 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGF-DiT: Scheduling Parallelism for Diffusion Transformer Serving
Jun 11, 2026Diffusion Transformers (DiTs) have become the dominant architecture for image and video generation, creating growing demand for efficient DiT serving. Existing systems assign each request a fixed parallel configuration throughout its lifetime. However, DiT workloads exhibit substantial heterogeneity across requests, execution stages, and system conditions, making static parallelism inefficient and often leading to poor GPU utilization and degraded service quality. This paper argues that DiT serving should treat GPU parallelism as a first-class schedulable resource. We present GF-DiT, a policy-programmable runtime for elastic DiT serving that dynamically adapts the parallelism of running requests according to workload demands and service objectives. GF-DiT introduces an asynchronous execution abstraction that decomposes requests into independently schedulable trajectory tasks and enables online GPU reallocation. To make elastic parallelism practical, GF-DiT further proposes group-free collectives, a lightweight communication abstraction that supports low-overhead online formation and reconfiguration of arbitrary execution groups. We implement GF-DiT in vLLM-Omni and evaluate it on representative image and video diffusion workloads. Compared with fixed-pipeline execution with static parallelism, GF-DiT improves throughput by up to 6.01$\times$, reduces mean latency by up to 95%, lowers SLO violation rates by up to 90%, and reduces communication-group setup overhead from 778 ms to approximately 60 $μ$s.
CuBridge: An LLM-Based Framework for Understanding and Reconstructing High-Performance Attention Kernels
May 06, 2026Efficient CUDA implementations of attention mechanisms are critical to modern deep learning systems, yet supporting diverse and evolving attention variants remains challenging. Existing frameworks and compilers trade performance for flexibility, while expert-written kernels achieve high efficiency but are difficult to adapt. Recent work explores large language models (LLMs) for GPU kernel generation, but prior studies report unstable correctness and significant performance gaps for complex operators such as attention. We present CuBridge, an LLM-based framework that adapts expert-written attention kernels through a structured lift-transfer-lower workflow. CuBridge starts from expert-written CUDA attention kernels and lifts them into an executable intermediate representation that makes execution orchestration explicit while abstracting low-level CUDA syntax. Given a user-provided PyTorch specification, CuBridge generates and verifies a target IR program, then reconstructs optimized CUDA code via reference-guided lowering. Across diverse attention variants and GPU platforms, CuBridge consistently produces correct kernels and substantially outperforms general frameworks, compiler-based approaches, and prior LLM-based methods.
DataFlex: A Unified Framework for Data-Centric Dynamic Training of Large Language Models
Mar 27, 2026Data-centric training has emerged as a promising direction for improving large language models (LLMs) by optimizing not only model parameters but also the selection, composition, and weighting of training data during optimization. However, existing approaches to data selection, data mixture optimization, and data reweighting are often developed in isolated codebases with inconsistent interfaces, hindering reproducibility, fair comparison, and practical integration. In this paper, we present DataFlex, a unified data-centric dynamic training framework built upon LLaMA-Factory. DataFlex supports three major paradigms of dynamic data optimization: sample selection, domain mixture adjustment, and sample reweighting, while remaining fully compatible with the original training workflow. It provides extensible trainer abstractions and modular components, enabling a drop-in replacement for standard LLM training, and unifies key model-dependent operations such as embedding extraction, inference, and gradient computation, with support for large-scale settings including DeepSpeed ZeRO-3. We conduct comprehensive experiments across multiple data-centric methods. Dynamic data selection consistently outperforms static full-data training on MMLU across both Mistral-7B and Llama-3.2-3B. For data mixture, DoReMi and ODM improve both MMLU accuracy and corpus-level perplexity over default proportions when pretraining Qwen2.5-1.5B on SlimPajama at 6B and 30B token scales. DataFlex also achieves consistent runtime improvements over original implementations. These results demonstrate that DataFlex provides an effective, efficient, and reproducible infrastructure for data-centric dynamic training of LLMs.
DASH: Deterministic Attention Scheduling for High-throughput Reproducible LLM Training
Jan 29, 2026Determinism is indispensable for reproducibility in large language model (LLM) training, yet it often exacts a steep performance cost. In widely used attention implementations such as FlashAttention-3, the deterministic backward pass can incur up to a 37.9% throughput reduction relative to its non-deterministic counterpart, primarily because gradient accumulation operations must be serialized to guarantee numerical consistency. This performance loss stems from suboptimal scheduling of compute and gradient-reduction phases, leading to significant hardware underutilization. To address this challenge, we formulate the backward pass of deterministic attention as a scheduling problem on a Directed Acyclic Graph (DAG) and derive schedules that minimize the critical path length. Building on this formulation, we present DASH (Deterministic Attention Scheduling for High-Throughput), which encapsulates two complementary scheduling strategies: (i) Descending Q-Tile Iteration, a reversed query-block traversal that shrinks pipeline stalls in causal attention, and (ii) Shift Scheduling, a theoretically optimal schedule within our DAG model that reduces pipeline stalls for both full and causal masks. Our empirical evaluations on NVIDIA H800 GPUs demonstrate that DASH narrows the performance gap of deterministic attention. The proposed strategies improve the throughput of the attention backward pass by up to 1.28$\times$ compared to the baseline, significantly advancing the efficiency of reproducible LLM training. Our code is open-sourced at https://github.com/SJTU-Liquid/deterministic-FA3.
ClusterFusion: Expanding Operator Fusion Scope for LLM Inference via Cluster-Level Collective Primitive
Aug 26, 2025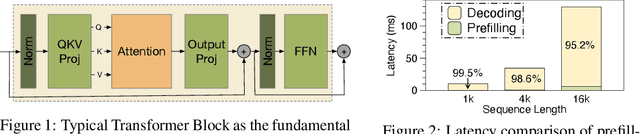
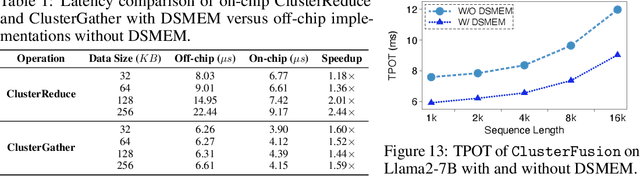
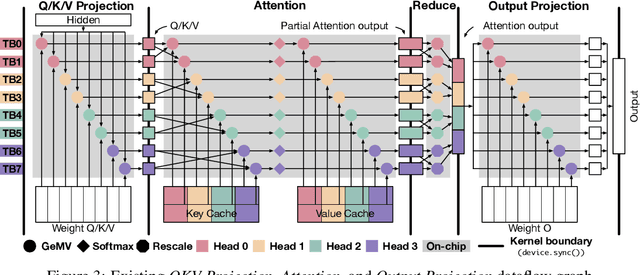
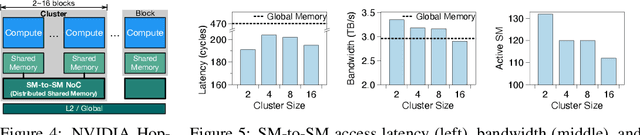
Large language model (LLM) decoding suffers from high latency due to fragmented execution across operators and heavy reliance on off-chip memory for data exchange and reduction. This execution model limits opportunities for fusion and incurs significant memory traffic and kernel launch overhead. While modern architectures such as NVIDIA Hopper provide distributed shared memory and low-latency intra-cluster interconnects, they expose only low-level data movement instructions, lacking structured abstractions for collective on-chip communication. To bridge this software-hardware gap, we introduce two cluster-level communication primitives, ClusterReduce and ClusterGather, which abstract common communication patterns and enable structured, high-speed data exchange and reduction between thread blocks within a cluster, allowing intermediate results to be on-chip without involving off-chip memory. Building on these abstractions, we design ClusterFusion, an execution framework that schedules communication and computation jointly to expand operator fusion scope by composing decoding stages such as QKV Projection, Attention, and Output Projection into a single fused kernels. Evaluations on H100 GPUs show that ClusterFusion outperforms state-of-the-art inference frameworks by 1.61x on average in end-to-end latency across different models and configurations. The source code is available at https://github.com/xinhao-luo/ClusterFusion.
SMA: Who Said That? Auditing Membership Leakage in Semi-Black-box RAG Controlling
Aug 12, 2025Retrieval-Augmented Generation (RAG) and its Multimodal Retrieval-Augmented Generation (MRAG) significantly improve the knowledge coverage and contextual understanding of Large Language Models (LLMs) by introducing external knowledge sources. However, retrieval and multimodal fusion obscure content provenance, rendering existing membership inference methods unable to reliably attribute generated outputs to pre-training, external retrieval, or user input, thus undermining privacy leakage accountability To address these challenges, we propose the first Source-aware Membership Audit (SMA) that enables fine-grained source attribution of generated content in a semi-black-box setting with retrieval control capabilities.To address the environmental constraints of semi-black-box auditing, we further design an attribution estimation mechanism based on zero-order optimization, which robustly approximates the true influence of input tokens on the output through large-scale perturbation sampling and ridge regression modeling. In addition, SMA introduces a cross-modal attribution technique that projects image inputs into textual descriptions via MLLMs, enabling token-level attribution in the text modality, which for the first time facilitates membership inference on image retrieval traces in MRAG systems. This work shifts the focus of membership inference from 'whether the data has been memorized' to 'where the content is sourced from', offering a novel perspective for auditing data provenance in complex generative systems.
Efficient Serving of LLM Applications with Probabilistic Demand Modeling
Jun 17, 2025Applications based on Large Language Models (LLMs) contains a series of tasks to address real-world problems with boosted capability, which have dynamic demand volumes on diverse backends. Existing serving systems treat the resource demands of LLM applications as a blackbox, compromising end-to-end efficiency due to improper queuing order and backend warm up latency. We find that the resource demands of LLM applications can be modeled in a general and accurate manner with Probabilistic Demand Graph (PDGraph). We then propose Hermes, which leverages PDGraph for efficient serving of LLM applications. Confronting probabilistic demand description, Hermes applies the Gittins policy to determine the scheduling order that can minimize the average application completion time. It also uses the PDGraph model to help prewarm cold backends at proper moments. Experiments with diverse LLM applications confirm that Hermes can effectively improve the application serving efficiency, reducing the average completion time by over 70% and the P95 completion time by over 80%.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
A Framework to Assess Multilingual Vulnerabilities of LLMs
Mar 17, 2025



Large Language Models (LLMs) are acquiring a wider range of capabilities, including understanding and responding in multiple languages. While they undergo safety training to prevent them from answering illegal questions, imbalances in training data and human evaluation resources can make these models more susceptible to attacks in low-resource languages (LRL). This paper proposes a framework to automatically assess the multilingual vulnerabilities of commonly used LLMs. Using our framework, we evaluated six LLMs across eight languages representing varying levels of resource availability. We validated the assessments generated by our automated framework through human evaluation in two languages, demonstrating that the framework's results align with human judgments in most cases. Our findings reveal vulnerabilities in LRL; however, these may pose minimal risk as they often stem from the model's poor performance, resulting in incoherent responses.
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jul 22, 2024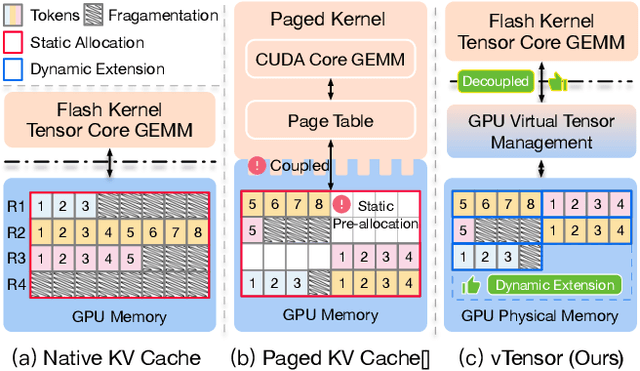

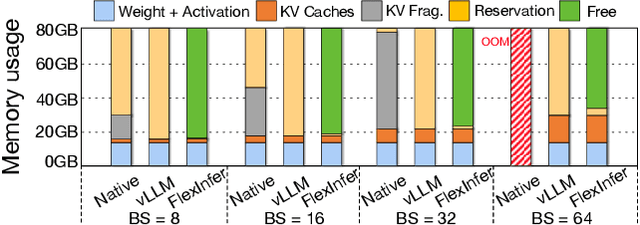
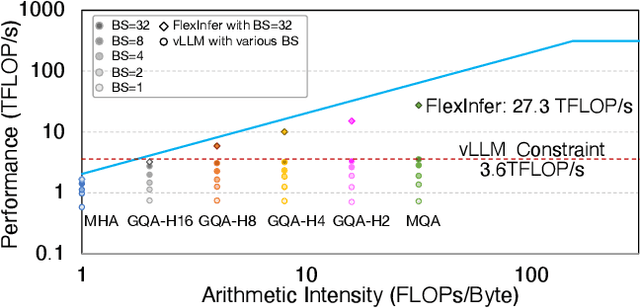
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.