 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
Fooling the Watchers: Breaking AIGC Detectors via Semantic Prompt Attacks
May 29, 2025The rise of text-to-image (T2I) models has enabled the synthesis of photorealistic human portraits, raising serious concerns about identity misuse and the robustness of AIGC detectors. In this work, we propose an automated adversarial prompt generation framework that leverages a grammar tree structure and a variant of the Monte Carlo tree search algorithm to systematically explore the semantic prompt space. Our method generates diverse, controllable prompts that consistently evade both open-source and commercial AIGC detectors. Extensive experiments across multiple T2I models validate its effectiveness, and the approach ranked first in a real-world adversarial AIGC detection competition. Beyond attack scenarios, our method can also be used to construct high-quality adversarial datasets, providing valuable resources for training and evaluating more robust AIGC detection and defense systems.
ESA: Example Sieve Approach for Multi-Positive and Unlabeled Learning
Dec 03, 2024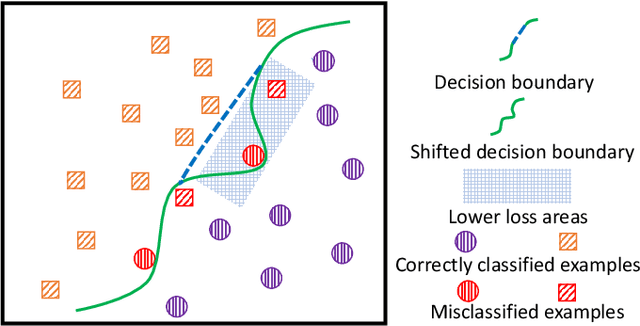

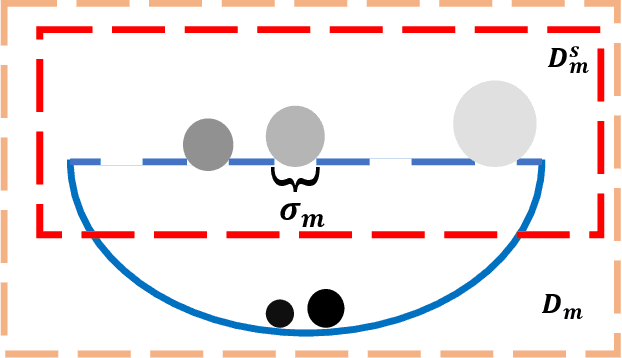

Learning from Multi-Positive and Unlabeled (MPU) data has gradually attracted significant attention from practical applications. Unfortunately, the risk of MPU also suffer from the shift of minimum risk, particularly when the models are very flexible as shown in Fig.\ref{moti}. In this paper, to alleviate the shifting of minimum risk problem, we propose an Example Sieve Approach (ESA) to select examples for training a multi-class classifier. Specifically, we sieve out some examples by utilizing the Certain Loss (CL) value of each example in the training stage and analyze the consistency of the proposed risk estimator. Besides, we show that the estimation error of proposed ESA obtains the optimal parametric convergence rate. Extensive experiments on various real-world datasets show the proposed approach outperforms previous methods.
Learning from Concealed Labels
Dec 03, 2024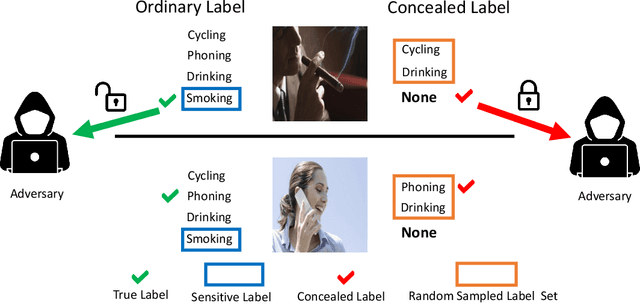

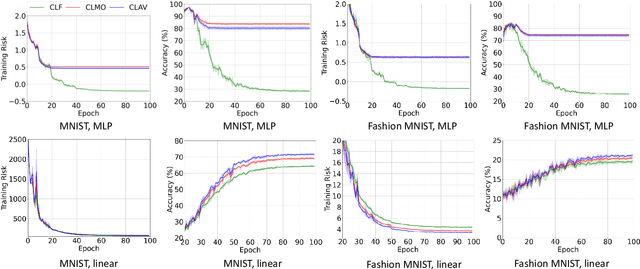
Annotating data for sensitive labels (e.g., disease, smoking) poses a potential threats to individual privacy in many real-world scenarios. To cope with this problem, we propose a novel setting to protect privacy of each instance, namely learning from concealed labels for multi-class classification. Concealed labels prevent sensitive labels from appearing in the label set during the label collection stage, which specifies none and some random sampled insensitive labels as concealed labels set to annotate sensitive data. In this paper, an unbiased estimator can be established from concealed data under mild assumptions, and the learned multi-class classifier can not only classify the instance from insensitive labels accurately but also recognize the instance from the sensitive labels. Moreover, we bound the estimation error and show that the multi-class classifier achieves the optimal parametric convergence rate. Experiments demonstrate the significance and effectiveness of the proposed method for concealed labels in synthetic and real-world datasets.
CoA: Chain-of-Action for Generative Semantic Labels
Nov 26, 2024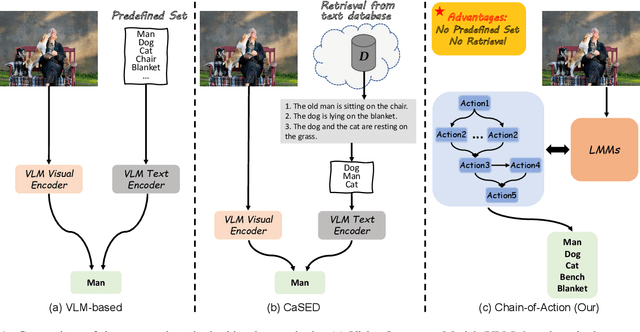
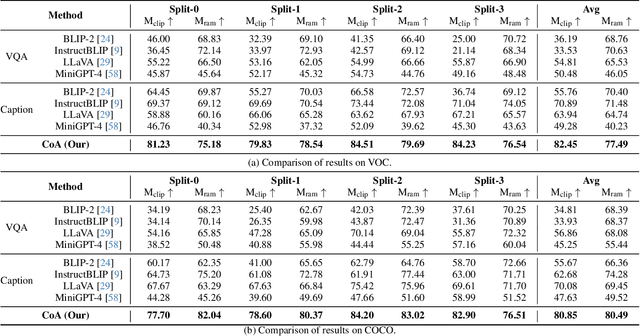

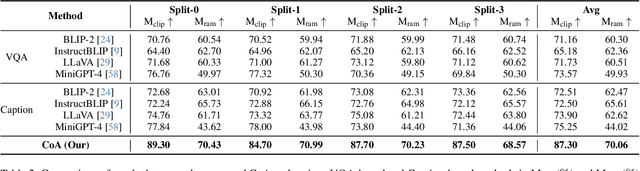
Recent advances in vision-language models (VLM) have demonstrated remarkable capability in image classification. These VLMs leverage a predefined set of categories to construct text prompts for zero-shot reasoning. However, in more open-ended domains like autonomous driving, using a predefined set of labels becomes impractical, as the semantic label space is unknown and constantly evolving. Additionally, fixed embedding text prompts often tend to predict a single label (while in reality, multiple labels commonly exist per image). In this paper, we introduce CoA, an innovative Chain-of-Action (CoA) method that generates labels aligned with all contextually relevant features of an image. CoA is designed based on the observation that enriched and valuable contextual information improves generative performance during inference. Traditional vision-language models tend to output singular and redundant responses. Therefore, we employ a tailored CoA to alleviate this problem. We first break down the generative labeling task into detailed actions and construct an CoA leading to the final generative objective. Each action extracts and merges key information from the previous action and passes the enriched information as context to the next action, ultimately improving the VLM in generating comprehensive and accurate semantic labels. We assess the effectiveness of CoA through comprehensive evaluations on widely-used benchmark datasets and the results demonstrate significant improvements across key performance metrics.
Learning from True-False Labels via Multi-modal Prompt Retrieving
May 24, 2024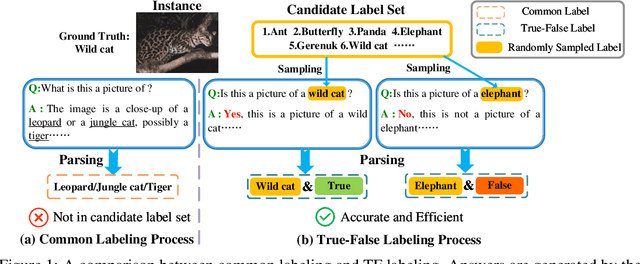

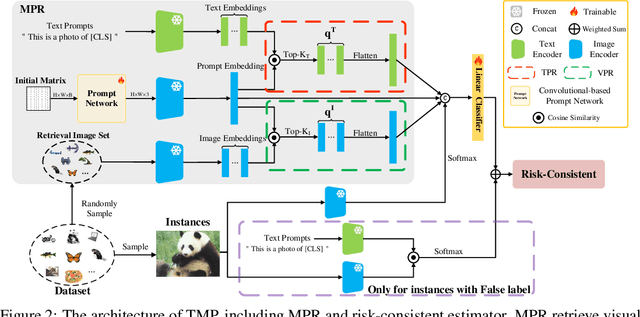

Weakly supervised learning has recently achieved considerable success in reducing annotation costs and label noise. Unfortunately, existing weakly supervised learning methods are short of ability in generating reliable labels via pre-trained vision-language models (VLMs). In this paper, we propose a novel weakly supervised labeling setting, namely True-False Labels (TFLs) which can achieve high accuracy when generated by VLMs. The TFL indicates whether an instance belongs to the label, which is randomly and uniformly sampled from the candidate label set. Specifically, we theoretically derive a risk-consistent estimator to explore and utilize the conditional probability distribution information of TFLs. Besides, we propose a convolutional-based Multi-modal Prompt Retrieving (MRP) method to bridge the gap between the knowledge of VLMs and target learning tasks. Experimental results demonstrate the effectiveness of the proposed TFL setting and MRP learning method. The code to reproduce the experiments is at https://github.com/Tranquilxu/TMP.
Determined Multi-Label Learning via Similarity-Based Prompt
Mar 25, 2024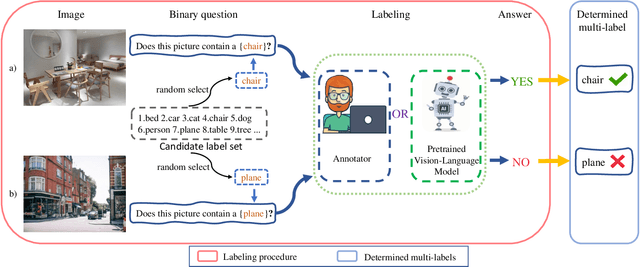
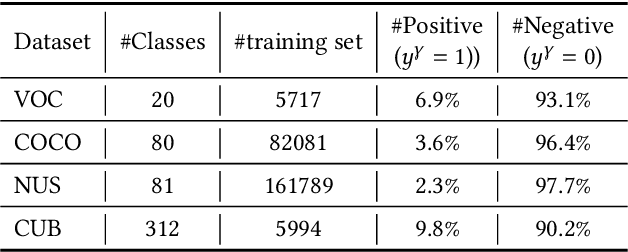
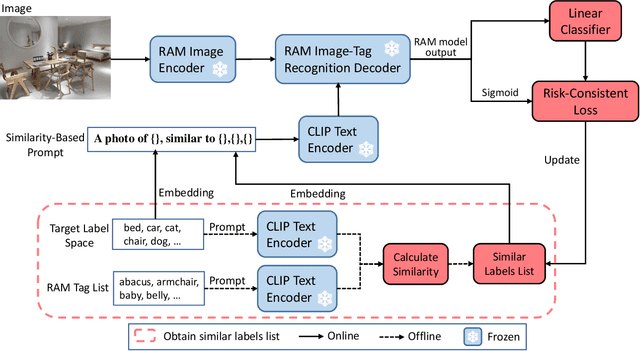
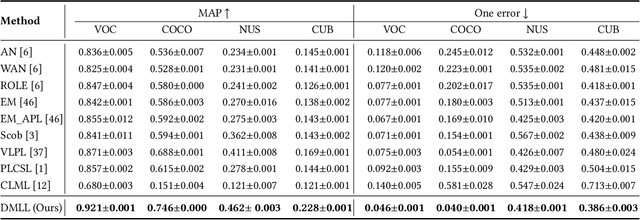
In multi-label classification, each training instance is associated with multiple class labels simultaneously. Unfortunately, collecting the fully precise class labels for each training instance is time- and labor-consuming for real-world applications. To alleviate this problem, a novel labeling setting termed \textit{Determined Multi-Label Learning} (DMLL) is proposed, aiming to effectively alleviate the labeling cost inherent in multi-label tasks. In this novel labeling setting, each training instance is associated with a \textit{determined label} (either "Yes" or "No"), which indicates whether the training instance contains the provided class label. The provided class label is randomly and uniformly selected from the whole candidate labels set. Besides, each training instance only need to be determined once, which significantly reduce the annotation cost of the labeling task for multi-label datasets. In this paper, we theoretically derive an risk-consistent estimator to learn a multi-label classifier from these determined-labeled training data. Additionally, we introduce a similarity-based prompt learning method for the first time, which minimizes the risk-consistent loss of large-scale pre-trained models to learn a supplemental prompt with richer semantic information. Extensive experimental validation underscores the efficacy of our approach, demonstrating superior performance compared to existing state-of-the-art methods.