 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoA: Chain-of-Action for Generative Semantic Labels
Paper and Code
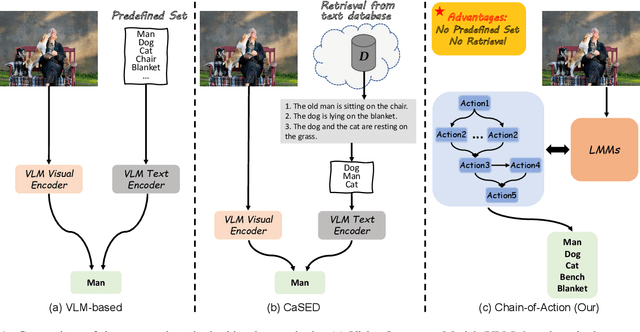
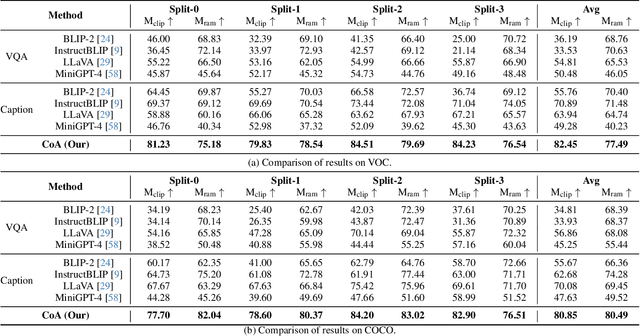

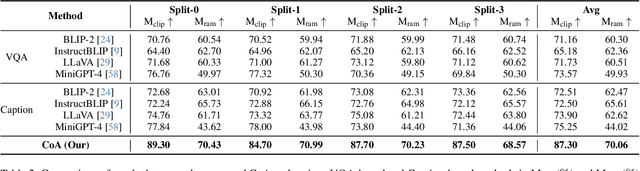
Recent advances in vision-language models (VLM) have demonstrated remarkable capability in image classification. These VLMs leverage a predefined set of categories to construct text prompts for zero-shot reasoning. However, in more open-ended domains like autonomous driving, using a predefined set of labels becomes impractical, as the semantic label space is unknown and constantly evolving. Additionally, fixed embedding text prompts often tend to predict a single label (while in reality, multiple labels commonly exist per image). In this paper, we introduce CoA, an innovative Chain-of-Action (CoA) method that generates labels aligned with all contextually relevant features of an image. CoA is designed based on the observation that enriched and valuable contextual information improves generative performance during inference. Traditional vision-language models tend to output singular and redundant responses. Therefore, we employ a tailored CoA to alleviate this problem. We first break down the generative labeling task into detailed actions and construct an CoA leading to the final generative objective. Each action extracts and merges key information from the previous action and passes the enriched information as context to the next action, ultimately improving the VLM in generating comprehensive and accurate semantic labels. We assess the effectiveness of CoA through comprehensive evaluations on widely-used benchmark datasets and the results demonstrate significant improvements across key performance metrics.