 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Contrastive Pre-trained Foundation Model for Deciphering Imaging Noisomics across Modalities
Jan 21, 2026Characterizing imaging noise is notoriously data-intensive and device-dependent, as modern sensors entangle physical signals with complex algorithmic artifacts. Current paradigms struggle to disentangle these factors without massive supervised datasets, often reducing noise to mere interference rather than an information resource. Here, we introduce "Noisomics", a framework shifting the focus from suppression to systematic noise decoding via the Contrastive Pre-trained (CoP) Foundation Model. By leveraging the manifold hypothesis and synthetic noise genome, CoP employs contrastive learning to disentangle semantic signals from stochastic perturbations. Crucially, CoP breaks traditional deep learning scaling laws, achieving superior performance with only 100 training samples, outperforming supervised baselines trained on 100,000 samples, thereby reducing data and computational dependency by three orders of magnitude. Extensive benchmarking across 12 diverse out-of-domain datasets confirms its robust zero-shot generalization, demonstrating a 63.8% reduction in estimation error and an 85.1% improvement in the coefficient of determination compared to the conventional training strategy. We demonstrate CoP's utility across scales: from deciphering non-linear hardware-noise interplay in consumer photography to optimizing photon-efficient protocols for deep-tissue microscopy. By decoding noise as a multi-parametric footprint, our work redefines stochastic degradation as a vital information resource, empowering precise imaging diagnostics without prior device calibration.
MedGround: Bridging the Evidence Gap in Medical Vision-Language Models with Verified Grounding Data
Jan 11, 2026Vision-Language Models (VLMs) can generate convincing clinical narratives, yet frequently struggle to visually ground their statements. We posit this limitation arises from the scarcity of high-quality, large-scale clinical referring-localization pairs. To address this, we introduce MedGround, an automated pipeline that transforms segmentation resources into high-quality medical referring grounding data. Leveraging expert masks as spatial anchors, MedGround precisely derives localization targets, extracts shape and spatial cues, and guides VLMs to synthesize natural, clinically grounded queries that reflect morphology and location. To ensure data rigor, a multi-stage verification system integrates strict formatting checks, geometry- and medical-prior rules, and image-based visual judging to filter out ambiguous or visually unsupported samples. Finally, we present MedGround-35K, a novel multimodal medical dataset. Extensive experiments demonstrate that VLMs trained with MedGround-35K consistently achieve improved referring grounding performance, enhance multi-object semantic disambiguation, and exhibit strong generalization to unseen grounding settings. This work highlights MedGround as a scalable, data-driven approach to anchor medical language to verifiable visual evidence. Dataset and code will be released publicly upon acceptance.
Few-Step Distillation for Text-to-Image Generation: A Practical Guide
Dec 15, 2025Diffusion distillation has dramatically accelerated class-conditional image synthesis, but its applicability to open-ended text-to-image (T2I) generation is still unclear. We present the first systematic study that adapts and compares state-of-the-art distillation techniques on a strong T2I teacher model, FLUX.1-lite. By casting existing methods into a unified framework, we identify the key obstacles that arise when moving from discrete class labels to free-form language prompts. Beyond a thorough methodological analysis, we offer practical guidelines on input scaling, network architecture, and hyperparameters, accompanied by an open-source implementation and pretrained student models. Our findings establish a solid foundation for deploying fast, high-fidelity, and resource-efficient diffusion generators in real-world T2I applications. Code is available on github.com/alibaba-damo-academy/T2I-Distill.
DGS-Net: Distillation-Guided Gradient Surgery for CLIP Fine-Tuning in AI-Generated Image Detection
Nov 17, 2025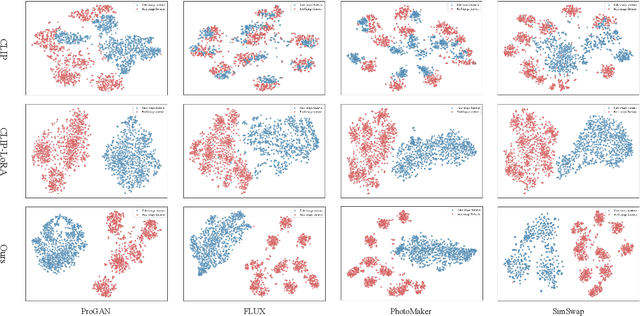
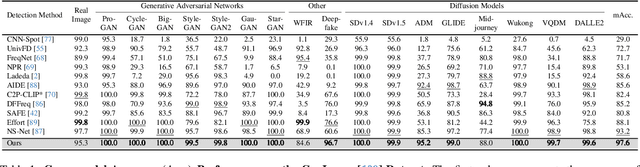
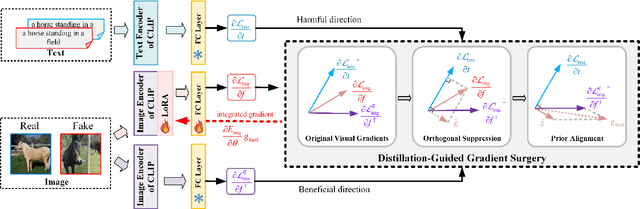
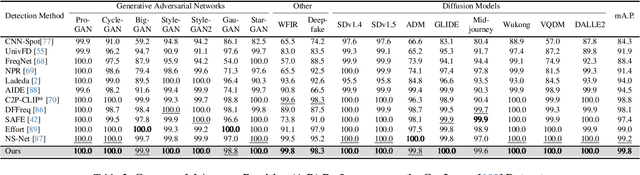
The rapid progress of generative models such as GANs and diffusion models has led to the widespread proliferation of AI-generated images, raising concerns about misinformation, privacy violations, and trust erosion in digital media. Although large-scale multimodal models like CLIP offer strong transferable representations for detecting synthetic content, fine-tuning them often induces catastrophic forgetting, which degrades pre-trained priors and limits cross-domain generalization. To address this issue, we propose the Distillation-guided Gradient Surgery Network (DGS-Net), a novel framework that preserves transferable pre-trained priors while suppressing task-irrelevant components. Specifically, we introduce a gradient-space decomposition that separates harmful and beneficial descent directions during optimization. By projecting task gradients onto the orthogonal complement of harmful directions and aligning with beneficial ones distilled from a frozen CLIP encoder, DGS-Net achieves unified optimization of prior preservation and irrelevant suppression. Extensive experiments on 50 generative models demonstrate that our method outperforms state-of-the-art approaches by an average margin of 6.6, achieving superior detection performance and generalization across diverse generation techniques.
Overview of CHIP 2025 Shared Task 2: Discharge Medication Recommendation for Metabolic Diseases Based on Chinese Electronic Health Records
Nov 09, 2025Discharge medication recommendation plays a critical role in ensuring treatment continuity, preventing readmission, and improving long-term management for patients with chronic metabolic diseases. This paper present an overview of the CHIP 2025 Shared Task 2 competition, which aimed to develop state-of-the-art approaches for automatically recommending appro-priate discharge medications using real-world Chinese EHR data. For this task, we constructed CDrugRed, a high-quality dataset consisting of 5,894 de-identified hospitalization records from 3,190 patients in China. This task is challenging due to multi-label nature of medication recommendation, het-erogeneous clinical text, and patient-specific variability in treatment plans. A total of 526 teams registered, with 167 and 95 teams submitting valid results to the Phase A and Phase B leaderboards, respectively. The top-performing team achieved the highest overall performance on the final test set, with a Jaccard score of 0.5102, F1 score of 0.6267, demonstrating the potential of advanced large language model (LLM)-based ensemble systems. These re-sults highlight both the promise and remaining challenges of applying LLMs to medication recommendation in Chinese EHRs. The post-evaluation phase remains open at https://tianchi.aliyun.com/competition/entrance/532411/.
The best performance in the CARE 2025 -- Liver Task (LiSeg-Contrast): Contrast-Aware Semi-Supervised Segmentation with Domain Generalization and Test-Time Adaptation
Oct 05, 2025



Accurate liver segmentation from contrast-enhanced MRI is essential for diagnosis, treatment planning, and disease monitoring. However, it remains challenging due to limited annotated data, heterogeneous enhancement protocols, and significant domain shifts across scanners and institutions. Traditional image-to-image translation frameworks have made great progress in domain generalization, but their application is not straightforward. For example, Pix2Pix requires image registration, and cycle-GAN cannot be integrated seamlessly into segmentation pipelines. Meanwhile, these methods are originally used to deal with cross-modality scenarios, and often introduce structural distortions and suffer from unstable training, which may pose drawbacks in our single-modality scenario. To address these challenges, we propose CoSSeg-TTA, a compact segmentation framework for the GED4 (Gd-EOB-DTPA enhanced hepatobiliary phase MRI) modality built upon nnU-Netv2 and enhanced with a semi-supervised mean teacher scheme to exploit large amounts of unlabeled volumes. A domain adaptation module, incorporating a randomized histogram-based style appearance transfer function and a trainable contrast-aware network, enriches domain diversity and mitigates cross-center variability. Furthermore, a continual test-time adaptation strategy is employed to improve robustness during inference. Extensive experiments demonstrate that our framework consistently outperforms the nnU-Netv2 baseline, achieving superior Dice score and Hausdorff Distance while exhibiting strong generalization to unseen domains under low-annotation conditions.
RAPID^3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformer
Sep 26, 2025Diffusion Transformers (DiTs) excel at visual generation yet remain hampered by slow sampling. Existing training-free accelerators - step reduction, feature caching, and sparse attention - enhance inference speed but typically rely on a uniform heuristic or a manually designed adaptive strategy for all images, leaving quality on the table. Alternatively, dynamic neural networks offer per-image adaptive acceleration, but their high fine-tuning costs limit broader applicability. To address these limitations, we introduce RAPID3: Tri-Level Reinforced Acceleration Policies for Diffusion Transformers, a framework that delivers image-wise acceleration with zero updates to the base generator. Specifically, three lightweight policy heads - Step-Skip, Cache-Reuse, and Sparse-Attention - observe the current denoising state and independently decide their corresponding speed-up at each timestep. All policy parameters are trained online via Group Relative Policy Optimization (GRPO) while the generator remains frozen. Meanwhile, an adversarially learned discriminator augments the reward signal, discouraging reward hacking by boosting returns only when generated samples stay close to the original model's distribution. Across state-of-the-art DiT backbones, including Stable Diffusion 3 and FLUX, RAPID3 achieves nearly 3x faster sampling with competitive generation quality.
Context and Diversity Matter: The Emergence of In-Context Learning in World Models
Sep 26, 2025The capability of predicting environmental dynamics underpins both biological neural systems and general embodied AI in adapting to their surroundings. Yet prevailing approaches rest on static world models that falter when confronted with novel or rare configurations. We investigate in-context environment learning (ICEL), shifting attention from zero-shot performance to the growth and asymptotic limits of the world model. Our contributions are three-fold: (1) we formalize in-context learning of a world model and identify two core mechanisms: environment recognition and environment learning; (2) we derive error upper-bounds for both mechanisms that expose how the mechanisms emerge; and (3) we empirically confirm that distinct ICL mechanisms exist in the world model, and we further investigate how data distribution and model architecture affect ICL in a manner consistent with theory. These findings demonstrate the potential of self-adapting world models and highlight the key factors behind the emergence of ICEL, most notably the necessity of long context and diverse environments.
RynnVLA-001: Using Human Demonstrations to Improve Robot Manipulation
Sep 18, 2025This paper presents RynnVLA-001, a vision-language-action(VLA) model built upon large-scale video generative pretraining from human demonstrations. We propose a novel two-stage pretraining methodology. The first stage, Ego-Centric Video Generative Pretraining, trains an Image-to-Video model on 12M ego-centric manipulation videos to predict future frames conditioned on an initial frame and a language instruction. The second stage, Human-Centric Trajectory-Aware Modeling, extends this by jointly predicting future keypoint trajectories, thereby effectively bridging visual frame prediction with action prediction. Furthermore, to enhance action representation, we propose ActionVAE, a variational autoencoder that compresses sequences of actions into compact latent embeddings, reducing the complexity of the VLA output space. When finetuned on the same downstream robotics datasets, RynnVLA-001 achieves superior performance over state-of-the-art baselines, demonstrating that the proposed pretraining strategy provides a more effective initialization for VLA models.
JCo-MVTON: Jointly Controllable Multi-Modal Diffusion Transformer for Mask-Free Virtual Try-on
Aug 25, 2025
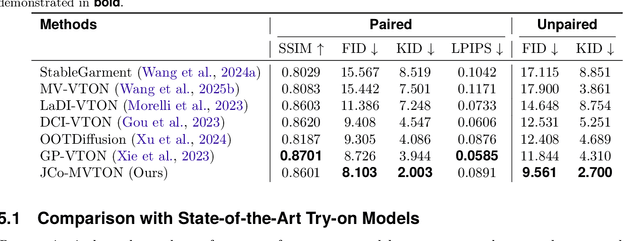
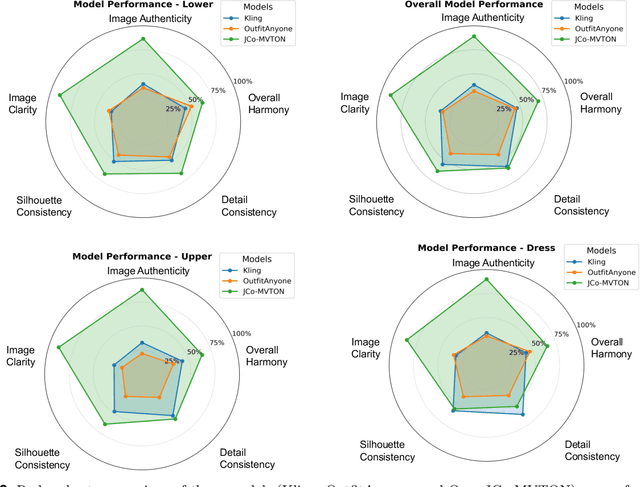
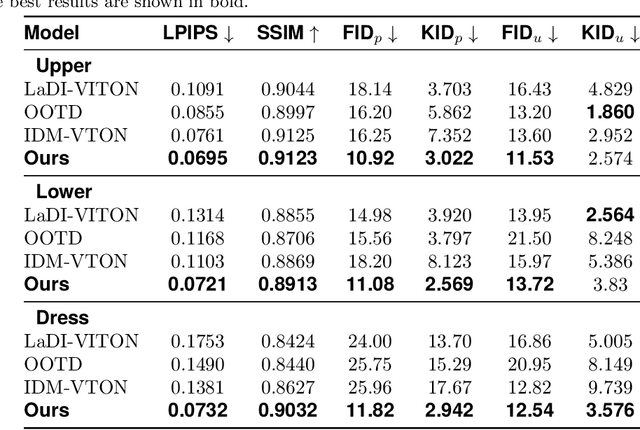
Virtual try-on systems have long been hindered by heavy reliance on human body masks, limited fine-grained control over garment attributes, and poor generalization to real-world, in-the-wild scenarios. In this paper, we propose JCo-MVTON (Jointly Controllable Multi-Modal Diffusion Transformer for Mask-Free Virtual Try-On), a novel framework that overcomes these limitations by integrating diffusion-based image generation with multi-modal conditional fusion. Built upon a Multi-Modal Diffusion Transformer (MM-DiT) backbone, our approach directly incorporates diverse control signals -- such as the reference person image and the target garment image -- into the denoising process through dedicated conditional pathways that fuse features within the self-attention layers. This fusion is further enhanced with refined positional encodings and attention masks, enabling precise spatial alignment and improved garment-person integration. To address data scarcity and quality, we introduce a bidirectional generation strategy for dataset construction: one pipeline uses a mask-based model to generate realistic reference images, while a symmetric ``Try-Off'' model, trained in a self-supervised manner, recovers the corresponding garment images. The synthesized dataset undergoes rigorous manual curation, allowing iterative improvement in visual fidelity and diversity. Experiments demonstrate that JCo-MVTON achieves state-of-the-art performance on public benchmarks including DressCode, significantly outperforming existing methods in both quantitative metrics and human evaluations. Moreover, it shows strong generalization in real-world applications, surpassing commercial systems.