 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHysteresis-Aware Neural Network Modeling and Whole-Body Reinforcement Learning Control of Soft Robots
Apr 18, 2025Soft robots exhibit inherent compliance and safety, which makes them particularly suitable for applications requiring direct physical interaction with humans, such as surgical procedures. However, their nonlinear and hysteretic behavior, resulting from the properties of soft materials, presents substantial challenges for accurate modeling and control. In this study, we present a soft robotic system designed for surgical applications and propose a hysteresis-aware whole-body neural network model that accurately captures and predicts the soft robot's whole-body motion, including its hysteretic behavior. Building upon the high-precision dynamic model, we construct a highly parallel simulation environment for soft robot control and apply an on-policy reinforcement learning algorithm to efficiently train whole-body motion control strategies. Based on the trained control policy, we developed a soft robotic system for surgical applications and validated it through phantom-based laser ablation experiments in a physical environment. The results demonstrate that the hysteresis-aware modeling reduces the Mean Squared Error (MSE) by 84.95 percent compared to traditional modeling methods. The deployed control algorithm achieved a trajectory tracking error ranging from 0.126 to 0.250 mm on the real soft robot, highlighting its precision in real-world conditions. The proposed method showed strong performance in phantom-based surgical experiments and demonstrates its potential for complex scenarios, including future real-world clinical applications.
Efficient and Optimal Policy Gradient Algorithm for Corrupted Multi-armed Bandits
Feb 19, 2025In this paper, we consider the stochastic multi-armed bandits problem with adversarial corruptions, where the random rewards of the arms are partially modified by an adversary to fool the algorithm. We apply the policy gradient algorithm SAMBA to this setting, and show that it is computationally efficient, and achieves a state-of-the-art $O(K\log T/\Delta) + O(C/\Delta)$ regret upper bound, where $K$ is the number of arms, $C$ is the unknown corruption level, $\Delta$ is the minimum expected reward gap between the best arm and other ones, and $T$ is the time horizon. Compared with the best existing efficient algorithm (e.g., CBARBAR), whose regret upper bound is $O(K\log^2 T/\Delta) + O(C)$, we show that SAMBA reduces one $\log T$ factor in the regret bound, while maintaining the corruption-dependent term to be linear with $C$. This is indeed asymptotically optimal. We also conduct simulations to demonstrate the effectiveness of SAMBA, and the results show that SAMBA outperforms existing baselines.
Swashplateless-elevon Actuation for a Dual-rotor Tail-sitter VTOL UAV
Sep 24, 2023



In this paper, we propose a novel swashplateless-elevon actuation (SEA) for dual-rotor tail-sitter vertical takeoff and landing (VTOL) unmanned aerial vehicles (UAVs). In contrast to the conventional elevon actuation (CEA) which controls both pitch and yaw using elevons, the SEA adopts swashplateless mechanisms to generate an extra moment through motor speed modulation to control pitch and uses elevons solely for controlling yaw, without requiring additional actuators. This decoupled control strategy mitigates the saturation of elevons' deflection needed for large pitch and yaw control actions, thus improving the UAV's control performance on trajectory tracking and disturbance rejection performance in the presence of large external disturbances. Furthermore, the SEA overcomes the actuation degradation issues experienced by the CEA when the UAV is in close proximity to the ground, leading to a smoother and more stable take-off process. We validate and compare the performances of the SEA and the CEA in various real-world flight conditions, including take-off, trajectory tracking, and hover flight and position steps under external disturbance. Experimental results demonstrate that the SEA has better performances than the CEA. Moreover, we verify the SEA's feasibility in the attitude transition process and fixed-wing-mode flight of the VTOL UAV. The results indicate that the SEA can accurately control pitch in the presence of high-speed incoming airflow and maintain a stable attitude during fixed-wing mode flight. Video of all experiments can be found in youtube.com/watch?v=Sx9Rk4Zf7sQ
Low-Rank Modular Reinforcement Learning via Muscle Synergy
Oct 26, 2022



Modular Reinforcement Learning (RL) decentralizes the control of multi-joint robots by learning policies for each actuator. Previous work on modular RL has proven its ability to control morphologically different agents with a shared actuator policy. However, with the increase in the Degree of Freedom (DoF) of robots, training a morphology-generalizable modular controller becomes exponentially difficult. Motivated by the way the human central nervous system controls numerous muscles, we propose a Synergy-Oriented LeARning (SOLAR) framework that exploits the redundant nature of DoF in robot control. Actuators are grouped into synergies by an unsupervised learning method, and a synergy action is learned to control multiple actuators in synchrony. In this way, we achieve a low-rank control at the synergy level. We extensively evaluate our method on a variety of robot morphologies, and the results show its superior efficiency and generalizability, especially on robots with a large DoF like Humanoids++ and UNIMALs.
CSSR: A Context-Aware Sequential Software Service Recommendation Model
Dec 20, 2021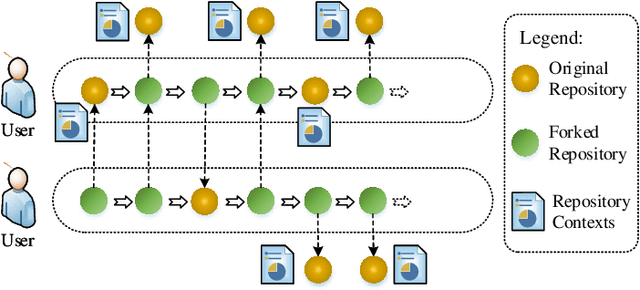
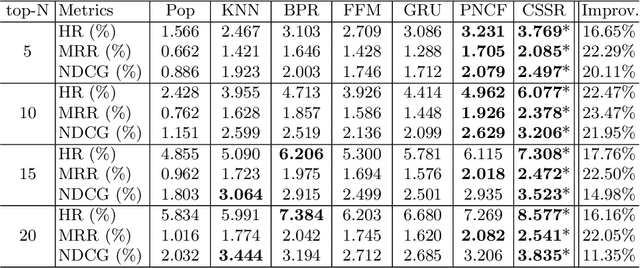
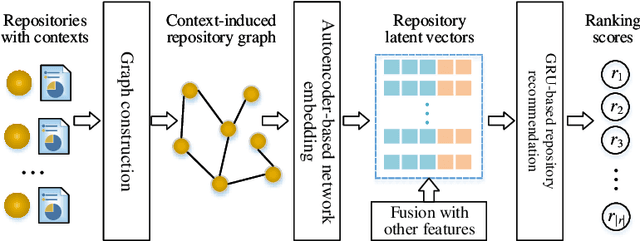
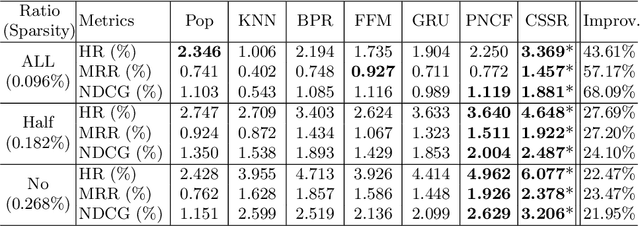
We propose a novel software service recommendation model to help users find their suitable repositories in GitHub. Our model first designs a novel context-induced repository graph embedding method to leverage rich contextual information of repositories to alleviate the difficulties caused by the data sparsity issue. It then leverages sequence information of user-repository interactions for the first time in the software service recommendation field. Specifically, a deep-learning based sequential recommendation technique is adopted to capture the dynamics of user preferences. Comprehensive experiments have been conducted on a large dataset collected from GitHub against a list of existing methods. The results illustrate the superiority of our method in various aspects.
* 16 pages, 5 figures, 2 tables, The long version of the paper with the same title in ICSoC 2021
Birds of a Feather Flock Together: A Close Look at Cooperation Emergence via Multi-Agent RL
Apr 23, 2021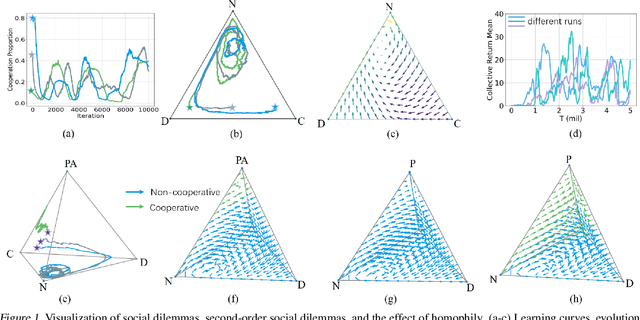
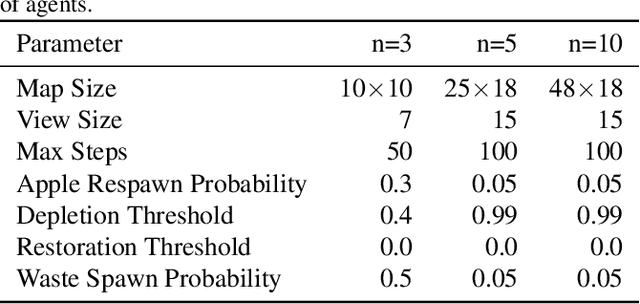
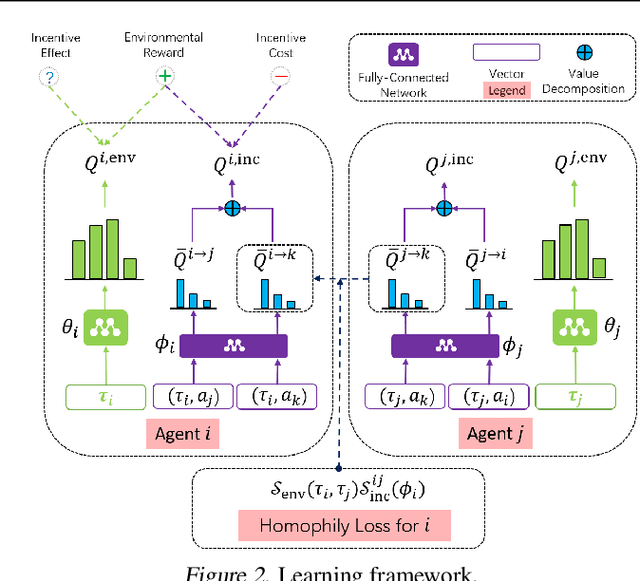

How cooperation emerges is a long-standing and interdisciplinary problem. Game-theoretical studies on social dilemmas reveal that altruistic incentives are critical to the emergence of cooperation but their analyses are limited to stateless games. For more realistic scenarios, multi-agent reinforcement learning has been used to study sequential social dilemmas (SSDs). Recent works show that learning to incentivize other agents can promote cooperation in SSDs. However, with these incentivizing mechanisms, the team cooperation level does not converge and regularly oscillates between cooperation and defection during learning. We show that a second-order social dilemma resulting from these incentive mechanisms is the main reason for such fragile cooperation. We analyze the dynamics of this second-order social dilemma and find that a typical tendency of humans, called homophily, can solve the problem. We propose a novel learning framework to encourage incentive homophily and show that it achieves stable cooperation in both public goods dilemma and tragedy of the commons dilemma.