 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
Apr 18, 2025Soft robots exhibit inherent compliance and safety, which makes them particularly suitable for applications requiring direct physical interaction with humans, such as surgical procedures. However, their nonlinear and hysteretic behavior, resulting from the properties of soft materials, presents substantial challenges for accurate modeling and control. In this study, we present a soft robotic system designed for surgical applications and propose a hysteresis-aware whole-body neural network model that accurately captures and predicts the soft robot's whole-body motion, including its hysteretic behavior. Building upon the high-precision dynamic model, we construct a highly parallel simulation environment for soft robot control and apply an on-policy reinforcement learning algorithm to efficiently train whole-body motion control strategies. Based on the trained control policy, we developed a soft robotic system for surgical applications and validated it through phantom-based laser ablation experiments in a physical environment. The results demonstrate that the hysteresis-aware modeling reduces the Mean Squared Error (MSE) by 84.95 percent compared to traditional modeling methods. The deployed control algorithm achieved a trajectory tracking error ranging from 0.126 to 0.250 mm on the real soft robot, highlighting its precision in real-world conditions. The proposed method showed strong performance in phantom-based surgical experiments and demonstrates its potential for complex scenarios, including future real-world clinical applications.
MathOdyssey: Benchmarking Mathematical Problem-Solving Skills in Large Language Models Using Odyssey Math Data
Jun 26, 2024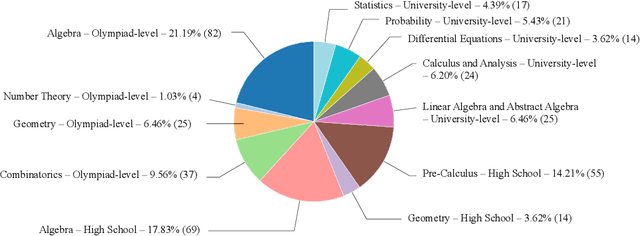
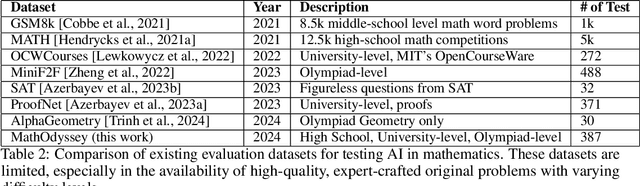

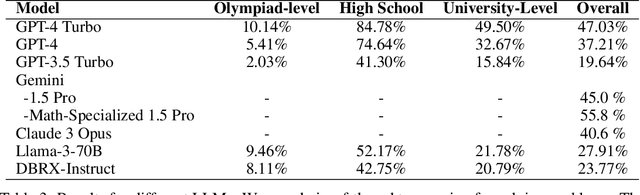
Large language models (LLMs) have significantly advanced natural language understanding and demonstrated strong problem-solving abilities. Despite these successes, most LLMs still struggle with solving mathematical problems due to the intricate reasoning required. This paper investigates the mathematical problem-solving capabilities of LLMs using the newly developed "MathOdyssey" dataset. The dataset includes diverse mathematical problems at high school and university levels, created by experts from notable institutions to rigorously test LLMs in advanced problem-solving scenarios and cover a wider range of subject areas. By providing the MathOdyssey dataset as a resource to the AI community, we aim to contribute to the understanding and improvement of AI capabilities in complex mathematical problem-solving. We conduct benchmarking on open-source models, such as Llama-3 and DBRX-Instruct, and closed-source models from the GPT series and Gemini models. Our results indicate that while LLMs perform well on routine and moderately difficult tasks, they face significant challenges with Olympiad-level problems and complex university-level questions. Our analysis shows a narrowing performance gap between open-source and closed-source models, yet substantial challenges remain, particularly with the most demanding problems. This study highlights the ongoing need for research to enhance the mathematical reasoning of LLMs. The dataset, results, and code are publicly available.