 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshWeaver: Sparse-Voxel-Guided Surface Weaving for Autoregressive Mesh Generation
Jun 03, 2026Autoregressive mesh generation has gained attention by tokenizing meshes into sequences and training models in a language-modeling fashion. However, existing approaches suffer from two fundamental limitations: (i) low tokenization efficiency, which yields long token sequences and prevents scaling to high-poly meshes, and (ii) absence of geometry-aware guidance, as generation is conditioned only on global shape embeddings rather than local surface cues. We introduce MeshWeaver, an autoregressive framework that treats mesh generation as a surface weaving process by directly predicting the next vertex instead of independent coordinates. At its core is a multi-level sparse-voxel encoder that injects geometric context into the generative process in three complementary ways: providing voxel features as vertex representations, guiding token prediction via cross-attention to voxel features, and serving as a structural scaffold that constrains generation around the input surface. Our hierarchical design enables coarse-to-fine vertex prediction in a single decoding step, while tightly coupling the generative model with 3D geometry. Extensive experiments demonstrate that MeshWeaver achieves a state-of-the-art compression ratio of 18%, can generate meshes with up to 16K faces, and significantly improves geometric fidelity over prior approaches.
MSCGC-KAN: Multi-scale Causal Graph Convolution and Kolmogorov-Arnold Feature Mapping for EEG Emotion Recognition
May 27, 2026Electroencephalogram (EEG)-based emotion recognition is an important affective computing task, and recent EEG foundation models provide useful generic representations for downstream adaptation. However, under the fine-tuning setting, three limitations remain prominent: insufficient modeling of multi-scale emotional dynamics, inadequate exploitation of inter-channel functional connectivity, and the limited expressive power of simple linear classification heads. To address these issues, this paper proposes a new EEG emotion recognition method, termed MSCGC-KAN, which introduces a structured task head composed of multi-scale causal graph convolution and Kolmogorov--Arnold feature mapping. Built on a pre-trained CBraMod backbone, MSCGC-KAN enhances downstream adaptation by jointly strengthening multi-scale temporal modeling, learnable inter-channel connectivity modeling, and nonlinear discriminative mapping within a compact task-specific head. This design preserves the representation advantage of the foundation model while making the classifier more sensitive to emotion-related spatiotemporal patterns. Extensive experiments are conducted on the public FACED and SEED-VII datasets. The proposed method achieves a balanced accuracy of 60.66\%, a Cohen's Kappa of 0.5525, and a weighted F1-score of 60.40\% on FACED, and obtains 33.27\%, 0.2223, and 33.64\%, respectively, on SEED-VII. Compared with the CBraMod+Linear baseline, the balanced accuracy is improved by 5.91 and 2.03 percentage points on the two datasets, respectively. These results indicate that structured task-head design is an effective way to improve EEG emotion recognition when fine-tuning pre-trained EEG models.
Sculpt4D: Generating 4D Shapes via Sparse-Attention Diffusion Transformers
Apr 23, 2026Recent breakthroughs in 3D generative modeling have yielded remarkable progress in static shape synthesis, yet high-fidelity dynamic 4D generation remains elusive, hindered by temporal artifacts and prohibitive computational demand. We present Sculpt4D, a native 4D generative framework that seamlessly integrates efficient temporal modeling into a pretrained 3D Diffusion Transformer (Hunyuan3D 2.1), thereby mitigating the scarcity of 4D training data. At its core lies a Block Sparse Attention mechanism that preserves object identity by anchoring to the initial frame while capturing rich motion dynamics via a time-decaying sparse mask. This design faithfully models complex spatiotemporal dependencies with high fidelity, while sidestepping the quadratic overhead of full attention and reducing network total computation by 56%. Consequently, Sculpt4D establishes a new state-of-the-art in temporally coherent 4D synthesis and charts a path toward efficient and scalable 4D generation.
Subject-Aware Multi-Granularity Alignment for Zero-Shot EEG-to-Image Retrieval
Apr 20, 2026Zero-shot EEG-to-image retrieval aims to decode perceived visual content from electroencephalography (EEG) by aligning neural responses with pretrained visual representations, providing a promising route toward scalable visual neural decoding and practical brain-computer interfaces. However, robust EEG-to-image retrieval remains challenging, because prior methods usually rely on either a single fixed visual target or a subject-invariant target construction scheme. Such designs overlook two important properties of visually evoked EEG signals: they preserve information across multiple representational scales, and the visual granularity best matched to EEG may vary across subjects. To address these issues, subject-aware multi-granularity alignment (SAMGA) framework is proposed for zero-shot EEG-to-image retrieval. SAMGA first constructs a subject-aware visual supervision target by adaptively aggregating multiple intermediate representations from a pretrained vision encoder, allowing the model to absorb subject-dependent granularity deviations during training while preserving subject-agnostic inference. Building on this adaptive target construction, a coarse-to-fine cross-modal alignment strategy is further designed with a shared encoder wherein the coarse stage stabilizes the shared semantic geometry and reduces subject-induced distribution shift, and the fine stage further improves instance-level retrieval discrimination. Extensive experiments on the THINGS-EEG benchmark demonstrate that the proposed method achieves 91.3% Top-1 and 98.8% Top-5 accuracy in the intra-subject setting, and 34.4% Top-1 and 64.8% Top-5 accuracy in the inter-subject setting, outperforming recent state-of-the-art methods.
IC-Custom: Diverse Image Customization via In-Context Learning
Jul 02, 2025Image customization, a crucial technique for industrial media production, aims to generate content that is consistent with reference images. However, current approaches conventionally separate image customization into position-aware and position-free customization paradigms and lack a universal framework for diverse customization, limiting their applications across various scenarios. To overcome these limitations, we propose IC-Custom, a unified framework that seamlessly integrates position-aware and position-free image customization through in-context learning. IC-Custom concatenates reference images with target images to a polyptych, leveraging DiT's multi-modal attention mechanism for fine-grained token-level interactions. We introduce the In-context Multi-Modal Attention (ICMA) mechanism with learnable task-oriented register tokens and boundary-aware positional embeddings to enable the model to correctly handle different task types and distinguish various inputs in polyptych configurations. To bridge the data gap, we carefully curated a high-quality dataset of 12k identity-consistent samples with 8k from real-world sources and 4k from high-quality synthetic data, avoiding the overly glossy and over-saturated synthetic appearance. IC-Custom supports various industrial applications, including try-on, accessory placement, furniture arrangement, and creative IP customization. Extensive evaluations on our proposed ProductBench and the publicly available DreamBench demonstrate that IC-Custom significantly outperforms community workflows, closed-source models, and state-of-the-art open-source approaches. IC-Custom achieves approximately 73% higher human preference across identity consistency, harmonicity, and text alignment metrics, while training only 0.4% of the original model parameters. Project page: https://liyaowei-stu.github.io/project/IC_Custom
DepthSync: Diffusion Guidance-Based Depth Synchronization for Scale- and Geometry-Consistent Video Depth Estimation
Jul 02, 2025
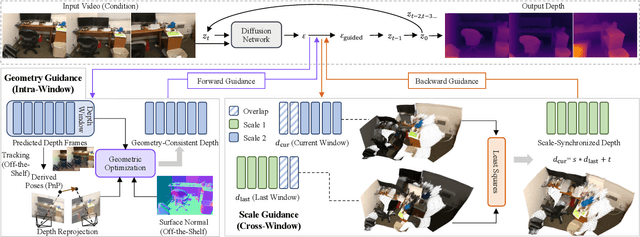

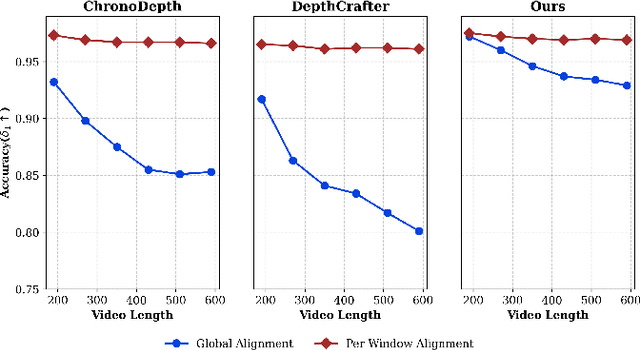
Diffusion-based video depth estimation methods have achieved remarkable success with strong generalization ability. However, predicting depth for long videos remains challenging. Existing methods typically split videos into overlapping sliding windows, leading to accumulated scale discrepancies across different windows, particularly as the number of windows increases. Additionally, these methods rely solely on 2D diffusion priors, overlooking the inherent 3D geometric structure of video depths, which results in geometrically inconsistent predictions. In this paper, we propose DepthSync, a novel, training-free framework using diffusion guidance to achieve scale- and geometry-consistent depth predictions for long videos. Specifically, we introduce scale guidance to synchronize the depth scale across windows and geometry guidance to enforce geometric alignment within windows based on the inherent 3D constraints in video depths. These two terms work synergistically, steering the denoising process toward consistent depth predictions. Experiments on various datasets validate the effectiveness of our method in producing depth estimates with improved scale and geometry consistency, particularly for long videos.
DI-PCG: Diffusion-based Efficient Inverse Procedural Content Generation for High-quality 3D Asset Creation
Dec 19, 2024



Procedural Content Generation (PCG) is powerful in creating high-quality 3D contents, yet controlling it to produce desired shapes is difficult and often requires extensive parameter tuning. Inverse Procedural Content Generation aims to automatically find the best parameters under the input condition. However, existing sampling-based and neural network-based methods still suffer from numerous sample iterations or limited controllability. In this work, we present DI-PCG, a novel and efficient method for Inverse PCG from general image conditions. At its core is a lightweight diffusion transformer model, where PCG parameters are directly treated as the denoising target and the observed images as conditions to control parameter generation. DI-PCG is efficient and effective. With only 7.6M network parameters and 30 GPU hours to train, it demonstrates superior performance in recovering parameters accurately, and generalizing well to in-the-wild images. Quantitative and qualitative experiment results validate the effectiveness of DI-PCG in inverse PCG and image-to-3D generation tasks. DI-PCG offers a promising approach for efficient inverse PCG and represents a valuable exploration step towards a 3D generation path that models how to construct a 3D asset using parametric models.
FreeSplatter: Pose-free Gaussian Splatting for Sparse-view 3D Reconstruction
Dec 12, 2024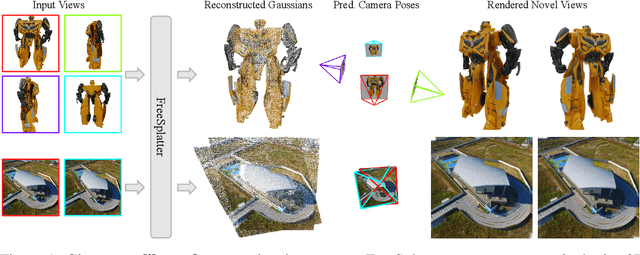
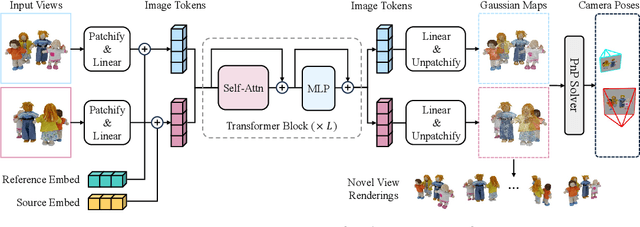


Existing sparse-view reconstruction models heavily rely on accurate known camera poses. However, deriving camera extrinsics and intrinsics from sparse-view images presents significant challenges. In this work, we present FreeSplatter, a highly scalable, feed-forward reconstruction framework capable of generating high-quality 3D Gaussians from uncalibrated sparse-view images and recovering their camera parameters in mere seconds. FreeSplatter is built upon a streamlined transformer architecture, comprising sequential self-attention blocks that facilitate information exchange among multi-view image tokens and decode them into pixel-wise 3D Gaussian primitives. The predicted Gaussian primitives are situated in a unified reference frame, allowing for high-fidelity 3D modeling and instant camera parameter estimation using off-the-shelf solvers. To cater to both object-centric and scene-level reconstruction, we train two model variants of FreeSplatter on extensive datasets. In both scenarios, FreeSplatter outperforms state-of-the-art baselines in terms of reconstruction quality and pose estimation accuracy. Furthermore, we showcase FreeSplatter's potential in enhancing the productivity of downstream applications, such as text/image-to-3D content creation.
NVComposer: Boosting Generative Novel View Synthesis with Multiple Sparse and Unposed Images
Dec 04, 2024



Recent advancements in generative models have significantly improved novel view synthesis (NVS) from multi-view data. However, existing methods depend on external multi-view alignment processes, such as explicit pose estimation or pre-reconstruction, which limits their flexibility and accessibility, especially when alignment is unstable due to insufficient overlap or occlusions between views. In this paper, we propose NVComposer, a novel approach that eliminates the need for explicit external alignment. NVComposer enables the generative model to implicitly infer spatial and geometric relationships between multiple conditional views by introducing two key components: 1) an image-pose dual-stream diffusion model that simultaneously generates target novel views and condition camera poses, and 2) a geometry-aware feature alignment module that distills geometric priors from dense stereo models during training. Extensive experiments demonstrate that NVComposer achieves state-of-the-art performance in generative multi-view NVS tasks, removing the reliance on external alignment and thus improving model accessibility. Our approach shows substantial improvements in synthesis quality as the number of unposed input views increases, highlighting its potential for more flexible and accessible generative NVS systems.
NovelGS: Consistent Novel-view Denoising via Large Gaussian Reconstruction Model
Nov 25, 2024


We introduce NovelGS, a diffusion model for Gaussian Splatting (GS) given sparse-view images. Recent works leverage feed-forward networks to generate pixel-aligned Gaussians, which could be fast rendered. Unfortunately, the method was unable to produce satisfactory results for areas not covered by the input images due to the formulation of these methods. In contrast, we leverage the novel view denoising through a transformer-based network to generate 3D Gaussians. Specifically, by incorporating both conditional views and noisy target views, the network predicts pixel-aligned Gaussians for each view. During training, the rendered target and some additional views of the Gaussians are supervised. During inference, the target views are iteratively rendered and denoised from pure noise. Our approach demonstrates state-of-the-art performance in addressing the multi-view image reconstruction challenge. Due to generative modeling of unseen regions, NovelGS effectively reconstructs 3D objects with consistent and sharp textures. Experimental results on publicly available datasets indicate that NovelGS substantially surpasses existing image-to-3D frameworks, both qualitatively and quantitatively. We also demonstrate the potential of NovelGS in generative tasks, such as text-to-3D and image-to-3D, by integrating it with existing multiview diffusion models. We will make the code publicly accessible.