, have shown that RASAT could achieve competitive results in all three benchmarks, achieving state-of-the-art performance in execution accuracy (80.5\% EX on Spider, 53.1\% IEX on SParC, and 37.5\% IEX on CoSQL).
Word Embedding-based Text Processing for Comprehensive Summarization and Distinct Information Extraction
Apr 21, 2020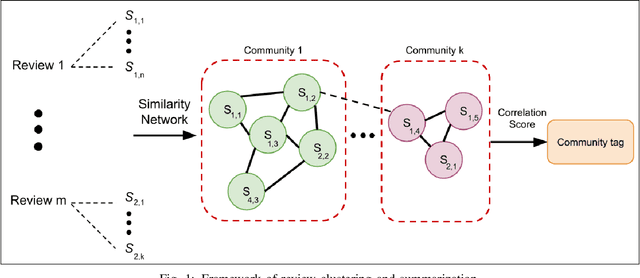
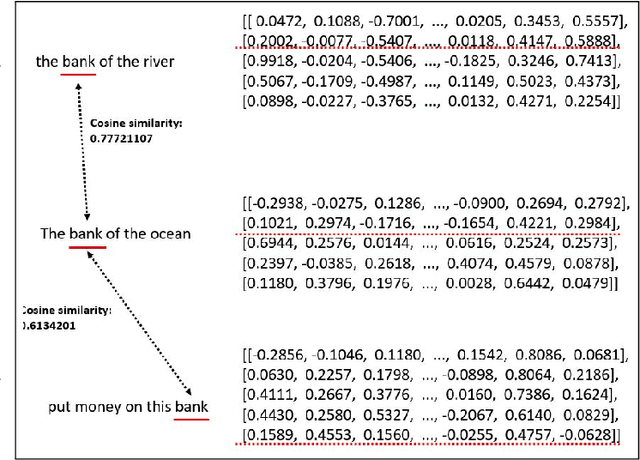

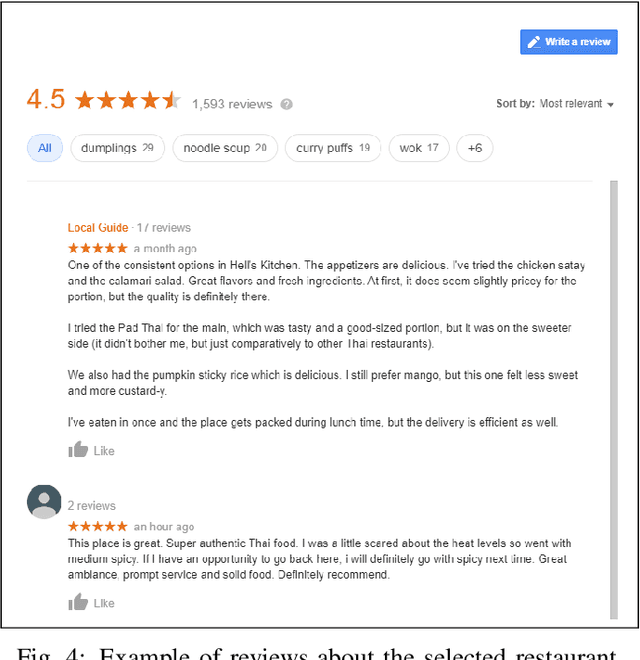
In this paper, we propose two automated text processing frameworks specifically designed to analyze online reviews. The objective of the first framework is to summarize the reviews dataset by extracting essential sentence. This is performed by converting sentences into numerical vectors and clustering them using a community detection algorithm based on their similarity levels. Afterwards, a correlation score is measured for each sentence to determine its importance level in each cluster and assign it as a tag for that community. The second framework is based on a question-answering neural network model trained to extract answers to multiple different questions. The collected answers are effectively clustered to find multiple distinct answers to a single question that might be asked by a customer. The proposed frameworks are shown to be more comprehensive than existing reviews processing solutions.
Leveraging Personal Navigation Assistant Systems Using Automated Social Media Traffic Reporting
Apr 21, 2020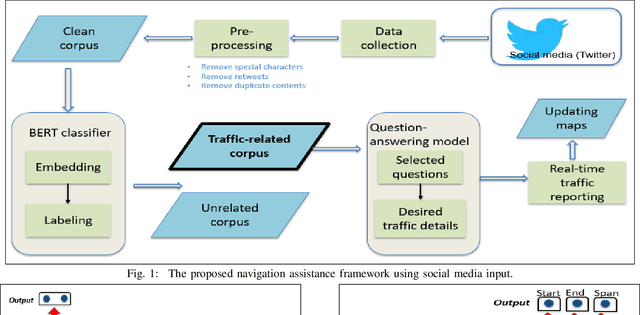
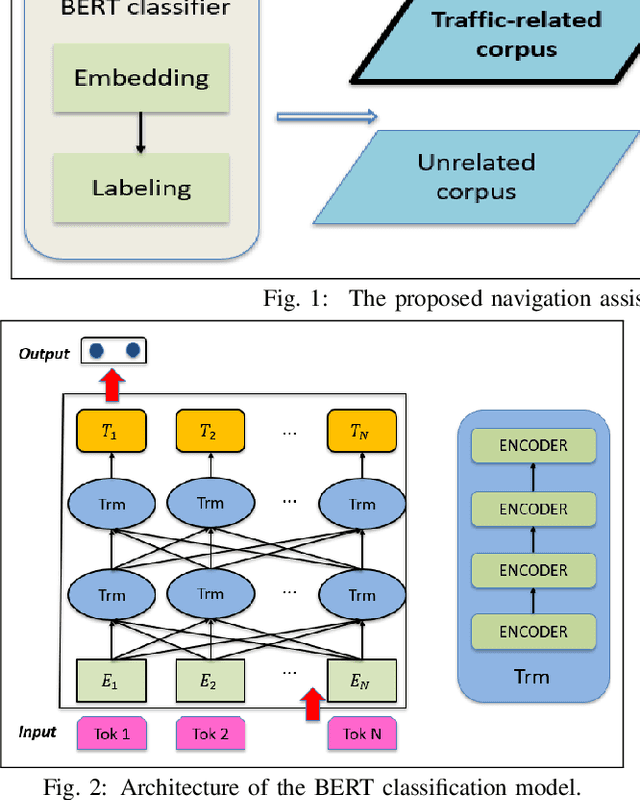
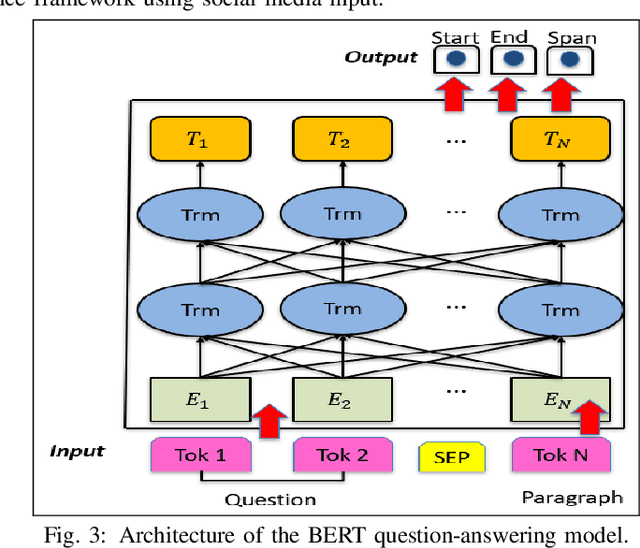

Modern urbanization is demanding smarter technologies to improve a variety of applications in intelligent transportation systems to relieve the increasing amount of vehicular traffic congestion and incidents. Existing incident detection techniques are limited to the use of sensors in the transportation network and hang on human-inputs. Despite of its data abundance, social media is not well-exploited in such context. In this paper, we develop an automated traffic alert system based on Natural Language Processing (NLP) that filters this flood of information and extract important traffic-related bullets. To this end, we employ the fine-tuning Bidirectional Encoder Representations from Transformers (BERT) language embedding model to filter the related traffic information from social media. Then, we apply a question-answering model to extract necessary information characterizing the report event such as its exact location, occurrence time, and nature of the events. We demonstrate the adopted NLP approaches outperform other existing approach and, after effectively training them, we focus on real-world situation and show how the developed approach can, in real-time, extract traffic-related information and automatically convert them into alerts for navigation assistance applications such as navigation apps.