 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCyIN: Cyclic Informative Latent Space for Bridging Complete and Incomplete Multimodal Learning
Feb 04, 2026Multimodal machine learning, mimicking the human brain's ability to integrate various modalities has seen rapid growth. Most previous multimodal models are trained on perfectly paired multimodal input to reach optimal performance. In real-world deployments, however, the presence of modality is highly variable and unpredictable, causing the pre-trained models in suffering significant performance drops and fail to remain robust with dynamic missing modalities circumstances. In this paper, we present a novel Cyclic INformative Learning framework (CyIN) to bridge the gap between complete and incomplete multimodal learning. Specifically, we firstly build an informative latent space by adopting token- and label-level Information Bottleneck (IB) cyclically among various modalities. Capturing task-related features with variational approximation, the informative bottleneck latents are purified for more efficient cross-modal interaction and multimodal fusion. Moreover, to supplement the missing information caused by incomplete multimodal input, we propose cross-modal cyclic translation by reconstruct the missing modalities with the remained ones through forward and reverse propagation process. With the help of the extracted and reconstructed informative latents, CyIN succeeds in jointly optimizing complete and incomplete multimodal learning in one unified model. Extensive experiments on 4 multimodal datasets demonstrate the superior performance of our method in both complete and diverse incomplete scenarios.
Intention Chain-of-Thought Prompting with Dynamic Routing for Code Generation
Dec 16, 2025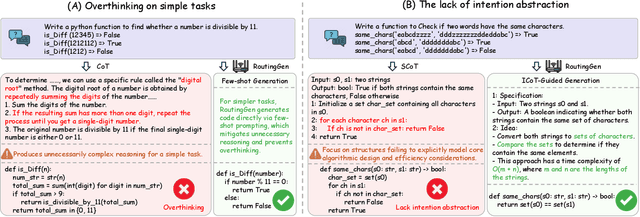
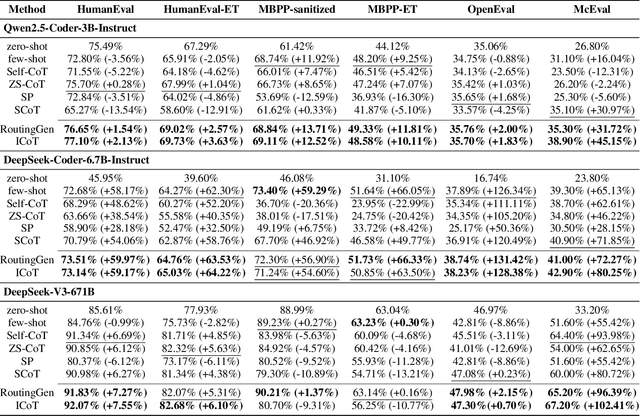
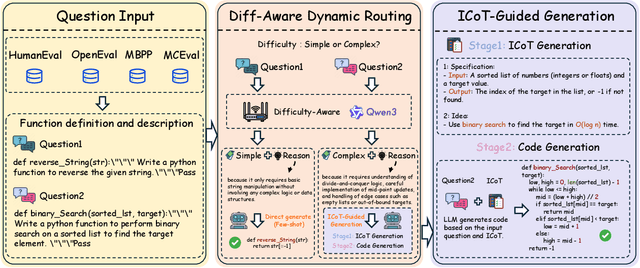
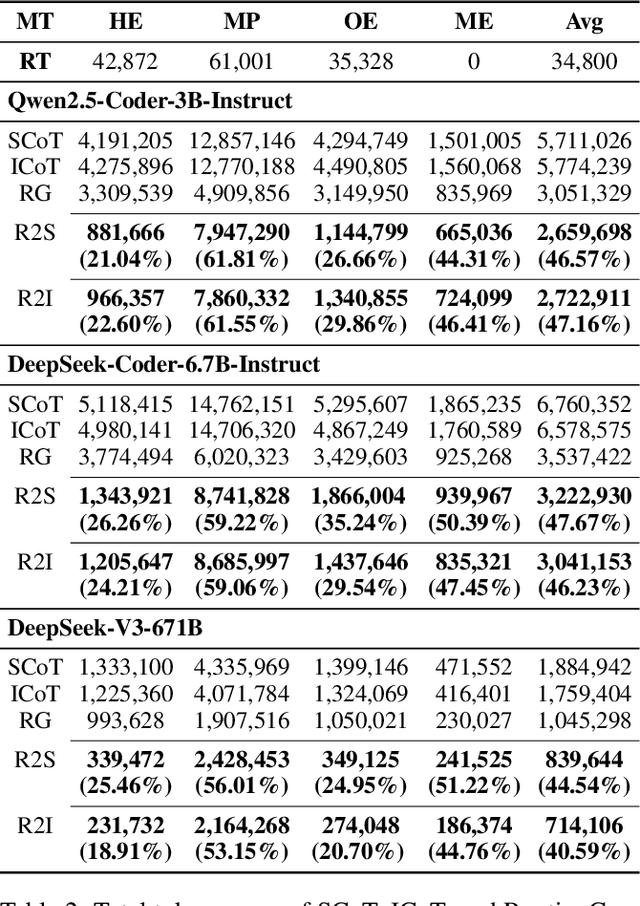
Large language models (LLMs) exhibit strong generative capabilities and have shown great potential in code generation. Existing chain-of-thought (CoT) prompting methods enhance model reasoning by eliciting intermediate steps, but suffer from two major limitations: First, their uniform application tends to induce overthinking on simple tasks. Second, they lack intention abstraction in code generation, such as explicitly modeling core algorithmic design and efficiency, leading models to focus on surface-level structures while neglecting the global problem objective. Inspired by the cognitive economy principle of engaging structured reasoning only when necessary to conserve cognitive resources, we propose RoutingGen, a novel difficulty-aware routing framework that dynamically adapts prompting strategies for code generation. For simple tasks, it adopts few-shot prompting; for more complex ones, it invokes a structured reasoning strategy, termed Intention Chain-of-Thought (ICoT), which we introduce to guide the model in capturing task intention, such as the core algorithmic logic and its time complexity. Experiments across three models and six standard code generation benchmarks show that RoutingGen achieves state-of-the-art performance in most settings, while reducing total token usage by 46.37% on average across settings. Furthermore, ICoT outperforms six existing prompting baselines on challenging benchmarks.
AMSnet 2.0: A Large AMS Database with AI Segmentation for Net Detection
May 14, 2025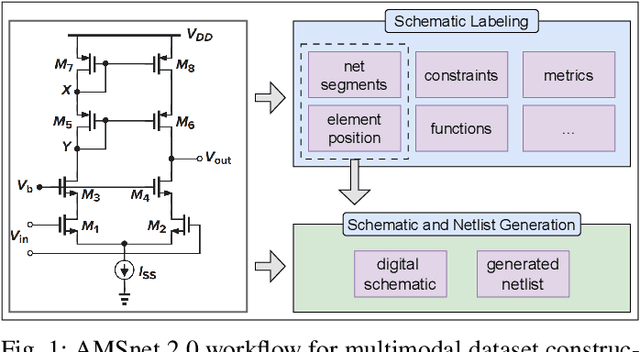
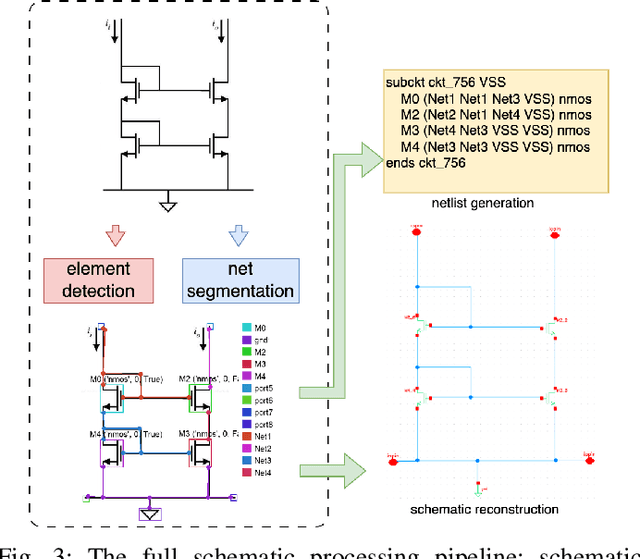
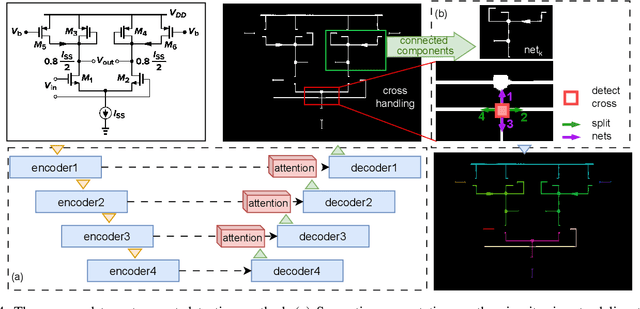
Current multimodal large language models (MLLMs) struggle to understand circuit schematics due to their limited recognition capabilities. This could be attributed to the lack of high-quality schematic-netlist training data. Existing work such as AMSnet applies schematic parsing to generate netlists. However, these methods rely on hard-coded heuristics and are difficult to apply to complex or noisy schematics in this paper. We therefore propose a novel net detection mechanism based on segmentation with high robustness. The proposed method also recovers positional information, allowing digital reconstruction of schematics. We then expand AMSnet dataset with schematic images from various sources and create AMSnet 2.0. AMSnet 2.0 contains 2,686 circuits with schematic images, Spectre-formatted netlists, OpenAccess digital schematics, and positional information for circuit components and nets, whereas AMSnet only includes 792 circuits with SPICE netlists but no digital schematics.
SS-CTML: Self-Supervised Cross-Task Mutual Learning for CT Image Reconstruction
Dec 31, 2024



Supervised deep-learning (SDL) techniques with paired training datasets have been widely studied for X-ray computed tomography (CT) image reconstruction. However, due to the difficulties of obtaining paired training datasets in clinical routine, the SDL methods are still away from common uses in clinical practices. In recent years, self-supervised deep-learning (SSDL) techniques have shown great potential for the studies of CT image reconstruction. In this work, we propose a self-supervised cross-task mutual learning (SS-CTML) framework for CT image reconstruction. Specifically, a sparse-view scanned and a limited-view scanned sinogram data are first extracted from a full-view scanned sinogram data, which results in three individual reconstruction tasks, i.e., the full-view CT (FVCT) reconstruction, the sparse-view CT (SVCT) reconstruction, and limited-view CT (LVCT) reconstruction. Then, three neural networks are constructed for the three reconstruction tasks. Considering that the ultimate goals of the three tasks are all to reconstruct high-quality CT images, we therefore construct a set of cross-task mutual learning objectives for the three tasks, in which way, the three neural networks can be self-supervised optimized by learning from each other. Clinical datasets are adopted to evaluate the effectiveness of the proposed framework. Experimental results demonstrate that the SS-CTML framework can obtain promising CT image reconstruction performance in terms of both quantitative and qualitative measurements.
Enhancing Data Quality through Self-learning on Imbalanced Financial Risk Data
Sep 15, 2024



In the financial risk domain, particularly in credit default prediction and fraud detection, accurate identification of high-risk class instances is paramount, as their occurrence can have significant economic implications. Although machine learning models have gained widespread adoption for risk prediction, their performance is often hindered by the scarcity and diversity of high-quality data. This limitation stems from factors in datasets such as small risk sample sizes, high labeling costs, and severe class imbalance, which impede the models' ability to learn effectively and accurately forecast critical events. This study investigates data pre-processing techniques to enhance existing financial risk datasets by introducing TriEnhance, a straightforward technique that entails: (1) generating synthetic samples specifically tailored to the minority class, (2) filtering using binary feedback to refine samples, and (3) self-learning with pseudo-labels. Our experiments across six benchmark datasets reveal the efficacy of TriEnhance, with a notable focus on improving minority class calibration, a key factor for developing more robust financial risk prediction systems.
Self Adaptive Threshold Pseudo-labeling and Unreliable Sample Contrastive Loss for Semi-supervised Image Classification
Jul 04, 2024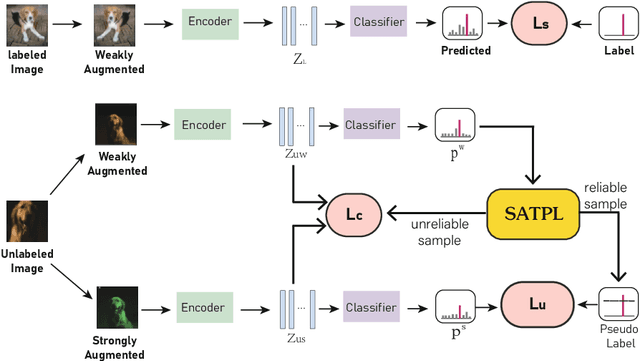



Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. However, pseudo-labeling-based semi-supervised approaches suffer from two problems in image classification: (1) Existing methods might fail to adopt suitable thresholds since they either use a pre-defined/fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. (2) Discarding unlabeled data with confidence below the thresholds results in the loss of discriminating information. To solve these issues, we develop an effective method to make sufficient use of unlabeled data. Specifically, we design a self adaptive threshold pseudo-labeling strategy, which thresholds for each class can be dynamically adjusted to increase the number of reliable samples. Meanwhile, in order to effectively utilise unlabeled data with confidence below the thresholds, we propose an unreliable sample contrastive loss to mine the discriminative information in low-confidence samples by learning the similarities and differences between sample features. We evaluate our method on several classification benchmarks under partially labeled settings and demonstrate its superiority over the other approaches.
Multiscale lubrication simulation based on fourier feature networks with trainable frequency
May 21, 2024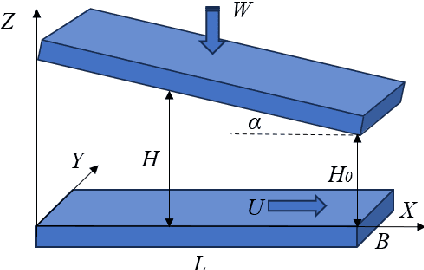



Rough surface lubrication simulation is crucial for designing and optimizing tribological performance. Despite the growing application of Physical Information Neural Networks (PINNs) in hydrodynamic lubrication analysis, their use has been primarily limited to smooth surfaces. This is due to traditional PINN methods suffer from spectral bias, favoring to learn low-frequency features and thus failing to analyze rough surfaces with high-frequency signals. To date, no PINN methods have been reported for rough surface lubrication. To overcome these limitations, this work introduces a novel multi-scale lubrication neural network architecture that utilizes a trainable Fourier feature network. By incorporating learnable feature embedding frequencies, this architecture automatically adapts to various frequency components, thereby enhancing the analysis of rough surface characteristics. This method has been tested across multiple surface morphologies, and the results have been compared with those obtained using the finite element method (FEM). The comparative analysis demonstrates that this approach achieves a high consistency with FEM results. Furthermore, this novel architecture surpasses traditional Fourier feature networks with fixed feature embedding frequencies in both accuracy and computational efficiency. Consequently, the multi-scale lubrication neural network model offers a more efficient tool for rough surface lubrication analysis.
AMSNet: Netlist Dataset for AMS Circuits
May 15, 2024



Today's analog/mixed-signal (AMS) integrated circuit (IC) designs demand substantial manual intervention. The advent of multimodal large language models (MLLMs) has unveiled significant potential across various fields, suggesting their applicability in streamlining large-scale AMS IC design as well. A bottleneck in employing MLLMs for automatic AMS circuit generation is the absence of a comprehensive dataset delineating the schematic-netlist relationship. We therefore design an automatic technique for converting schematics into netlists, and create dataset AMSNet, encompassing transistor-level schematics and corresponding SPICE format netlists. With a growing size, AMSNet can significantly facilitate exploration of MLLM applications in AMS circuit design. We have made an initial set of netlists public, and will make both our netlist generation tool and the full dataset available upon publishing of this paper.
The Treasure Beneath Multiple Annotations: An Uncertainty-aware Edge Detector
Mar 21, 2023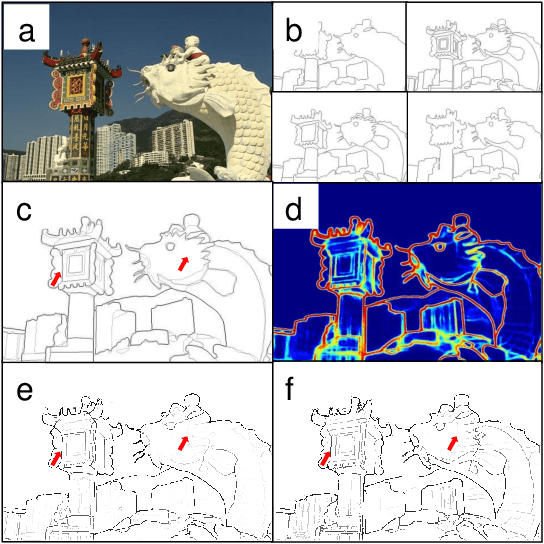
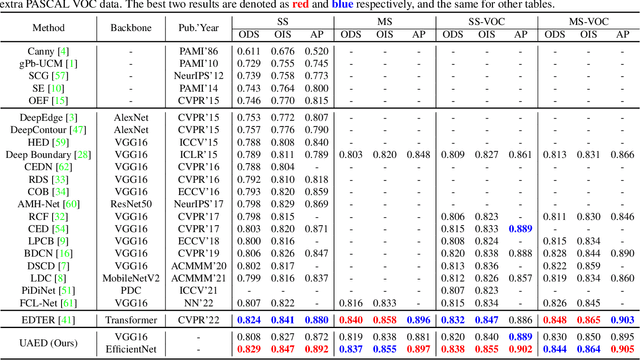
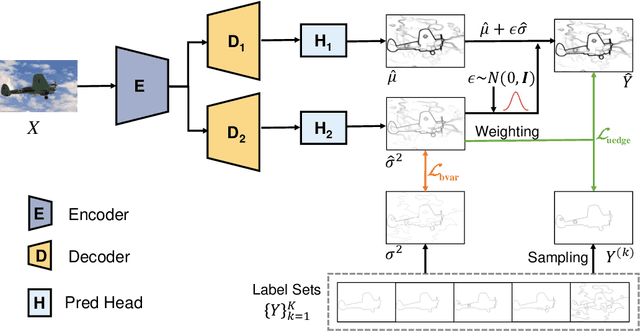
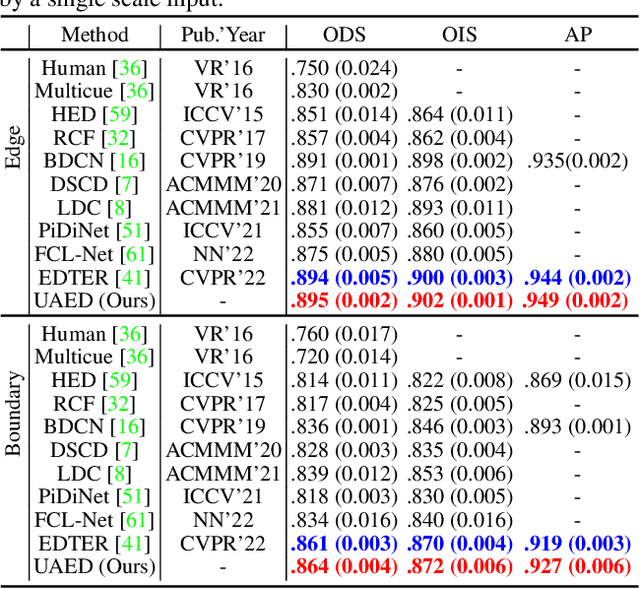
Deep learning-based edge detectors heavily rely on pixel-wise labels which are often provided by multiple annotators. Existing methods fuse multiple annotations using a simple voting process, ignoring the inherent ambiguity of edges and labeling bias of annotators. In this paper, we propose a novel uncertainty-aware edge detector (UAED), which employs uncertainty to investigate the subjectivity and ambiguity of diverse annotations. Specifically, we first convert the deterministic label space into a learnable Gaussian distribution, whose variance measures the degree of ambiguity among different annotations. Then we regard the learned variance as the estimated uncertainty of the predicted edge maps, and pixels with higher uncertainty are likely to be hard samples for edge detection. Therefore we design an adaptive weighting loss to emphasize the learning from those pixels with high uncertainty, which helps the network to gradually concentrate on the important pixels. UAED can be combined with various encoder-decoder backbones, and the extensive experiments demonstrate that UAED achieves superior performance consistently across multiple edge detection benchmarks. The source code is available at \url{https://github.com/ZhouCX117/UAED}
Incorporating Interactive Facts for Stock Selection via Neural Recursive ODEs
Oct 28, 2022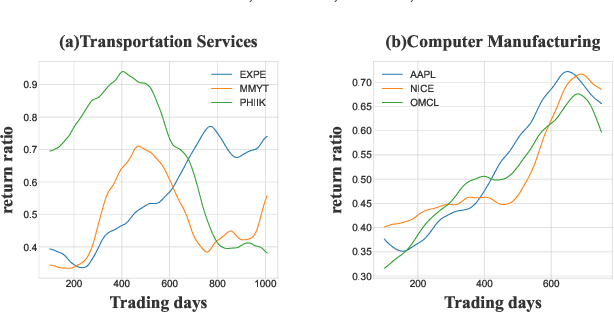

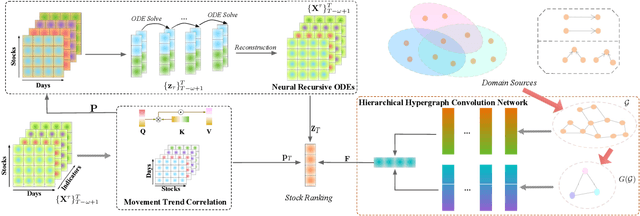

Stock selection attempts to rank a list of stocks for optimizing investment decision making, aiming at minimizing investment risks while maximizing profit returns. Recently, researchers have developed various (recurrent) neural network-based methods to tackle this problem. Without exceptions, they primarily leverage historical market volatility to enhance the selection performance. However, these approaches greatly rely on discrete sampled market observations, which either fail to consider the uncertainty of stock fluctuations or predict continuous stock dynamics in the future. Besides, some studies have considered the explicit stock interdependence derived from multiple domains (e.g., industry and shareholder). Nevertheless, the implicit cross-dependencies among different domains are under-explored. To address such limitations, we present a novel stock selection solution -- StockODE, a latent variable model with Gaussian prior. Specifically, we devise a Movement Trend Correlation module to expose the time-varying relationships regarding stock movements. We design Neural Recursive Ordinary Differential Equation Networks (NRODEs) to capture the temporal evolution of stock volatility in a continuous dynamic manner. Moreover, we build a hierarchical hypergraph to incorporate the domain-aware dependencies among the stocks. Experiments conducted on two real-world stock market datasets demonstrate that StockODE significantly outperforms several baselines, such as up to 18.57% average improvement regarding Sharpe Ratio.