 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrecision Synthesis of Multi-Tracer PET via VLM-Modulated Rectified Flow for Stratifying Mild Cognitive Impairment
Apr 13, 2026The biological definition of Alzheimer's disease (AD) relies on multi-modal neuroimaging, yet the clinical utility of positron emission tomography (PET) is limited by cost and radiation exposure, hindering early screening at preclinical or prodromal stages. While generative models offer a promising alternative by synthesizing PET from magnetic resonance imaging (MRI), achieving subject-specific precision remains a primary challenge. Here, we introduce DIReCT$++$, a Domain-Informed ReCTified flow model for synthesizing multi-tracer PET from MRI combined with fundamental clinical information. Our approach integrates a 3D rectified flow architecture to capture complex cross-modal and cross-tracer relationships with a domain-adapted vision-language model (BiomedCLIP) that provides text-guided, personalized generation using clinical scores and imaging knowledge. Extensive evaluations on multi-center datasets demonstrate that DIReCT$++$ not only produces synthetic PET images ($^{18}$F-AV-45 and $^{18}$F-FDG) of superior fidelity and generalizability but also accurately recapitulates disease-specific patterns. Crucially, combining these synthesized PET images with MRI enables precise personalized stratification of mild cognitive impairment (MCI), advancing a scalable, data-efficient tool for the early diagnosis and prognostic prediction of AD. The source code will be released on https://github.com/ladderlab-xjtu/DIReCT-PLUS.
Vision-Language Model-Guided Deep Unrolling Enables Personalized, Fast MRI
Apr 08, 2026Magnetic Resonance Imaging (MRI) is a cornerstone in medicine and healthcare but suffers from long acquisition times. Traditional accelerated MRI methods optimize for generic image quality, lacking adaptability for specific clinical tasks. To address this, we introduce PASS (Personalized, Anomaly-aware Sampling and reconStruction), an intelligent MRI framework that leverages a Vision-Language Model (VLM) to guide a deep unrolling network for task-oriented, fast imaging. PASS dynamically personalizes the imaging pipeline through three core contributions: (1) a deep unrolled reconstruction network derived from a physics-based MRI model; (2) a sampling module that generates patient-specific $k$-space trajectories; and (3) an anomaly-aware prior, extracted from a pretrained VLM, which steers both sampling and reconstruction toward clinically relevant regions. By integrating the high-level clinical reasoning of a VLM with an interpretable, physics-aware network, PASS achieves superior image quality across diverse anatomies, contrasts, anomalies, and acceleration factors. This enhancement directly translates to improvements in downstream diagnostic tasks, including fine-grained anomaly detection, localization, and diagnosis.
DuMeta++: Spatiotemporal Dual Meta-Learning for Generalizable Few-Shot Brain Tissue Segmentation Across Diverse Ages
Feb 06, 2026Accurate segmentation of brain tissues from MRI scans is critical for neuroscience and clinical applications, but achieving consistent performance across the human lifespan remains challenging due to dynamic, age-related changes in brain appearance and morphology. While prior work has sought to mitigate these shifts by using self-supervised regularization with paired longitudinal data, such data are often unavailable in practice. To address this, we propose \emph{DuMeta++}, a dual meta-learning framework that operates without paired longitudinal data. Our approach integrates: (1) meta-feature learning to extract age-agnostic semantic representations of spatiotemporally evolving brain structures, and (2) meta-initialization learning to enable data-efficient adaptation of the segmentation model. Furthermore, we propose a memory-bank-based class-aware regularization strategy to enforce longitudinal consistency without explicit longitudinal supervision. We theoretically prove the convergence of our DuMeta++, ensuring stability. Experiments on diverse datasets (iSeg-2019, IBIS, OASIS, ADNI) under few-shot settings demonstrate that DuMeta++ outperforms existing methods in cross-age generalization. Code will be available at https://github.com/ladderlab-xjtu/DuMeta++.
UniSino: Physics-Driven Foundational Model for Universal CT Sinogram Standardization
Aug 25, 2025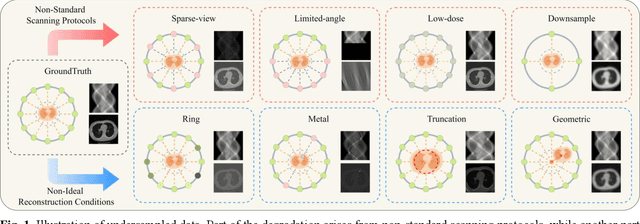
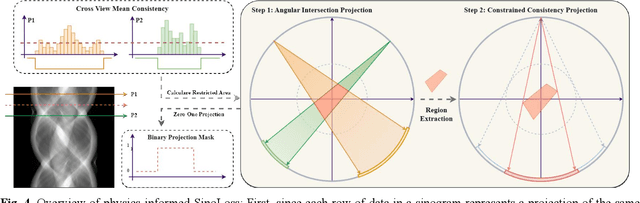
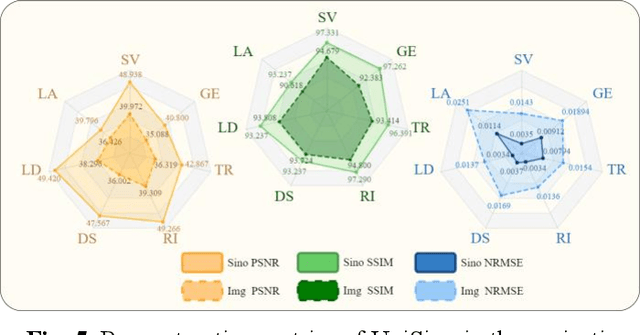
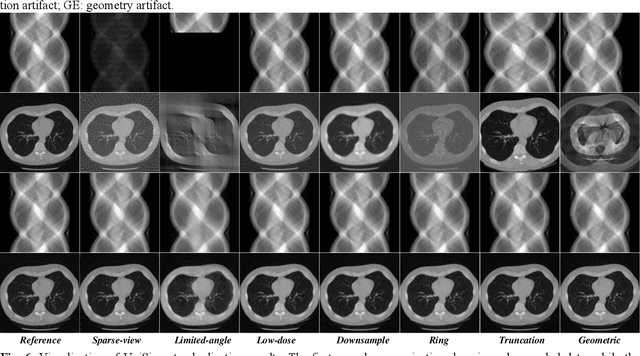
During raw-data acquisition in CT imaging, diverse factors can degrade the collected sinograms, with undersampling and noise leading to severe artifacts and noise in reconstructed images and compromising diagnostic accuracy. Conventional correction methods rely on manually designed algorithms or fixed empirical parameters, but these approaches often lack generalizability across heterogeneous artifact types. To address these limitations, we propose UniSino, a foundation model for universal CT sinogram standardization. Unlike existing foundational models that operate in image domain, UniSino directly standardizes data in the projection domain, which enables stronger generalization across diverse undersampling scenarios. Its training framework incorporates the physical characteristics of sinograms, enhancing generalization and enabling robust performance across multiple subtasks spanning four benchmark datasets. Experimental results demonstrate thatUniSino achieves superior reconstruction quality both single and mixed undersampling case, demonstrating exceptional robustness and generalization in sinogram enhancement for CT imaging. The code is available at: https://github.com/yqx7150/UniSino.
FEAT: A Multi-Agent Forensic AI System with Domain-Adapted Large Language Model for Automated Cause-of-Death Analysis
Aug 11, 2025Forensic cause-of-death determination faces systemic challenges, including workforce shortages and diagnostic variability, particularly in high-volume systems like China's medicolegal infrastructure. We introduce FEAT (ForEnsic AgenT), a multi-agent AI framework that automates and standardizes death investigations through a domain-adapted large language model. FEAT's application-oriented architecture integrates: (i) a central Planner for task decomposition, (ii) specialized Local Solvers for evidence analysis, (iii) a Memory & Reflection module for iterative refinement, and (iv) a Global Solver for conclusion synthesis. The system employs tool-augmented reasoning, hierarchical retrieval-augmented generation, forensic-tuned LLMs, and human-in-the-loop feedback to ensure legal and medical validity. In evaluations across diverse Chinese case cohorts, FEAT outperformed state-of-the-art AI systems in both long-form autopsy analyses and concise cause-of-death conclusions. It demonstrated robust generalization across six geographic regions and achieved high expert concordance in blinded validations. Senior pathologists validated FEAT's outputs as comparable to those of human experts, with improved detection of subtle evidentiary nuances. To our knowledge, FEAT is the first LLM-based AI agent system dedicated to forensic medicine, offering scalable, consistent death certification while maintaining expert-level rigor. By integrating AI efficiency with human oversight, this work could advance equitable access to reliable medicolegal services while addressing critical capacity constraints in forensic systems.
Continuous Filtered Backprojection by Learnable Interpolation Network
May 03, 2025Accurate reconstruction of computed tomography (CT) images is crucial in medical imaging field. However, there are unavoidable interpolation errors in the backprojection step of the conventional reconstruction methods, i.e., filtered-back-projection based methods, which are detrimental to the accurate reconstruction. In this study, to address this issue, we propose a novel deep learning model, named Leanable-Interpolation-based FBP or LInFBP shortly, to enhance the reconstructed CT image quality, which achieves learnable interpolation in the backprojection step of filtered backprojection (FBP) and alleviates the interpolation errors. Specifically, in the proposed LInFBP, we formulate every local piece of the latent continuous function of discrete sinogram data as a linear combination of selected basis functions, and learn this continuous function by exploiting a deep network to predict the linear combination coefficients. Then, the learned latent continuous function is exploited for interpolation in backprojection step, which first time takes the advantage of deep learning for the interpolation in FBP. Extensive experiments, which encompass diverse CT scenarios, demonstrate the effectiveness of the proposed LInFBP in terms of enhanced reconstructed image quality, plug-and-play ability and generalization capability.
SS-CTML: Self-Supervised Cross-Task Mutual Learning for CT Image Reconstruction
Dec 31, 2024



Supervised deep-learning (SDL) techniques with paired training datasets have been widely studied for X-ray computed tomography (CT) image reconstruction. However, due to the difficulties of obtaining paired training datasets in clinical routine, the SDL methods are still away from common uses in clinical practices. In recent years, self-supervised deep-learning (SSDL) techniques have shown great potential for the studies of CT image reconstruction. In this work, we propose a self-supervised cross-task mutual learning (SS-CTML) framework for CT image reconstruction. Specifically, a sparse-view scanned and a limited-view scanned sinogram data are first extracted from a full-view scanned sinogram data, which results in three individual reconstruction tasks, i.e., the full-view CT (FVCT) reconstruction, the sparse-view CT (SVCT) reconstruction, and limited-view CT (LVCT) reconstruction. Then, three neural networks are constructed for the three reconstruction tasks. Considering that the ultimate goals of the three tasks are all to reconstruct high-quality CT images, we therefore construct a set of cross-task mutual learning objectives for the three tasks, in which way, the three neural networks can be self-supervised optimized by learning from each other. Clinical datasets are adopted to evaluate the effectiveness of the proposed framework. Experimental results demonstrate that the SS-CTML framework can obtain promising CT image reconstruction performance in terms of both quantitative and qualitative measurements.
Large-vocabulary forensic pathological analyses via prototypical cross-modal contrastive learning
Jul 20, 2024Forensic pathology is critical in determining the cause and manner of death through post-mortem examinations, both macroscopic and microscopic. The field, however, grapples with issues such as outcome variability, laborious processes, and a scarcity of trained professionals. This paper presents SongCi, an innovative visual-language model (VLM) designed specifically for forensic pathology. SongCi utilizes advanced prototypical cross-modal self-supervised contrastive learning to enhance the accuracy, efficiency, and generalizability of forensic analyses. It was pre-trained and evaluated on a comprehensive multi-center dataset, which includes over 16 million high-resolution image patches, 2,228 vision-language pairs of post-mortem whole slide images (WSIs), and corresponding gross key findings, along with 471 distinct diagnostic outcomes. Our findings indicate that SongCi surpasses existing multi-modal AI models in many forensic pathology tasks, performs comparably to experienced forensic pathologists and significantly better than less experienced ones, and provides detailed multi-modal explainability, offering critical assistance in forensic investigations. To the best of our knowledge, SongCi is the first VLM specifically developed for forensic pathological analysis and the first large-vocabulary computational pathology (CPath) model that directly processes gigapixel WSIs in forensic science.
DA-TransUNet: Integrating Spatial and Channel Dual Attention with Transformer U-Net for Medical Image Segmentation
Oct 19, 2023Great progress has been made in automatic medical image segmentation due to powerful deep representation learning. The influence of transformer has led to research into its variants, and large-scale replacement of traditional CNN modules. However, such trend often overlooks the intrinsic feature extraction capabilities of the transformer and potential refinements to both the model and the transformer module through minor adjustments. This study proposes a novel deep medical image segmentation framework, called DA-TransUNet, aiming to introduce the Transformer and dual attention block into the encoder and decoder of the traditional U-shaped architecture. Unlike prior transformer-based solutions, our DA-TransUNet utilizes attention mechanism of transformer and multifaceted feature extraction of DA-Block, which can efficiently combine global, local, and multi-scale features to enhance medical image segmentation. Meanwhile, experimental results show that a dual attention block is added before the Transformer layer to facilitate feature extraction in the U-net structure. Furthermore, incorporating dual attention blocks in skip connections can enhance feature transfer to the decoder, thereby improving image segmentation performance. Experimental results across various benchmark of medical image segmentation reveal that DA-TransUNet significantly outperforms the state-of-the-art methods. The codes and parameters of our model will be publicly available at https://github.com/SUN-1024/DA-TransUnet.
A Peer-to-peer Federated Continual Learning Network for Improving CT Imaging from Multiple Institutions
Jun 03, 2023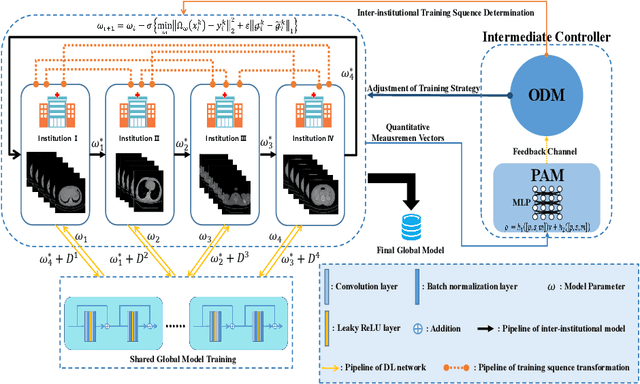

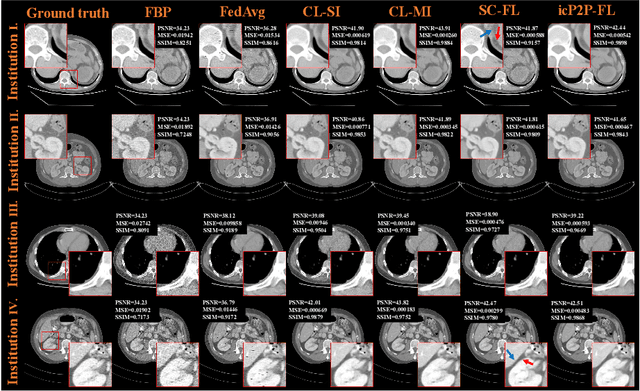
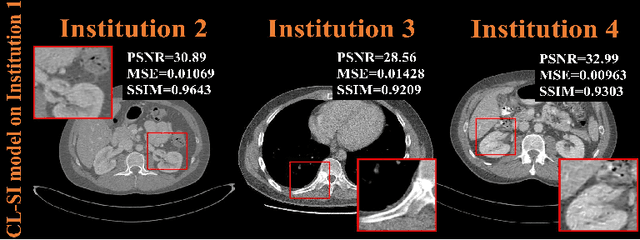
Deep learning techniques have been widely used in computed tomography (CT) but require large data sets to train networks. Moreover, data sharing among multiple institutions is limited due to data privacy constraints, which hinders the development of high-performance DL-based CT imaging models from multi-institutional collaborations. Federated learning (FL) strategy is an alternative way to train the models without centralizing data from multi-institutions. In this work, we propose a novel peer-to-peer federated continual learning strategy to improve low-dose CT imaging performance from multiple institutions. The newly proposed method is called peer-to-peer continual FL with intermediate controllers, i.e., icP2P-FL. Specifically, different from the conventional FL model, the proposed icP2P-FL does not require a central server that coordinates training information for a global model. In the proposed icP2P-FL method, the peer-to-peer federated continual learning is introduced wherein the DL-based model is continually trained one client after another via model transferring and inter institutional parameter sharing due to the common characteristics of CT data among the clients. Furthermore, an intermediate controller is developed to make the overall training more flexible. Numerous experiments were conducted on the AAPM low-dose CT Grand Challenge dataset and local datasets, and the experimental results showed that the proposed icP2P-FL method outperforms the other comparative methods both qualitatively and quantitatively, and reaches an accuracy similar to a model trained with pooling data from all the institutions.