 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArthroCut: Autonomous Policy Learning for Robotic Bone Resection in Knee Arthroplasty
Mar 04, 2026Despite rapid commercialization of surgical robots, their autonomy and real-time decision-making remain limited in practice. To address this gap, we propose ArthroCut, an autonomous policy learning framework that upgrades knee arthroplasty robots from assistive execution to context-aware action generation. ArthroCut fine-tunes a Qwen--VL backbone on a self-built, time-synchronized multimodal dataset from 21 complete cases (23,205 RGB--D pairs), integrating preoperative CT/MR, intraoperative NDI tracking of bones and end effector, RGB--D surgical video, robot state, and textual intent. The method operates on two complementary token families -- Preoperative Imaging Tokens (PIT) to encode patient-specific anatomy and planned resection planes, and Time-Aligned Surgical Tokens (TAST) to fuse real-time visual, geometric, and kinematic evidence -- and emits an interpretable action grammar under grammar/safety-constrained decoding. In bench-top experiments on a knee prosthesis across seven trials, ArthroCut achieves an average success rate of 86% over the six standard resections, significantly outperforming strong baselines trained under the same protocol. Ablations show that TAST is the principal driver of reliability while PIT provides essential anatomical grounding, and their combination yields the most stable multi-plane execution. These results indicate that aligning preoperative geometry with time-aligned intraoperative perception and translating that alignment into tokenized, constrained actions is an effective path toward robust, interpretable autonomy in orthopedic robotic surgery.
Native Intelligence Emerges from Large-Scale Clinical Practice: A Retinal Foundation Model with Deployment Efficiency
Dec 16, 2025Current retinal foundation models remain constrained by curated research datasets that lack authentic clinical context, and require extensive task-specific optimization for each application, limiting their deployment efficiency in low-resource settings. Here, we show that these barriers can be overcome by building clinical native intelligence directly from real-world medical practice. Our key insight is that large-scale telemedicine programs, where expert centers provide remote consultations across distributed facilities, represent a natural reservoir for learning clinical image interpretation. We present ReVision, a retinal foundation model that learns from the natural alignment between 485,980 color fundus photographs and their corresponding diagnostic reports, accumulated through a decade-long telemedicine program spanning 162 medical institutions across China. Through extensive evaluation across 27 ophthalmic benchmarks, we demonstrate that ReVison enables deployment efficiency with minimal local resources. Without any task-specific training, ReVision achieves zero-shot disease detection with an average AUROC of 0.946 across 12 public benchmarks and 0.952 on 3 independent clinical cohorts. When minimal adaptation is feasible, ReVision matches extensively fine-tuned alternatives while requiring orders of magnitude fewer trainable parameters and labeled examples. The learned representations also transfer effectively to new clinical sites, imaging domains, imaging modalities, and systemic health prediction tasks. In a prospective reader study with 33 ophthalmologists, ReVision's zero-shot assistance improved diagnostic accuracy by 14.8% across all experience levels. These results demonstrate that clinical native intelligence can be directly extracted from clinical archives without any further annotation to build medical AI systems suited to various low-resource settings.
Hysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
Apr 18, 2025Soft robots exhibit inherent compliance and safety, which makes them particularly suitable for applications requiring direct physical interaction with humans, such as surgical procedures. However, their nonlinear and hysteretic behavior, resulting from the properties of soft materials, presents substantial challenges for accurate modeling and control. In this study, we present a soft robotic system designed for surgical applications and propose a hysteresis-aware whole-body neural network model that accurately captures and predicts the soft robot's whole-body motion, including its hysteretic behavior. Building upon the high-precision dynamic model, we construct a highly parallel simulation environment for soft robot control and apply an on-policy reinforcement learning algorithm to efficiently train whole-body motion control strategies. Based on the trained control policy, we developed a soft robotic system for surgical applications and validated it through phantom-based laser ablation experiments in a physical environment. The results demonstrate that the hysteresis-aware modeling reduces the Mean Squared Error (MSE) by 84.95 percent compared to traditional modeling methods. The deployed control algorithm achieved a trajectory tracking error ranging from 0.126 to 0.250 mm on the real soft robot, highlighting its precision in real-world conditions. The proposed method showed strong performance in phantom-based surgical experiments and demonstrates its potential for complex scenarios, including future real-world clinical applications.
Constructing and Evaluating Digital Twins: An Intelligent Framework for DT Development
Jun 19, 2024The development of Digital Twins (DTs) represents a transformative advance for simulating and optimizing complex systems in a controlled digital space. Despite their potential, the challenge of constructing DTs that accurately replicate and predict the dynamics of real-world systems remains substantial. This paper introduces an intelligent framework for the construction and evaluation of DTs, specifically designed to enhance the accuracy and utility of DTs in testing algorithmic performance. We propose a novel construction methodology that integrates deep learning-based policy gradient techniques to dynamically tune the DT parameters, ensuring high fidelity in the digital replication of physical systems. Moreover, the Mean STate Error (MSTE) is proposed as a robust metric for evaluating the performance of algorithms within these digital space. The efficacy of our framework is demonstrated through extensive simulations that show our DT not only accurately mirrors the physical reality but also provides a reliable platform for algorithm evaluation. This work lays a foundation for future research into DT technologies, highlighting pathways for both theoretical enhancements and practical implementations in various industries.
Imperfect Digital Twin Assisted Low Cost Reinforcement Training for Multi-UAV Networks
Oct 25, 2023


Deep Reinforcement Learning (DRL) is widely used to optimize the performance of multi-UAV networks. However, the training of DRL relies on the frequent interactions between the UAVs and the environment, which consumes lots of energy due to the flying and communication of UAVs in practical experiments. Inspired by the growing digital twin (DT) technology, which can simulate the performance of algorithms in the digital space constructed by coping features of the physical space, the DT is introduced to reduce the costs of practical training, e.g., energy and hardware purchases. Different from previous DT-assisted works with an assumption of perfect reflecting real physics by virtual digital, we consider an imperfect DT model with deviations for assisting the training of multi-UAV networks. Remarkably, to trade off the training cost, DT construction cost, and the impact of deviations of DT on training, the natural and virtually generated UAV mixing deployment method is proposed. Two cascade neural networks (NN) are used to optimize the joint number of virtually generated UAVs, the DT construction cost, and the performance of multi-UAV networks. These two NNs are trained by unsupervised and reinforcement learning, both low-cost label-free training methods. Simulation results show the training cost can significantly decrease while guaranteeing the training performance. This implies that an efficient decision can be made with imperfect DTs in multi-UAV networks.
Effectively Heterogeneous Federated Learning: A Pairing and Split Learning Based Approach
Aug 26, 2023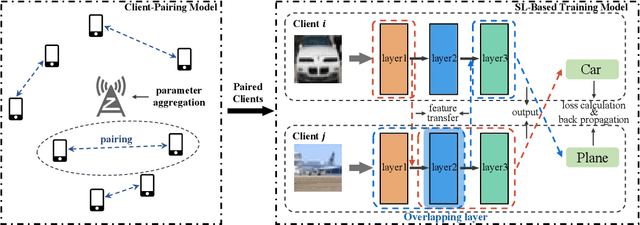
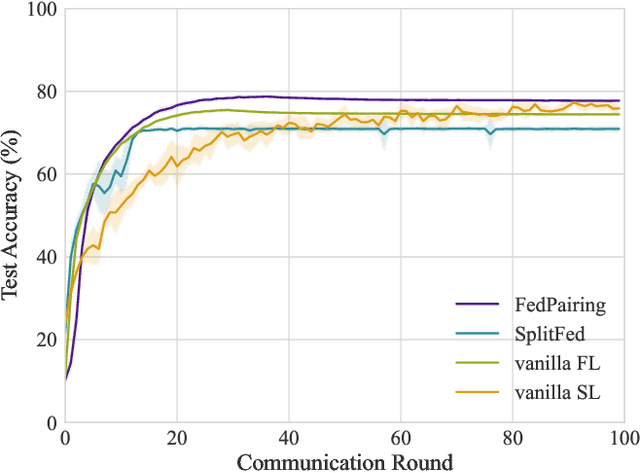
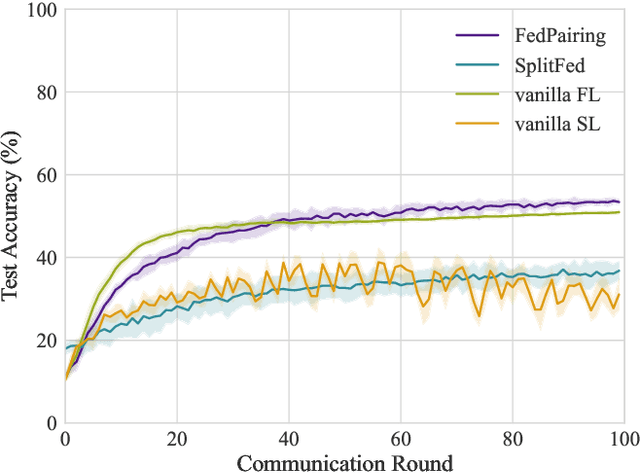

As a promising paradigm federated Learning (FL) is widely used in privacy-preserving machine learning, which allows distributed devices to collaboratively train a model while avoiding data transmission among clients. Despite its immense potential, the FL suffers from bottlenecks in training speed due to client heterogeneity, leading to escalated training latency and straggling server aggregation. To deal with this challenge, a novel split federated learning (SFL) framework that pairs clients with different computational resources is proposed, where clients are paired based on computing resources and communication rates among clients, meanwhile the neural network model is split into two parts at the logical level, and each client only computes the part assigned to it by using the SL to achieve forward inference and backward training. Moreover, to effectively deal with the client pairing problem, a heuristic greedy algorithm is proposed by reconstructing the optimization of training latency as a graph edge selection problem. Simulation results show the proposed method can significantly improve the FL training speed and achieve high performance both in independent identical distribution (IID) and Non-IID data distribution.
Distilling Knowledge from Resource Management Algorithms to Neural Networks: A Unified Training Assistance Approach
Aug 15, 2023



As a fundamental problem, numerous methods are dedicated to the optimization of signal-to-interference-plus-noise ratio (SINR), in a multi-user setting. Although traditional model-based optimization methods achieve strong performance, the high complexity raises the research of neural network (NN) based approaches to trade-off the performance and complexity. To fully leverage the high performance of traditional model-based methods and the low complexity of the NN-based method, a knowledge distillation (KD) based algorithm distillation (AD) method is proposed in this paper to improve the performance and convergence speed of the NN-based method, where traditional SINR optimization methods are employed as ``teachers" to assist the training of NNs, which are ``students", thus enhancing the performance of unsupervised and reinforcement learning techniques. This approach aims to alleviate common issues encountered in each of these training paradigms, including the infeasibility of obtaining optimal solutions as labels and overfitting in supervised learning, ensuring higher convergence performance in unsupervised learning, and improving training efficiency in reinforcement learning. Simulation results demonstrate the enhanced performance of the proposed AD-based methods compared to traditional learning methods. Remarkably, this research paves the way for the integration of traditional optimization insights and emerging NN techniques in wireless communication system optimization.
Digital Twin-Assisted Knowledge Distillation Framework for Heterogeneous Federated Learning
Mar 10, 2023



In this paper, to deal with the heterogeneity in federated learning (FL) systems, a knowledge distillation (KD) driven training framework for FL is proposed, where each user can select its neural network model on demand and distill knowledge from a big teacher model using its own private dataset. To overcome the challenge of train the big teacher model in resource limited user devices, the digital twin (DT) is exploit in the way that the teacher model can be trained at DT located in the server with enough computing resources. Then, during model distillation, each user can update the parameters of its model at either the physical entity or the digital agent. The joint problem of model selection and training offloading and resource allocation for users is formulated as a mixed integer programming (MIP) problem. To solve the problem, Q-learning and optimization are jointly used, where Q-learning selects models for users and determines whether to train locally or on the server, and optimization is used to allocate resources for users based on the output of Q-learning. Simulation results show the proposed DT-assisted KD framework and joint optimization method can significantly improve the average accuracy of users while reducing the total delay.
On-Demand Resource Management for 6G Wireless Networks Using Knowledge-Assisted Dynamic Neural Networks
Aug 02, 2022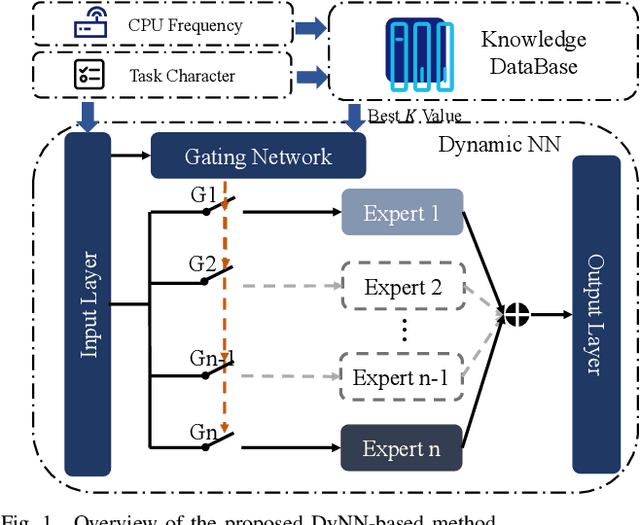
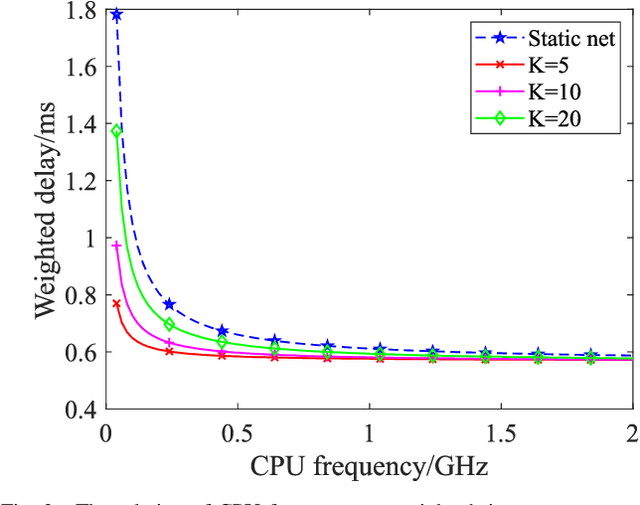
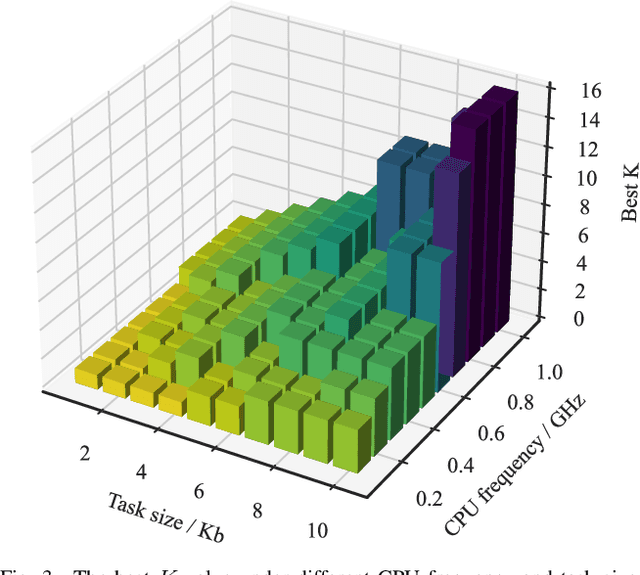
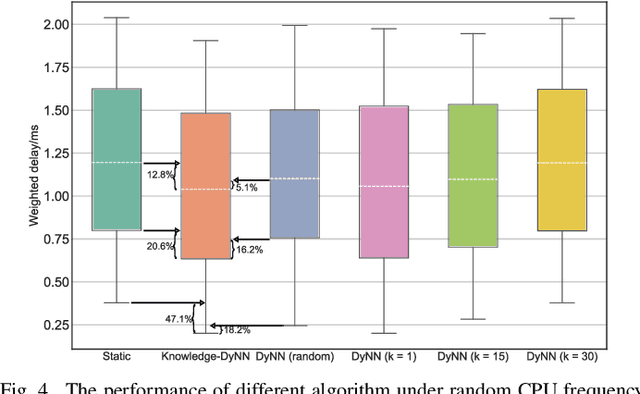
On-demand service provisioning is a critical yet challenging issue in 6G wireless communication networks, since emerging services have significantly diverse requirements and the network resources become increasingly heterogeneous and dynamic. In this paper, we study the on-demand wireless resource orchestration problem with the focus on the computing delay in orchestration decision-making process. Specifically, we take the decision-making delay into the optimization problem. Then, a dynamic neural network (DyNN)-based method is proposed, where the model complexity can be adjusted according to the service requirements. We further build a knowledge base representing the relationship among the service requirements, available computing resources, and the resource allocation performance. By exploiting the knowledge, the width of DyNN can be selected in a timely manner, further improving the performance of orchestration. Simulation results show that the proposed scheme significantly outperforms the traditional static neural network, and also shows sufficient flexibility in on-demand service provisioning.
Digital Twin-Assisted Efficient Reinforcement Learning for Edge Task Scheduling
Aug 02, 2022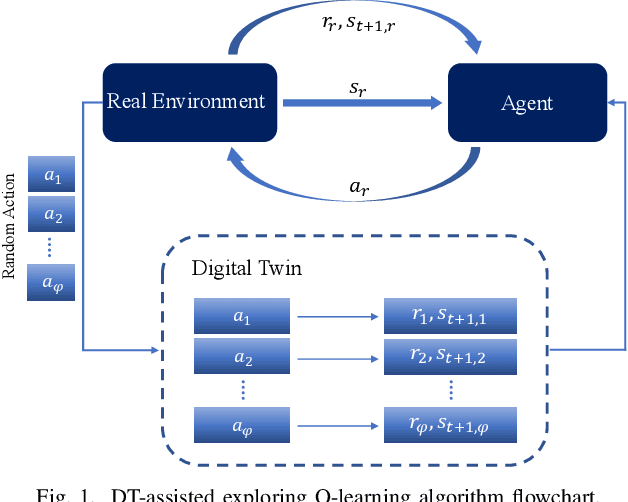
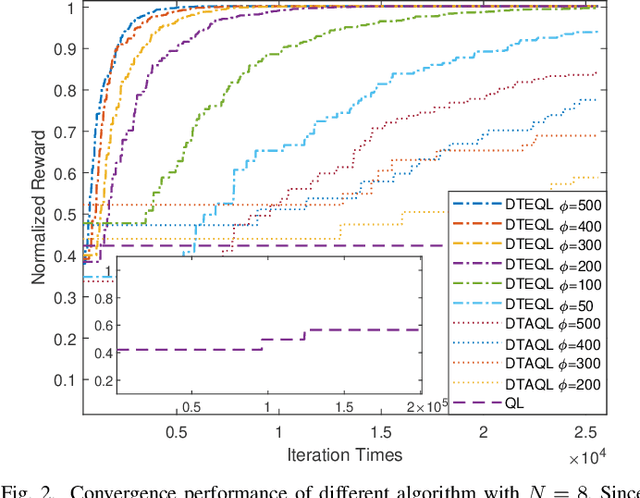


Task scheduling is a critical problem when one user offloads multiple different tasks to the edge server. When a user has multiple tasks to offload and only one task can be transmitted to server at a time, while server processes tasks according to the transmission order, the problem is NP-hard. However, it is difficult for traditional optimization methods to quickly obtain the optimal solution, while approaches based on reinforcement learning face with the challenge of excessively large action space and slow convergence. In this paper, we propose a Digital Twin (DT)-assisted RL-based task scheduling method in order to improve the performance and convergence of the RL. We use DT to simulate the results of different decisions made by the agent, so that one agent can try multiple actions at a time, or, similarly, multiple agents can interact with environment in parallel in DT. In this way, the exploration efficiency of RL can be significantly improved via DT, and thus RL can converges faster and local optimality is less likely to happen. Particularly, two algorithms are designed to made task scheduling decisions, i.e., DT-assisted asynchronous Q-learning (DTAQL) and DT-assisted exploring Q-learning (DTEQL). Simulation results show that both algorithms significantly improve the convergence speed of Q-learning by increasing the exploration efficiency.