 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL4Gaze: Unleashing Vision-Language Models for Gaze Following
Dec 23, 2025Human gaze provides essential cues for interpreting attention, intention, and social interaction in visual scenes, yet gaze understanding remains largely unexplored in current vision-language models (VLMs). While recent VLMs achieve strong scene-level reasoning across a range of visual tasks, there exists no benchmark that systematically evaluates or trains them for gaze interpretation, leaving open the question of whether gaze understanding can emerge from general-purpose vision-language pre-training. To address this gap, we introduce VL4Gaze, the first large-scale benchmark designed to investigate, evaluate, and unlock the potential of VLMs for gaze understanding. VL4Gaze contains 489K automatically generated question-answer pairs across 124K images and formulates gaze understanding as a unified VQA problem through four complementary tasks: (1) gaze object description, (2) gaze direction description, (3) gaze point location, and (4) ambiguous question recognition. We comprehensively evaluate both commercial and open-source VLMs under in-context learning and fine-tuning settings. The results show that even large-scale VLMs struggle to reliably infer gaze semantics and spatial localization without task-specific supervision. In contrast, training on VL4Gaze brings substantial and consistent improvements across all tasks, highlighting the importance of targeted multi-task supervision for developing gaze understanding capabilities in VLMs. We will release the dataset and code to support further research and development in this direction.
CLIP-driven Dual Feature Enhancing Network for Gaze Estimation
Feb 27, 2025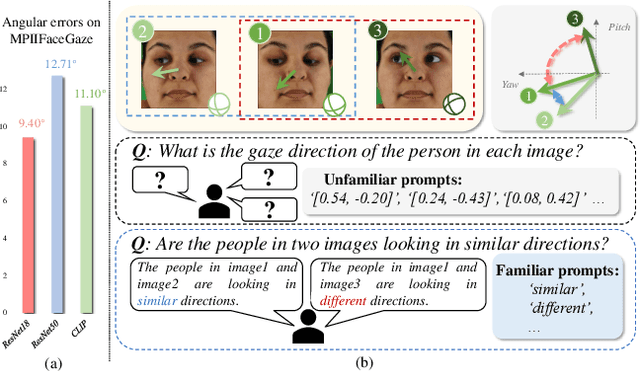
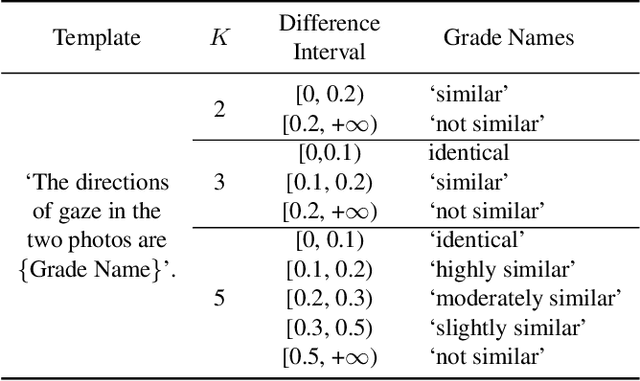
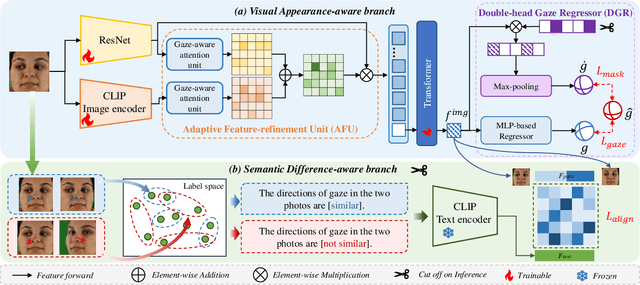
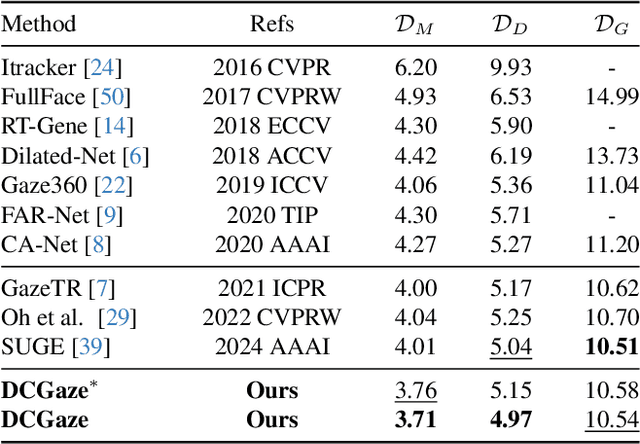
The complex application scenarios have raised critical requirements for precise and generalizable gaze estimation methods. Recently, the pre-trained CLIP has achieved remarkable performance on various vision tasks, but its potentials have not been fully exploited in gaze estimation. In this paper, we propose a novel CLIP-driven Dual Feature Enhancing Network (CLIP-DFENet), which boosts gaze estimation performance with the help of CLIP under a novel `main-side' collaborative enhancing strategy. Accordingly, a Language-driven Differential Module (LDM) is designed on the basis of the CLIP's text encoder to reveal the semantic difference of gaze. This module could empower our Core Feature Extractor with the capability of characterizing the gaze-related semantic information. Moreover, a Vision-driven Fusion Module (VFM) is introduced to strengthen the generalized and valuable components of visual embeddings obtained via CLIP's image encoder, and utilizes them to further improve the generalization of the features captured by Core Feature Extractor. Finally, a robust Double-head Gaze Regressor is adopted to map the enhanced features to gaze directions. Extensive experimental results on four challenging datasets over within-domain and cross-domain tasks demonstrate the discriminability and generalizability of our CLIP-DFENet.
Suppressing Uncertainty in Gaze Estimation
Dec 17, 2024
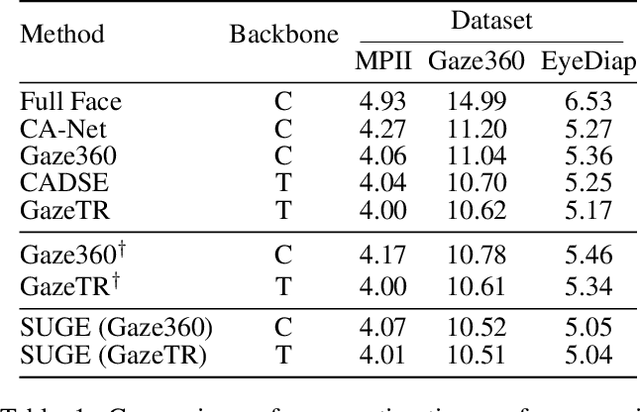
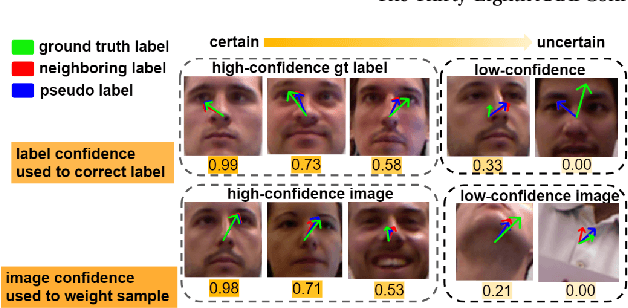
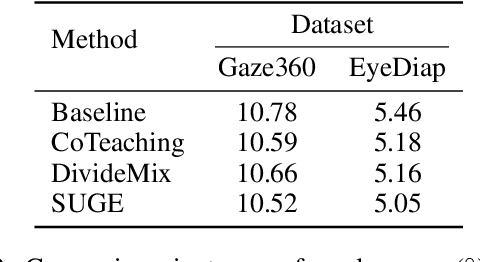
Uncertainty in gaze estimation manifests in two aspects: 1) low-quality images caused by occlusion, blurriness, inconsistent eye movements, or even non-face images; 2) incorrect labels resulting from the misalignment between the labeled and actual gaze points during the annotation process. Allowing these uncertainties to participate in training hinders the improvement of gaze estimation. To tackle these challenges, in this paper, we propose an effective solution, named Suppressing Uncertainty in Gaze Estimation (SUGE), which introduces a novel triplet-label consistency measurement to estimate and reduce the uncertainties. Specifically, for each training sample, we propose to estimate a novel ``neighboring label'' calculated by a linearly weighted projection from the neighbors to capture the similarity relationship between image features and their corresponding labels, which can be incorporated with the predicted pseudo label and ground-truth label for uncertainty estimation. By modeling such triplet-label consistency, we can measure the qualities of both images and labels, and further largely reduce the negative effects of unqualified images and wrong labels through our designed sample weighting and label correction strategies. Experimental results on the gaze estimation benchmarks indicate that our proposed SUGE achieves state-of-the-art performance.
Generative Edge Detection with Stable Diffusion
Oct 04, 2024



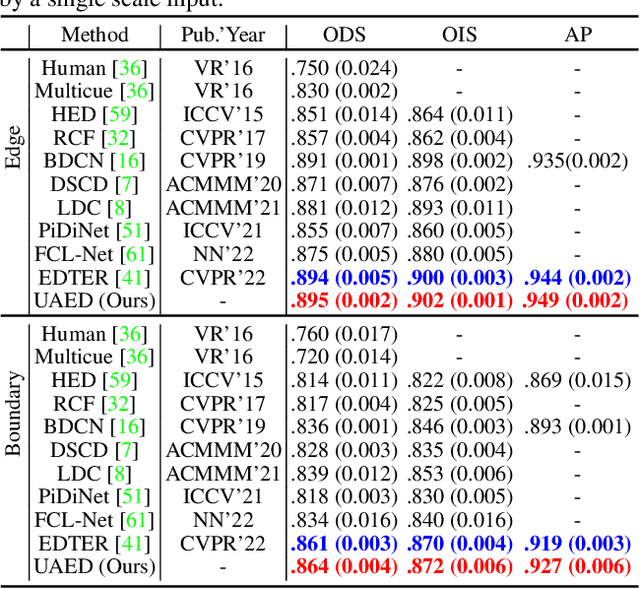
Edge detection is typically viewed as a pixel-level classification problem mainly addressed by discriminative methods. Recently, generative edge detection methods, especially diffusion model based solutions, are initialized in the edge detection task. Despite great potential, the retraining of task-specific designed modules and multi-step denoising inference limits their broader applications. Upon closer investigation, we speculate that part of the reason is the under-exploration of the rich discriminative information encoded in extensively pre-trained large models (\eg, stable diffusion models). Thus motivated, we propose a novel approach, named Generative Edge Detector (GED), by fully utilizing the potential of the pre-trained stable diffusion model. Our model can be trained and inferred efficiently without specific network design due to the rich high-level and low-level prior knowledge empowered by the pre-trained stable diffusion. Specifically, we propose to finetune the denoising U-Net and predict latent edge maps directly, by taking the latent image feature maps as input. Additionally, due to the subjectivity and ambiguity of the edges, we also incorporate the granularity of the edges into the denoising U-Net model as one of the conditions to achieve controllable and diverse predictions. Furthermore, we devise a granularity regularization to ensure the relative granularity relationship of the multiple predictions. We conduct extensive experiments on multiple datasets and achieve competitive performance (\eg, 0.870 and 0.880 in terms of ODS and OIS on the BSDS test dataset).
Cross-Dataset Gaze Estimation by Evidential Inter-intra Fusion
Sep 07, 2024



Achieving accurate and reliable gaze predictions in complex and diverse environments remains challenging. Fortunately, it is straightforward to access diverse gaze datasets in real-world applications. We discover that training these datasets jointly can significantly improve the generalization of gaze estimation, which is overlooked in previous works. However, due to the inherent distribution shift across different datasets, simply mixing multiple dataset decreases the performance in the original domain despite gaining better generalization abilities. To address the problem of ``cross-dataset gaze estimation'', we propose a novel Evidential Inter-intra Fusion EIF framework, for training a cross-dataset model that performs well across all source and unseen domains. Specifically, we build independent single-dataset branches for various datasets where the data space is partitioned into overlapping subspaces within each dataset for local regression, and further create a cross-dataset branch to integrate the generalizable features from single-dataset branches. Furthermore, evidential regressors based on the Normal and Inverse-Gamma (NIG) distribution are designed to additionally provide uncertainty estimation apart from predicting gaze. Building upon this foundation, our proposed framework achieves both intra-evidential fusion among multiple local regressors within each dataset and inter-evidential fusion among multiple branches by Mixture \textbfof Normal Inverse-Gamma (MoNIG distribution. Experiments demonstrate that our method consistently achieves notable improvements in both source domains and unseen domains.
From Text to CQL: Bridging Natural Language and Corpus Search Engine
Feb 21, 2024



Natural Language Processing (NLP) technologies have revolutionized the way we interact with information systems, with a significant focus on converting natural language queries into formal query languages such as SQL. However, less emphasis has been placed on the Corpus Query Language (CQL), a critical tool for linguistic research and detailed analysis within text corpora. The manual construction of CQL queries is a complex and time-intensive task that requires a great deal of expertise, which presents a notable challenge for both researchers and practitioners. This paper presents the first text-to-CQL task that aims to automate the translation of natural language into CQL. We present a comprehensive framework for this task, including a specifically curated large-scale dataset and methodologies leveraging large language models (LLMs) for effective text-to-CQL task. In addition, we established advanced evaluation metrics to assess the syntactic and semantic accuracy of the generated queries. We created innovative LLM-based conversion approaches and detailed experiments. The results demonstrate the efficacy of our methods and provide insights into the complexities of text-to-CQL task.
Cost-efficient Crowdsourcing for Span-based Sequence Labeling: Worker Selection and Data Augmentation
May 11, 2023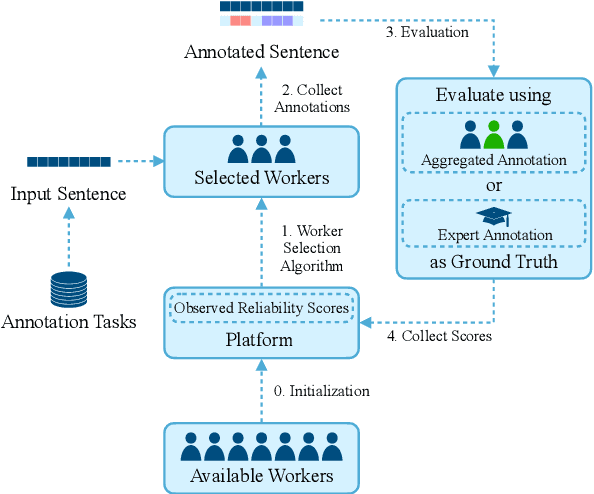

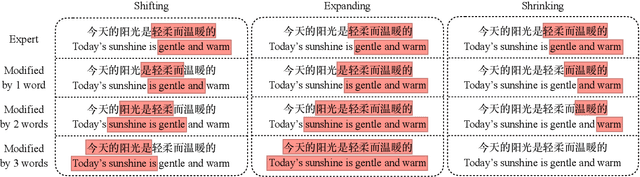
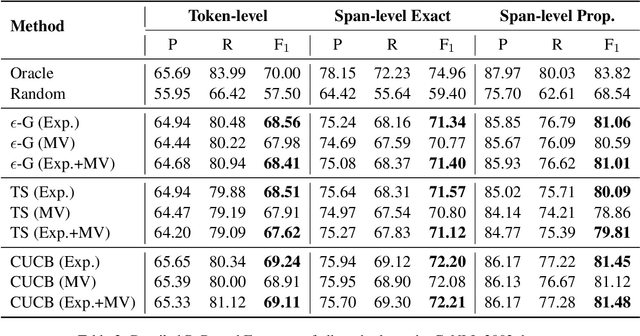
This paper introduces a novel worker selection algorithm, enhancing annotation quality and reducing costs in challenging span-based sequence labeling tasks in Natural Language Processing (NLP). Unlike previous studies targeting simpler tasks, this study contends with the complexities of label interdependencies in sequence labeling tasks. The proposed algorithm utilizes a Combinatorial Multi-Armed Bandit (CMAB) approach for worker selection. The challenge of dealing with imbalanced and small-scale datasets, which hinders offline simulation of worker selection, is tackled using an innovative data augmentation method termed shifting, expanding, and shrinking (SES). The SES method is designed specifically for sequence labeling tasks. Rigorous testing on CoNLL 2003 NER and Chinese OEI datasets showcased the algorithm's efficiency, with an increase in F1 score up to 100.04% of the expert-only baseline, alongside cost savings up to 65.97%. The paper also encompasses a dataset-independent test emulating annotation evaluation through a Bernoulli distribution, which still led to an impressive 97.56% F1 score of the expert baseline and 59.88% cost savings. This research addresses and overcomes numerous obstacles in worker selection for complex NLP tasks.
The Treasure Beneath Multiple Annotations: An Uncertainty-aware Edge Detector
Mar 21, 2023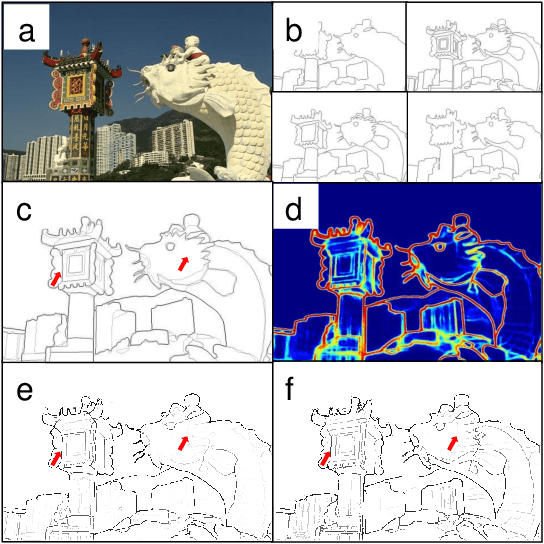
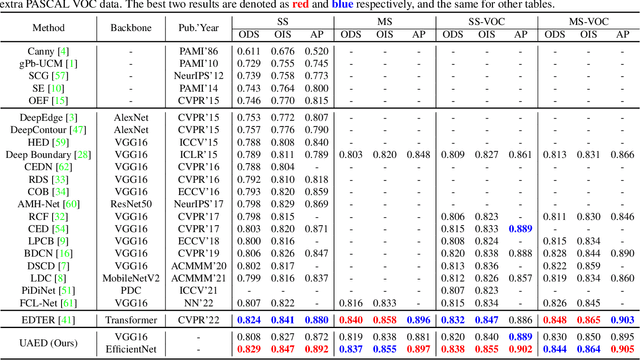
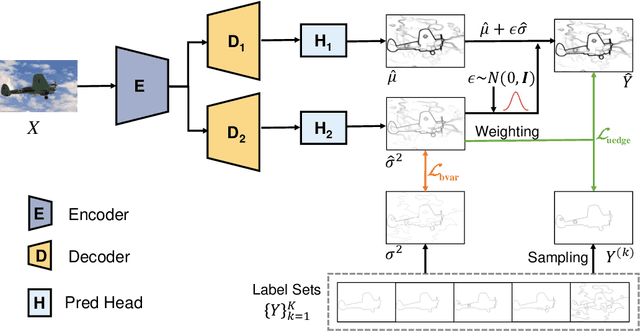
Deep learning-based edge detectors heavily rely on pixel-wise labels which are often provided by multiple annotators. Existing methods fuse multiple annotations using a simple voting process, ignoring the inherent ambiguity of edges and labeling bias of annotators. In this paper, we propose a novel uncertainty-aware edge detector (UAED), which employs uncertainty to investigate the subjectivity and ambiguity of diverse annotations. Specifically, we first convert the deterministic label space into a learnable Gaussian distribution, whose variance measures the degree of ambiguity among different annotations. Then we regard the learned variance as the estimated uncertainty of the predicted edge maps, and pixels with higher uncertainty are likely to be hard samples for edge detection. Therefore we design an adaptive weighting loss to emphasize the learning from those pixels with high uncertainty, which helps the network to gradually concentrate on the important pixels. UAED can be combined with various encoder-decoder backbones, and the extensive experiments demonstrate that UAED achieves superior performance consistently across multiple edge detection benchmarks. The source code is available at \url{https://github.com/ZhouCX117/UAED}
Uncertainty-Driven Action Quality Assessment
Jul 29, 2022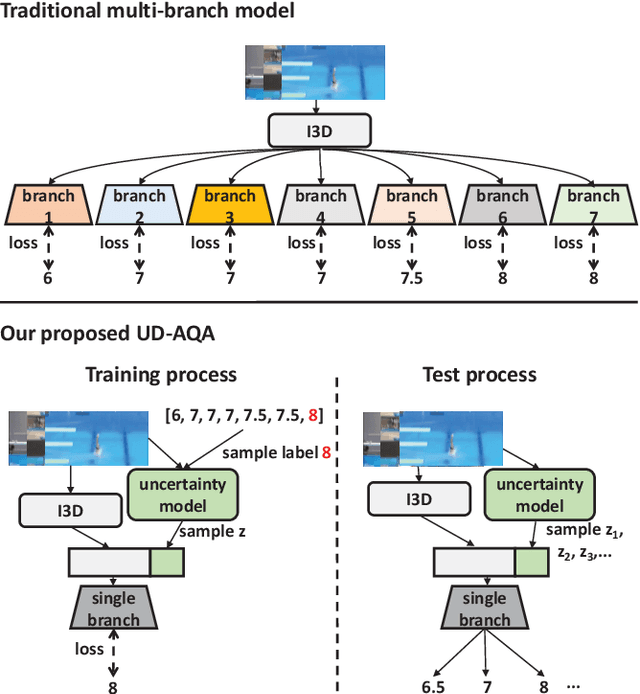
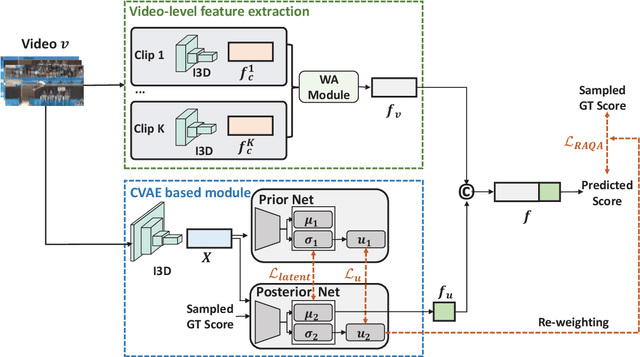
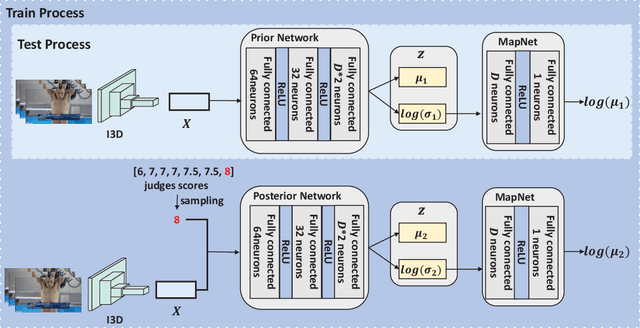
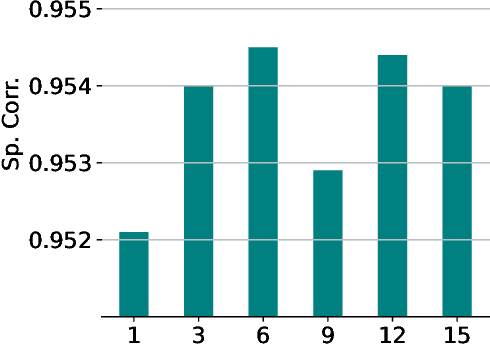
Automatic action quality assessment (AQA) has attracted more interests due to its wide applications. However, existing AQA methods usually employ the multi-branch models to generate multiple scores, which is not flexible for dealing with a variable number of judges. In this paper, we propose a novel Uncertainty-Driven AQA (UD-AQA) model to generate multiple predictions only using one single branch. Specifically, we design a CVAE (Conditional Variational Auto-Encoder) based module to encode the uncertainty, where multiple scores can be produced by sampling from the learned latent space multiple times. Moreover, we output the estimation of uncertainty and utilize the predicted uncertainty to re-weight AQA regression loss, which can reduce the contributions of uncertain samples for training. We further design an uncertainty-guided training strategy to dynamically adjust the learning order of the samples from low uncertainty to high uncertainty. The experiments show that our proposed method achieves new state-of-the-art results on the Olympic events MTL-AQA and surgical skill JIGSAWS datasets.
BLCU-ICALL at SemEval-2022 Task 1: Cross-Attention Multitasking Framework for Definition Modeling
Apr 16, 2022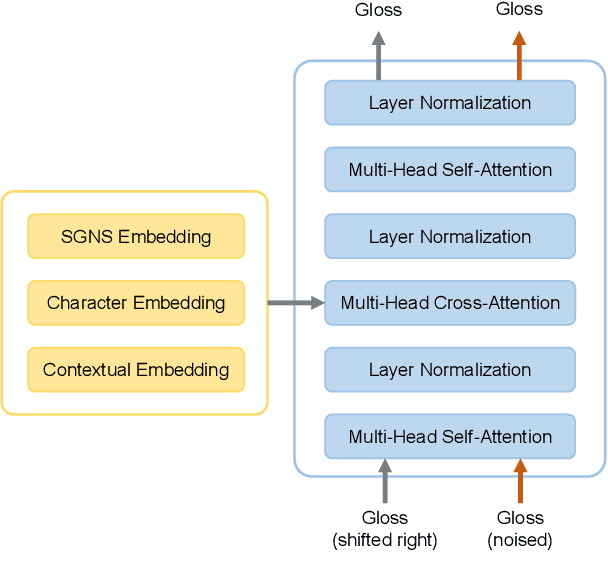
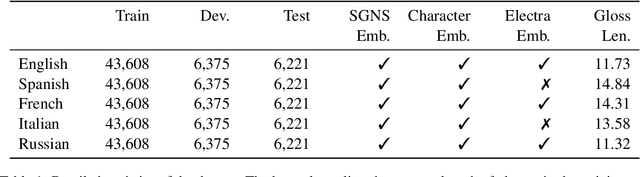
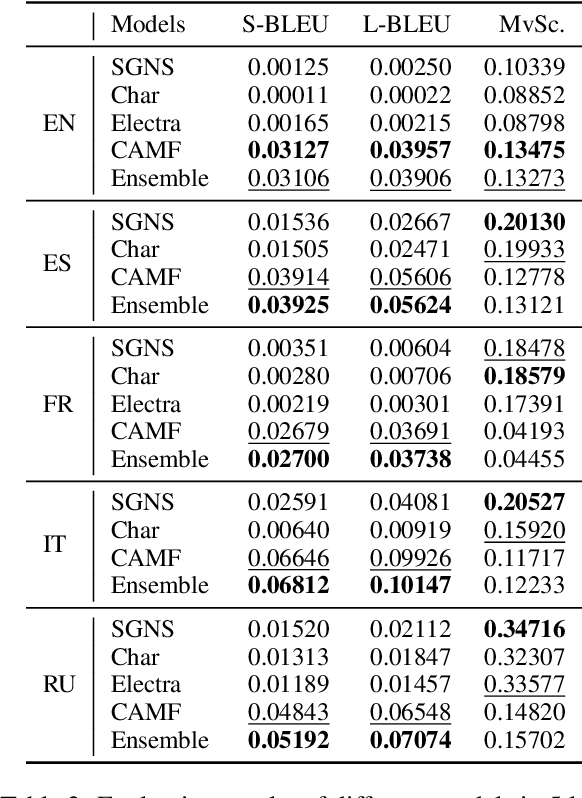
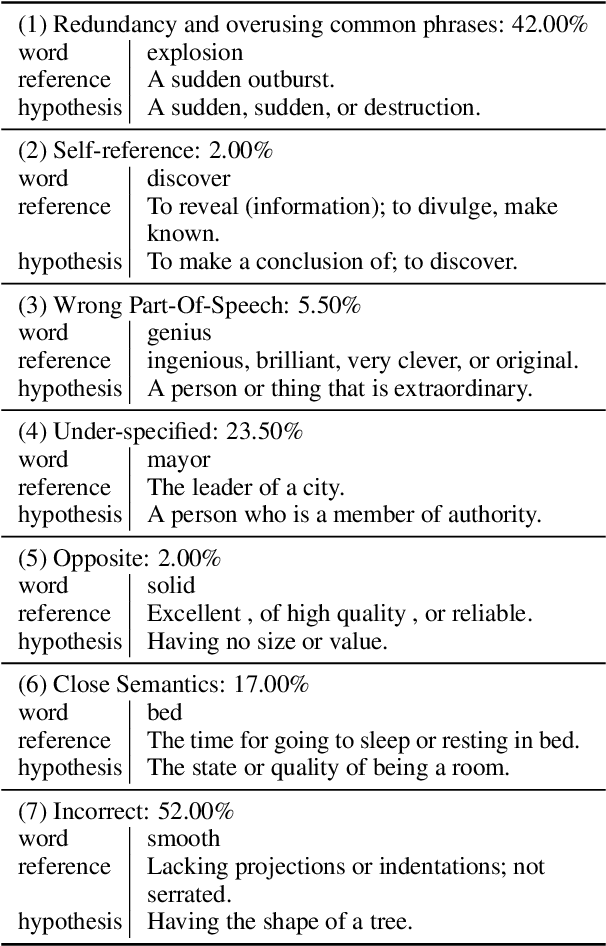
This paper describes the BLCU-ICALL system used in the SemEval-2022 Task 1 Comparing Dictionaries and Word Embeddings, the Definition Modeling subtrack, achieving 1st on Italian, 2nd on Spanish and Russian, and 3rd on English and French. We propose a transformer-based multitasking framework to explore the task. The framework integrates multiple embedding architectures through the cross-attention mechanism, and captures the structure of glosses through a masking language model objective. Additionally, we also investigate a simple but effective model ensembling strategy to further improve the robustness. The evaluation results show the effectiveness of our solution. We release our code at: https://github.com/blcuicall/SemEval2022-Task1-DM.