 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Limited Shared Information in Multi-agent Multi-armed Bandit
Feb 21, 2025Multi-agent multi-armed bandit (MAMAB) is a classic collaborative learning model and has gained much attention in recent years. However, existing studies do not consider the case where an agent may refuse to share all her information with others, e.g., when some of the data contains personal privacy. In this paper, we propose a novel limited shared information multi-agent multi-armed bandit (LSI-MAMAB) model in which each agent only shares the information that she is willing to share, and propose the Balanced-ETC algorithm to help multiple agents collaborate efficiently with limited shared information. Our analysis shows that Balanced-ETC is asymptotically optimal and its average regret (on each agent) approaches a constant when there are sufficient agents involved. Moreover, to encourage agents to participate in this collaborative learning, an incentive mechanism is proposed to make sure each agent can benefit from the collaboration system. Finally, we present experimental results to validate our theoretical results.
Efficient and Optimal Policy Gradient Algorithm for Corrupted Multi-armed Bandits
Feb 19, 2025In this paper, we consider the stochastic multi-armed bandits problem with adversarial corruptions, where the random rewards of the arms are partially modified by an adversary to fool the algorithm. We apply the policy gradient algorithm SAMBA to this setting, and show that it is computationally efficient, and achieves a state-of-the-art $O(K\log T/\Delta) + O(C/\Delta)$ regret upper bound, where $K$ is the number of arms, $C$ is the unknown corruption level, $\Delta$ is the minimum expected reward gap between the best arm and other ones, and $T$ is the time horizon. Compared with the best existing efficient algorithm (e.g., CBARBAR), whose regret upper bound is $O(K\log^2 T/\Delta) + O(C)$, we show that SAMBA reduces one $\log T$ factor in the regret bound, while maintaining the corruption-dependent term to be linear with $C$. This is indeed asymptotically optimal. We also conduct simulations to demonstrate the effectiveness of SAMBA, and the results show that SAMBA outperforms existing baselines.
Proof-of-Learning with Incentive Security
Apr 13, 2024



Most concurrent blockchain systems rely heavily on the Proof-of-Work (PoW) or Proof-of-Stake (PoS) mechanisms for decentralized consensus and security assurance. However, the substantial energy expenditure stemming from computationally intensive yet meaningless tasks has raised considerable concerns surrounding traditional PoW approaches, The PoS mechanism, while free of energy consumption, is subject to security and economic issues. Addressing these issues, the paradigm of Proof-of-Useful-Work (PoUW) seeks to employ challenges of practical significance as PoW, thereby imbuing energy consumption with tangible value. While previous efforts in Proof of Learning (PoL) explored the utilization of deep learning model training SGD tasks as PoUW challenges, recent research has revealed its vulnerabilities to adversarial attacks and the theoretical hardness in crafting a byzantine-secure PoL mechanism. In this paper, we introduce the concept of incentive-security that incentivizes rational provers to behave honestly for their best interest, bypassing the existing hardness to design a PoL mechanism with computational efficiency, a provable incentive-security guarantee and controllable difficulty. Particularly, our work is secure against two attacks to the recent work of Jia et al. [2021], and also improves the computational overhead from $\Theta(1)$ to $O(\frac{\log E}{E})$. Furthermore, while most recent research assumes trusted problem providers and verifiers, our design also guarantees frontend incentive-security even when problem providers are untrusted, and verifier incentive-security that bypasses the Verifier's Dilemma. By incorporating ML training into blockchain consensus mechanisms with provable guarantees, our research not only proposes an eco-friendly solution to blockchain systems, but also provides a proposal for a completely decentralized computing power market in the new AI age.
RL-CFR: Improving Action Abstraction for Imperfect Information Extensive-Form Games with Reinforcement Learning
Mar 07, 2024Effective action abstraction is crucial in tackling challenges associated with large action spaces in Imperfect Information Extensive-Form Games (IIEFGs). However, due to the vast state space and computational complexity in IIEFGs, existing methods often rely on fixed abstractions, resulting in sub-optimal performance. In response, we introduce RL-CFR, a novel reinforcement learning (RL) approach for dynamic action abstraction. RL-CFR builds upon our innovative Markov Decision Process (MDP) formulation, with states corresponding to public information and actions represented as feature vectors indicating specific action abstractions. The reward is defined as the expected payoff difference between the selected and default action abstractions. RL-CFR constructs a game tree with RL-guided action abstractions and utilizes counterfactual regret minimization (CFR) for strategy derivation. Impressively, it can be trained from scratch, achieving higher expected payoff without increased CFR solving time. In experiments on Heads-up No-limit Texas Hold'em, RL-CFR outperforms ReBeL's replication and Slumbot, demonstrating significant win-rate margins of $64\pm 11$ and $84\pm 17$ mbb/hand, respectively.
Tempo: Confidentiality Preservation in Cloud-Based Neural Network Training
Jan 21, 2024Cloud deep learning platforms provide cost-effective deep neural network (DNN) training for customers who lack computation resources. However, cloud systems are often untrustworthy and vulnerable to attackers, leading to growing concerns about model privacy. Recently, researchers have sought to protect data privacy in deep learning by leveraging CPU trusted execution environments (TEEs), which minimize the use of cryptography, but existing works failed to simultaneously utilize the computational resources of GPUs to assist in training and prevent model leakage. This paper presents Tempo, the first cloud-based deep learning system that cooperates with TEE and distributed GPUs for efficient DNN training with model confidentiality preserved. To tackle the challenge of preserving privacy while offloading linear algebraic operations from TEE to GPUs for efficient batch computation, we introduce a customized permutation-based obfuscation algorithm to blind both inputs and model parameters. An optimization mechanism that reduces encryption operations is proposed for faster weight updates during backpropagation to speed up training. We implement Tempo and evaluate it with both training and inference for two prevalent DNNs. Empirical results indicate that Tempo outperforms baselines and offers sufficient privacy protection.
The Earth is Flat because: Investigating LLMs' Belief towards Misinformation via Persuasive Conversation
Dec 29, 2023Large Language Models (LLMs) encapsulate vast amounts of knowledge but still remain vulnerable to external misinformation. Existing research mainly studied this susceptibility behavior in a single-turn setting. However, belief can change during a multi-turn conversation, especially a persuasive one. Therefore, in this study, we delve into LLMs' susceptibility to persuasive conversations, particularly on factual questions that they can answer correctly. We first curate the Farm (i.e., Fact to Misinform) dataset, which contains factual questions paired with systematically generated persuasive misinformation. Then, we develop a testing framework to track LLMs' belief changes in a persuasive dialogue. Through extensive experiments, we find that LLMs' correct beliefs on factual knowledge can be easily manipulated by various persuasive strategies.
Cost-efficient Crowdsourcing for Span-based Sequence Labeling: Worker Selection and Data Augmentation
May 11, 2023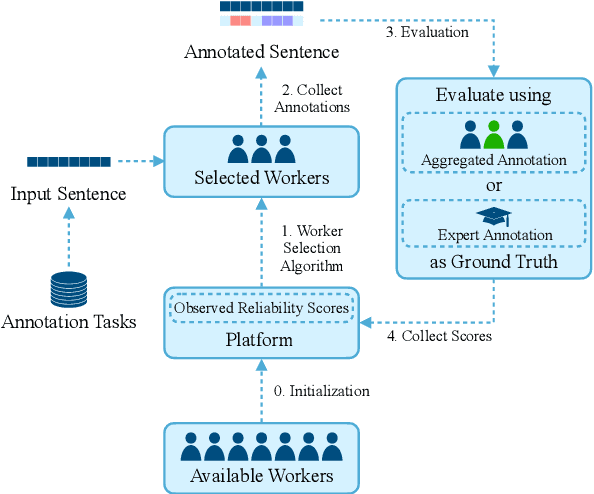

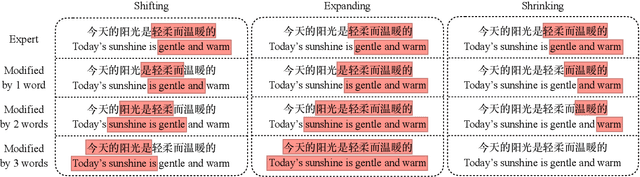
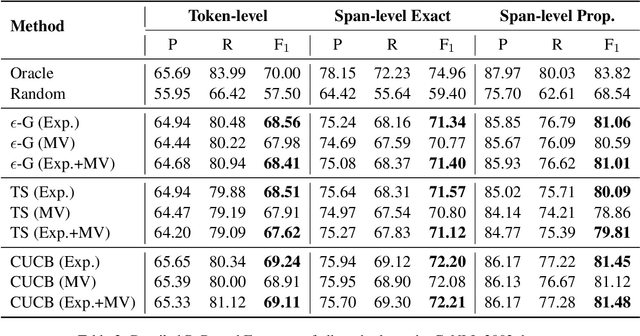
This paper introduces a novel worker selection algorithm, enhancing annotation quality and reducing costs in challenging span-based sequence labeling tasks in Natural Language Processing (NLP). Unlike previous studies targeting simpler tasks, this study contends with the complexities of label interdependencies in sequence labeling tasks. The proposed algorithm utilizes a Combinatorial Multi-Armed Bandit (CMAB) approach for worker selection. The challenge of dealing with imbalanced and small-scale datasets, which hinders offline simulation of worker selection, is tackled using an innovative data augmentation method termed shifting, expanding, and shrinking (SES). The SES method is designed specifically for sequence labeling tasks. Rigorous testing on CoNLL 2003 NER and Chinese OEI datasets showcased the algorithm's efficiency, with an increase in F1 score up to 100.04% of the expert-only baseline, alongside cost savings up to 65.97%. The paper also encompasses a dataset-independent test emulating annotation evaluation through a Bernoulli distribution, which still led to an impressive 97.56% F1 score of the expert baseline and 59.88% cost savings. This research addresses and overcomes numerous obstacles in worker selection for complex NLP tasks.
Effective Multi-User Delay-Constrained Scheduling with Deep Recurrent Reinforcement Learning
Aug 30, 2022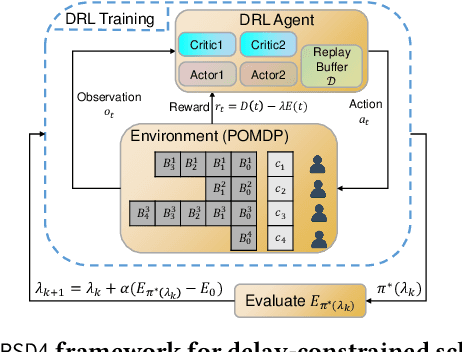

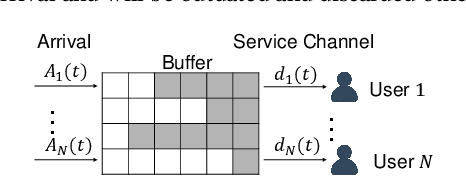
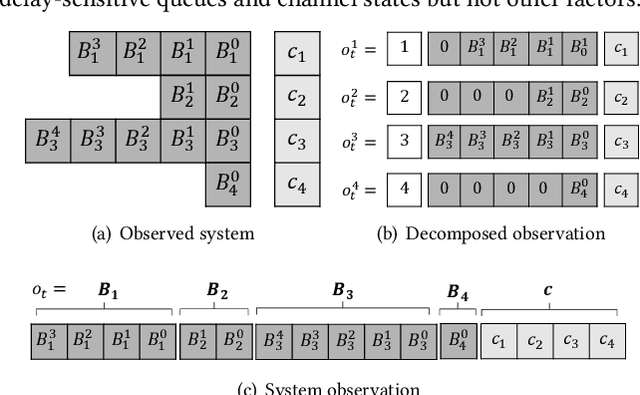
Multi-user delay constrained scheduling is important in many real-world applications including wireless communication, live streaming, and cloud computing. Yet, it poses a critical challenge since the scheduler needs to make real-time decisions to guarantee the delay and resource constraints simultaneously without prior information of system dynamics, which can be time-varying and hard to estimate. Moreover, many practical scenarios suffer from partial observability issues, e.g., due to sensing noise or hidden correlation. To tackle these challenges, we propose a deep reinforcement learning (DRL) algorithm, named Recurrent Softmax Delayed Deep Double Deterministic Policy Gradient ($\mathtt{RSD4}$), which is a data-driven method based on a Partially Observed Markov Decision Process (POMDP) formulation. $\mathtt{RSD4}$ guarantees resource and delay constraints by Lagrangian dual and delay-sensitive queues, respectively. It also efficiently tackles partial observability with a memory mechanism enabled by the recurrent neural network (RNN) and introduces user-level decomposition and node-level merging to ensure scalability. Extensive experiments on simulated/real-world datasets demonstrate that $\mathtt{RSD4}$ is robust to system dynamics and partially observable environments, and achieves superior performances over existing DRL and non-DRL-based methods.
Simultaneously Achieving Sublinear Regret and Constraint Violations for Online Convex Optimization with Time-varying Constraints
Nov 15, 2021
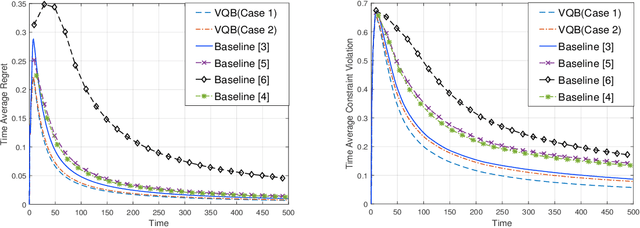

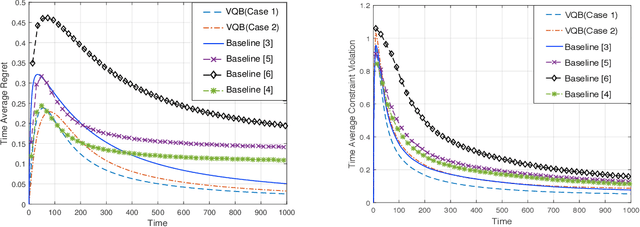
In this paper, we develop a novel virtual-queue-based online algorithm for online convex optimization (OCO) problems with long-term and time-varying constraints and conduct a performance analysis with respect to the dynamic regret and constraint violations. We design a new update rule of dual variables and a new way of incorporating time-varying constraint functions into the dual variables. To the best of our knowledge, our algorithm is the first parameter-free algorithm to simultaneously achieve sublinear dynamic regret and constraint violations. Our proposed algorithm also outperforms the state-of-the-art results in many aspects, e.g., our algorithm does not require the Slater condition. Meanwhile, for a group of practical and widely-studied constrained OCO problems in which the variation of consecutive constraints is smooth enough across time, our algorithm achieves $O(1)$ constraint violations. Furthermore, we extend our algorithm and analysis to the case when the time horizon $T$ is unknown. Finally, numerical experiments are conducted to validate the theoretical guarantees of our algorithm, and some applications of our proposed framework will be outlined.
* 31 pages, it has been accepted at Performance 2021
Continuous Mean-Covariance Bandits
Feb 24, 2021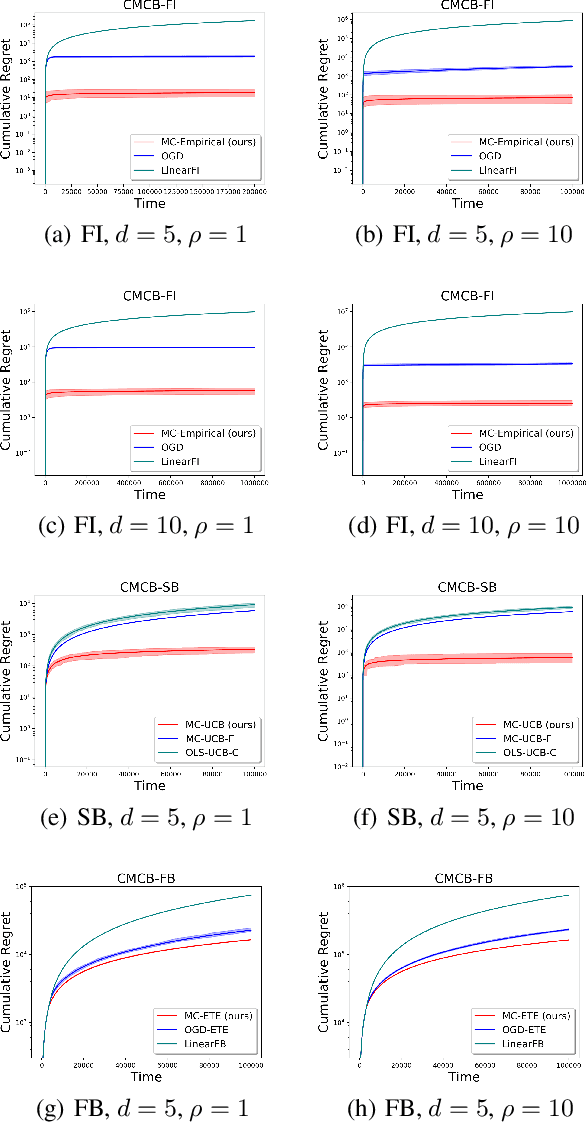
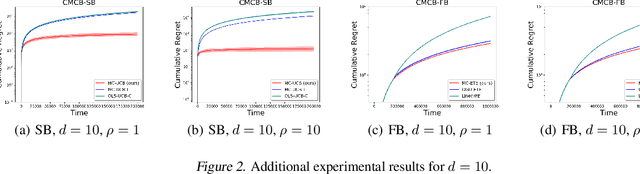
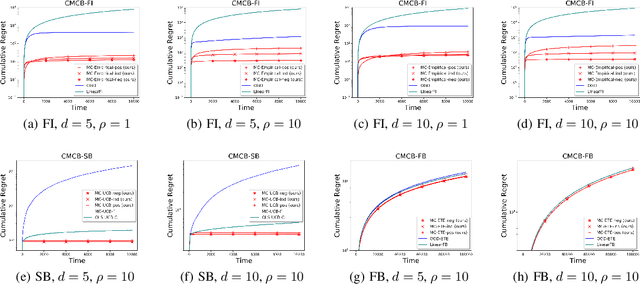
Existing risk-aware multi-armed bandit models typically focus on risk measures of individual options such as variance. As a result, they cannot be directly applied to important real-world online decision making problems with correlated options. In this paper, we propose a novel Continuous Mean-Covariance Bandit (CMCB) model to explicitly take into account option correlation. Specifically, in CMCB, there is a learner who sequentially chooses weight vectors on given options and observes random feedback according to the decisions. The agent's objective is to achieve the best trade-off between reward and risk, measured with option covariance. To capture important reward observation scenarios in practice, we consider three feedback settings, i.e., full-information, semi-bandit and full-bandit feedback. We propose novel algorithms with the optimal regrets (within logarithmic factors), and provide matching lower bounds to validate their optimalities. Our experimental results also demonstrate the superiority of the proposed algorithms. To the best of our knowledge, this is the first work that considers option correlation in risk-aware bandits and explicitly quantifies how arbitrary covariance structures impact the learning performance.