 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVascular anatomy-aware self-supervised pre-training for X-ray angiogram analysis
Feb 12, 2026X-ray angiography is the gold standard imaging modality for cardiovascular diseases. However, current deep learning approaches for X-ray angiogram analysis are severely constrained by the scarcity of annotated data. While large-scale self-supervised learning (SSL) has emerged as a promising solution, its potential in this domain remains largely unexplored, primarily due to the lack of effective SSL frameworks and large-scale datasets. To bridge this gap, we introduce a vascular anatomy-aware masked image modeling (VasoMIM) framework that explicitly integrates domain-specific anatomical knowledge. Specifically, VasoMIM comprises two key designs: an anatomy-guided masking strategy and an anatomical consistency loss. The former strategically masks vessel-containing patches to compel the model to learn robust vascular semantics, while the latter preserves structural consistency of vessels between original and reconstructed images, enhancing the discriminability of the learned representations. In conjunction with VasoMIM, we curate XA-170K, the largest X-ray angiogram pre-training dataset to date. We validate VasoMIM on four downstream tasks across six datasets, where it demonstrates superior transferability and achieves state-of-the-art performance compared to existing methods. These findings highlight the significant potential of VasoMIM as a foundation model for advancing a wide range of X-ray angiogram analysis tasks. VasoMIM and XA-170K will be available at https://github.com/Dxhuang-CASIA/XA-SSL.
A Contrastive Pre-trained Foundation Model for Deciphering Imaging Noisomics across Modalities
Jan 21, 2026Characterizing imaging noise is notoriously data-intensive and device-dependent, as modern sensors entangle physical signals with complex algorithmic artifacts. Current paradigms struggle to disentangle these factors without massive supervised datasets, often reducing noise to mere interference rather than an information resource. Here, we introduce "Noisomics", a framework shifting the focus from suppression to systematic noise decoding via the Contrastive Pre-trained (CoP) Foundation Model. By leveraging the manifold hypothesis and synthetic noise genome, CoP employs contrastive learning to disentangle semantic signals from stochastic perturbations. Crucially, CoP breaks traditional deep learning scaling laws, achieving superior performance with only 100 training samples, outperforming supervised baselines trained on 100,000 samples, thereby reducing data and computational dependency by three orders of magnitude. Extensive benchmarking across 12 diverse out-of-domain datasets confirms its robust zero-shot generalization, demonstrating a 63.8% reduction in estimation error and an 85.1% improvement in the coefficient of determination compared to the conventional training strategy. We demonstrate CoP's utility across scales: from deciphering non-linear hardware-noise interplay in consumer photography to optimizing photon-efficient protocols for deep-tissue microscopy. By decoding noise as a multi-parametric footprint, our work redefines stochastic degradation as a vital information resource, empowering precise imaging diagnostics without prior device calibration.
EarthCrafter: Scalable 3D Earth Generation via Dual-Sparse Latent Diffusion
Jul 23, 2025Despite the remarkable developments achieved by recent 3D generation works, scaling these methods to geographic extents, such as modeling thousands of square kilometers of Earth's surface, remains an open challenge. We address this through a dual innovation in data infrastructure and model architecture. First, we introduce Aerial-Earth3D, the largest 3D aerial dataset to date, consisting of 50k curated scenes (each measuring 600m x 600m) captured across the U.S. mainland, comprising 45M multi-view Google Earth frames. Each scene provides pose-annotated multi-view images, depth maps, normals, semantic segmentation, and camera poses, with explicit quality control to ensure terrain diversity. Building on this foundation, we propose EarthCrafter, a tailored framework for large-scale 3D Earth generation via sparse-decoupled latent diffusion. Our architecture separates structural and textural generation: 1) Dual sparse 3D-VAEs compress high-resolution geometric voxels and textural 2D Gaussian Splats (2DGS) into compact latent spaces, largely alleviating the costly computation suffering from vast geographic scales while preserving critical information. 2) We propose condition-aware flow matching models trained on mixed inputs (semantics, images, or neither) to flexibly model latent geometry and texture features independently. Extensive experiments demonstrate that EarthCrafter performs substantially better in extremely large-scale generation. The framework further supports versatile applications, from semantic-guided urban layout generation to unconditional terrain synthesis, while maintaining geographic plausibility through our rich data priors from Aerial-Earth3D. Our project page is available at https://whiteinblue.github.io/earthcrafter/
WorldVLA: Towards Autoregressive Action World Model
Jun 26, 2025We present WorldVLA, an autoregressive action world model that unifies action and image understanding and generation. Our WorldVLA intergrates Vision-Language-Action (VLA) model and world model in one single framework. The world model predicts future images by leveraging both action and image understanding, with the purpose of learning the underlying physics of the environment to improve action generation. Meanwhile, the action model generates the subsequent actions based on image observations, aiding in visual understanding and in turn helps visual generation of the world model. We demonstrate that WorldVLA outperforms standalone action and world models, highlighting the mutual enhancement between the world model and the action model. In addition, we find that the performance of the action model deteriorates when generating sequences of actions in an autoregressive manner. This phenomenon can be attributed to the model's limited generalization capability for action prediction, leading to the propagation of errors from earlier actions to subsequent ones. To address this issue, we propose an attention mask strategy that selectively masks prior actions during the generation of the current action, which shows significant performance improvement in the action chunk generation task.
AnimateAnyMesh: A Feed-Forward 4D Foundation Model for Text-Driven Universal Mesh Animation
Jun 11, 2025
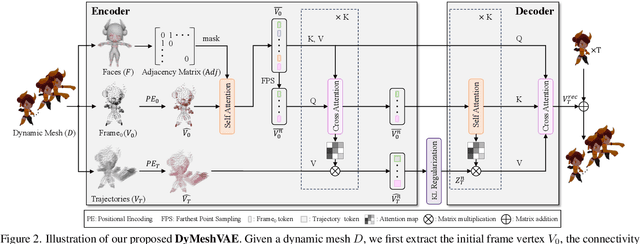
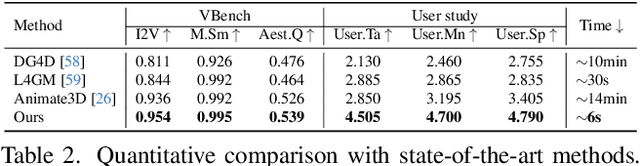
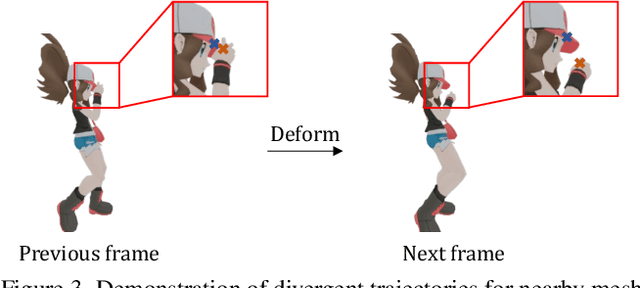
Recent advances in 4D content generation have attracted increasing attention, yet creating high-quality animated 3D models remains challenging due to the complexity of modeling spatio-temporal distributions and the scarcity of 4D training data. In this paper, we present AnimateAnyMesh, the first feed-forward framework that enables efficient text-driven animation of arbitrary 3D meshes. Our approach leverages a novel DyMeshVAE architecture that effectively compresses and reconstructs dynamic mesh sequences by disentangling spatial and temporal features while preserving local topological structures. To enable high-quality text-conditional generation, we employ a Rectified Flow-based training strategy in the compressed latent space. Additionally, we contribute the DyMesh Dataset, containing over 4M diverse dynamic mesh sequences with text annotations. Experimental results demonstrate that our method generates semantically accurate and temporally coherent mesh animations in a few seconds, significantly outperforming existing approaches in both quality and efficiency. Our work marks a substantial step forward in making 4D content creation more accessible and practical. All the data, code, and models will be open-released.
3DV-TON: Textured 3D-Guided Consistent Video Try-on via Diffusion Models
Apr 24, 2025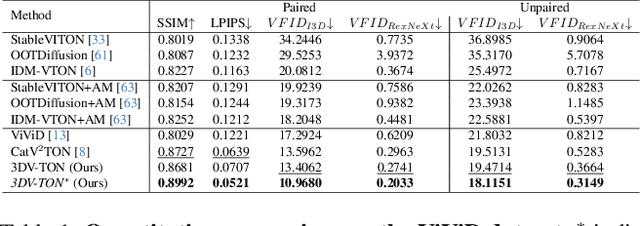


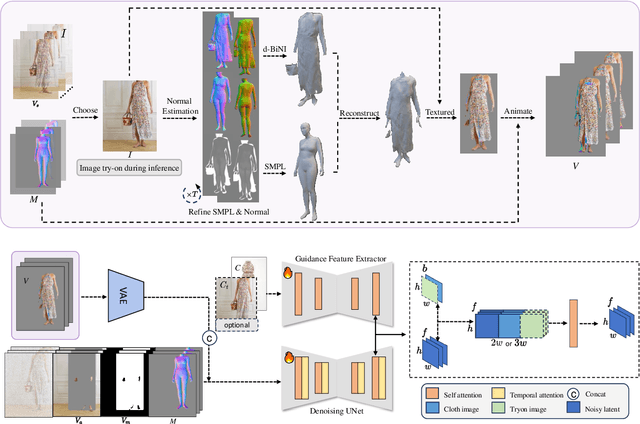
Video try-on replaces clothing in videos with target garments. Existing methods struggle to generate high-quality and temporally consistent results when handling complex clothing patterns and diverse body poses. We present 3DV-TON, a novel diffusion-based framework for generating high-fidelity and temporally consistent video try-on results. Our approach employs generated animatable textured 3D meshes as explicit frame-level guidance, alleviating the issue of models over-focusing on appearance fidelity at the expanse of motion coherence. This is achieved by enabling direct reference to consistent garment texture movements throughout video sequences. The proposed method features an adaptive pipeline for generating dynamic 3D guidance: (1) selecting a keyframe for initial 2D image try-on, followed by (2) reconstructing and animating a textured 3D mesh synchronized with original video poses. We further introduce a robust rectangular masking strategy that successfully mitigates artifact propagation caused by leaking clothing information during dynamic human and garment movements. To advance video try-on research, we introduce HR-VVT, a high-resolution benchmark dataset containing 130 videos with diverse clothing types and scenarios. Quantitative and qualitative results demonstrate our superior performance over existing methods. The project page is at this link https://2y7c3.github.io/3DV-TON/
Uni3C: Unifying Precisely 3D-Enhanced Camera and Human Motion Controls for Video Generation
Apr 21, 2025



Camera and human motion controls have been extensively studied for video generation, but existing approaches typically address them separately, suffering from limited data with high-quality annotations for both aspects. To overcome this, we present Uni3C, a unified 3D-enhanced framework for precise control of both camera and human motion in video generation. Uni3C includes two key contributions. First, we propose a plug-and-play control module trained with a frozen video generative backbone, PCDController, which utilizes unprojected point clouds from monocular depth to achieve accurate camera control. By leveraging the strong 3D priors of point clouds and the powerful capacities of video foundational models, PCDController shows impressive generalization, performing well regardless of whether the inference backbone is frozen or fine-tuned. This flexibility enables different modules of Uni3C to be trained in specific domains, i.e., either camera control or human motion control, reducing the dependency on jointly annotated data. Second, we propose a jointly aligned 3D world guidance for the inference phase that seamlessly integrates both scenic point clouds and SMPL-X characters to unify the control signals for camera and human motion, respectively. Extensive experiments confirm that PCDController enjoys strong robustness in driving camera motion for fine-tuned backbones of video generation. Uni3C substantially outperforms competitors in both camera controllability and human motion quality. Additionally, we collect tailored validation sets featuring challenging camera movements and human actions to validate the effectiveness of our method.
Cyc3D: Fine-grained Controllable 3D Generation via Cycle Consistency Regularization
Apr 21, 2025


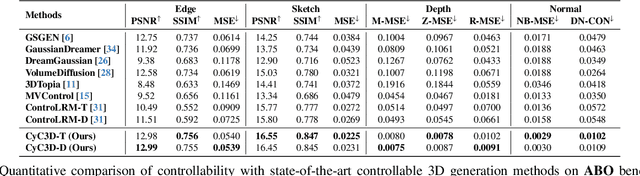
Despite the remarkable progress of 3D generation, achieving controllability, i.e., ensuring consistency between generated 3D content and input conditions like edge and depth, remains a significant challenge. Existing methods often struggle to maintain accurate alignment, leading to noticeable discrepancies. To address this issue, we propose \name{}, a new framework that enhances controllable 3D generation by explicitly encouraging cyclic consistency between the second-order 3D content, generated based on extracted signals from the first-order generation, and its original input controls. Specifically, we employ an efficient feed-forward backbone that can generate a 3D object from an input condition and a text prompt. Given an initial viewpoint and a control signal, a novel view is rendered from the generated 3D content, from which the extracted condition is used to regenerate the 3D content. This re-generated output is then rendered back to the initial viewpoint, followed by another round of control signal extraction, forming a cyclic process with two consistency constraints. \emph{View consistency} ensures coherence between the two generated 3D objects, measured by semantic similarity to accommodate generative diversity. \emph{Condition consistency} aligns the final extracted signal with the original input control, preserving structural or geometric details throughout the process. Extensive experiments on popular benchmarks demonstrate that \name{} significantly improves controllability, especially for fine-grained details, outperforming existing methods across various conditions (e.g., +14.17\% PSNR for edge, +6.26\% PSNR for sketch).
MVGenMaster: Scaling Multi-View Generation from Any Image via 3D Priors Enhanced Diffusion Model
Nov 26, 2024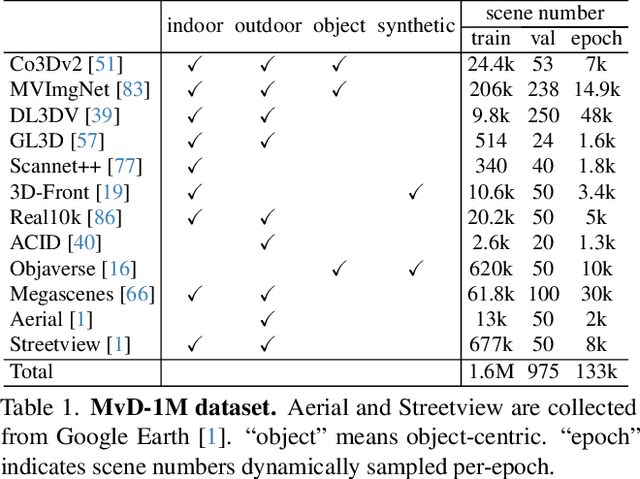
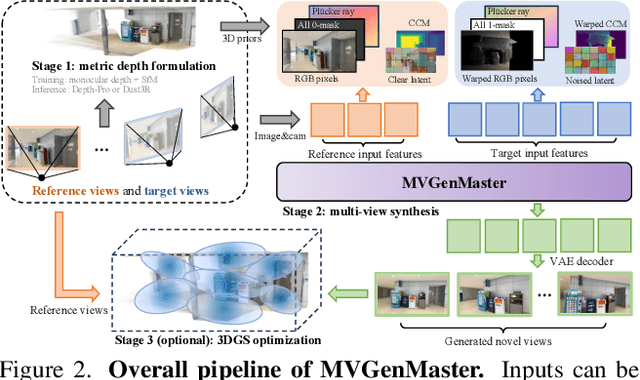
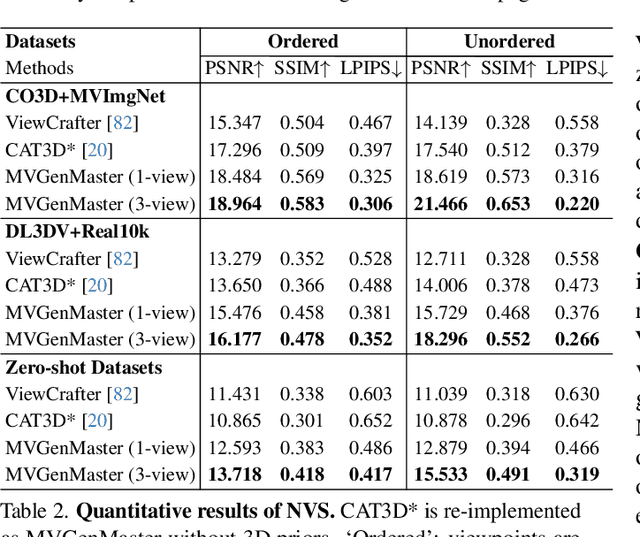
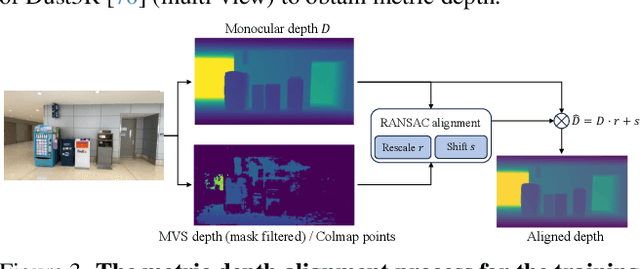
We introduce MVGenMaster, a multi-view diffusion model enhanced with 3D priors to address versatile Novel View Synthesis (NVS) tasks. MVGenMaster leverages 3D priors that are warped using metric depth and camera poses, significantly enhancing both generalization and 3D consistency in NVS. Our model features a simple yet effective pipeline that can generate up to 100 novel views conditioned on variable reference views and camera poses with a single forward process. Additionally, we have developed a comprehensive large-scale multi-view image dataset called MvD-1M, comprising up to 1.6 million scenes, equipped with well-aligned metric depth to train MVGenMaster. Moreover, we present several training and model modifications to strengthen the model with scaled-up datasets. Extensive evaluations across in- and out-of-domain benchmarks demonstrate the effectiveness of our proposed method and data formulation. Models and codes will be released at https://github.com/ewrfcas/MVGenMaster/.
MVInpainter: Learning Multi-View Consistent Inpainting to Bridge 2D and 3D Editing
Aug 15, 2024



Novel View Synthesis (NVS) and 3D generation have recently achieved prominent improvements. However, these works mainly focus on confined categories or synthetic 3D assets, which are discouraged from generalizing to challenging in-the-wild scenes and fail to be employed with 2D synthesis directly. Moreover, these methods heavily depended on camera poses, limiting their real-world applications. To overcome these issues, we propose MVInpainter, re-formulating the 3D editing as a multi-view 2D inpainting task. Specifically, MVInpainter partially inpaints multi-view images with the reference guidance rather than intractably generating an entirely novel view from scratch, which largely simplifies the difficulty of in-the-wild NVS and leverages unmasked clues instead of explicit pose conditions. To ensure cross-view consistency, MVInpainter is enhanced by video priors from motion components and appearance guidance from concatenated reference key&value attention. Furthermore, MVInpainter incorporates slot attention to aggregate high-level optical flow features from unmasked regions to control the camera movement with pose-free training and inference. Sufficient scene-level experiments on both object-centric and forward-facing datasets verify the effectiveness of MVInpainter, including diverse tasks, such as multi-view object removal, synthesis, insertion, and replacement. The project page is https://ewrfcas.github.io/MVInpainter/.