 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Forensics in AI-Native Wireless Networks: Taxonomy, Applications, and Case Study
May 14, 2026As artificial intelligence (AI) is increasingly embedded in wireless networks, models are becoming core components that influence signal processing, resource scheduling and network control. However, model anomalies, tampering and malicious functions also introduce new security risks. In this article, we focus on model forensics in AI-native wireless networks. Specifically, we first discuss key problems including model authenticity verification, malicious function identification and accountability tracing, and summarize the main categories of model forensics. We then explain the role of model forensics in AI-native wireless networks and review representative application scenarios. In the case study, we use RF fingerprinting as an example and present two concrete workflows based on watermark authentication and backdoor detection, illustrating how provenance authentication and malicious behavior identification can be implemented in practice. The results show that model forensics can provide important support for anomaly assessment, provenance tracing and trustworthy operation in AI-native wireless networks. Finally, we outline several promising directions for future research in this emerging area.
SDD-YOLO: A Small-Target Detection Framework for Ground-to-Air Anti-UAV Surveillance with Edge-Efficient Deployment
Mar 26, 2026Detecting small unmanned aerial vehicles (UAVs) from a ground-to-air (G2A) perspective presents significant challenges, including extremely low pixel occupancy, cluttered aerial backgrounds, and strict real-time constraints. Existing YOLO-based detectors are primarily optimized for general object detection and often lack adequate feature resolution for sub-pixel targets, while introducing complexities during deployment. In this paper, we propose SDD-YOLO, a small-target detection framework tailored for G2A anti-UAV surveillance. To capture fine-grained spatial details critical for micro-targets, SDD-YOLO introduces a P2 high-resolution detection head operating at 4 times downsampling. Furthermore, we integrate the recent architectural advancements from YOLO26, including a DFL-free, NMS-free architecture for streamlined inference, and the MuSGD hybrid training strategy with ProgLoss and STAL, which substantially mitigates gradient oscillation on sparse small-target signals. To support our evaluation, we construct DroneSOD-30K, a large-scale G2A dataset comprising approximately 30,000 annotated images covering diverse meteorological conditions. Experiments demonstrate that SDD-YOLO-n achieves a mAP@0.5 of 86.0% on DroneSOD-30K, surpassing the YOLOv5n baseline by 7.8 percentage points. Extensive inference analysis shows our model attains 226 FPS on an NVIDIA RTX 5090 and 35 FPS on an Intel Xeon CPU, demonstrating exceptional efficiency for future edge deployment.
ZS-TreeSeg: A Zero-Shot Framework for Tree Crown Instance Segmentation
Jan 31, 2026Individual tree crown segmentation is an important task in remote sensing for forest biomass estimation and ecological monitoring. However, accurate delineation in dense, overlapping canopies remains a bottleneck. While supervised deep learning methods suffer from high annotation costs and limited generalization, emerging foundation models (e.g., Segment Anything Model) often lack domain knowledge, leading to under-segmentation in dense clusters. To bridge this gap, we propose ZS-TreeSeg, a Zero-Shot framework that adapts from two mature tasks: 1) Canopy Semantic segmentation; and 2) Cells instance segmentation. By modeling tree crowns as star-convex objects within a topological flow field using Cellpose-SAM, the ZS-TreeSeg framework forces the mathematical separation of touching tree crown instances based on vector convergence. Experiments on the NEON and BAMFOREST datasets and visual inspection demonstrate that our framework generalizes robustly across diverse sensor types and canopy densities, which can offer a training-free solution for tree crown instance segmentation and labels generation.
CoDrone: Autonomous Drone Navigation Assisted by Edge and Cloud Foundation Models
Dec 24, 2025Autonomous navigation for Unmanned Aerial Vehicles faces key challenges from limited onboard computational resources, which restrict deployed deep neural networks to shallow architectures incapable of handling complex environments. Offloading tasks to remote edge servers introduces high latency, creating an inherent trade-off in system design. To address these limitations, we propose CoDrone - the first cloud-edge-end collaborative computing framework integrating foundation models into autonomous UAV cruising scenarios - effectively leveraging foundation models to enhance performance of resource-constrained unmanned aerial vehicle platforms. To reduce onboard computation and data transmission overhead, CoDrone employs grayscale imagery for the navigation model. When enhanced environmental perception is required, CoDrone leverages the edge-assisted foundation model Depth Anything V2 for depth estimation and introduces a novel one-dimensional occupancy grid-based navigation method - enabling fine-grained scene understanding while advancing efficiency and representational simplicity of autonomous navigation. A key component of CoDrone is a Deep Reinforcement Learning-based neural scheduler that seamlessly integrates depth estimation with autonomous navigation decisions, enabling real-time adaptation to dynamic environments. Furthermore, the framework introduces a UAV-specific vision language interaction module incorporating domain-tailored low-level flight primitives to enable effective interaction between the cloud foundation model and the UAV. The introduction of VLM enhances open-set reasoning capabilities in complex unseen scenarios. Experimental results show CoDrone outperforms baseline methods under varying flight speeds and network conditions, achieving a 40% increase in average flight distance and a 5% improvement in average Quality of Navigation.
Pushing the Limits of Safety: A Technical Report on the ATLAS Challenge 2025
Jun 14, 2025Multimodal Large Language Models (MLLMs) have enabled transformative advancements across diverse applications but remain susceptible to safety threats, especially jailbreak attacks that induce harmful outputs. To systematically evaluate and improve their safety, we organized the Adversarial Testing & Large-model Alignment Safety Grand Challenge (ATLAS) 2025}. This technical report presents findings from the competition, which involved 86 teams testing MLLM vulnerabilities via adversarial image-text attacks in two phases: white-box and black-box evaluations. The competition results highlight ongoing challenges in securing MLLMs and provide valuable guidance for developing stronger defense mechanisms. The challenge establishes new benchmarks for MLLM safety evaluation and lays groundwork for advancing safer multimodal AI systems. The code and data for this challenge are openly available at https://github.com/NY1024/ATLAS_Challenge_2025.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


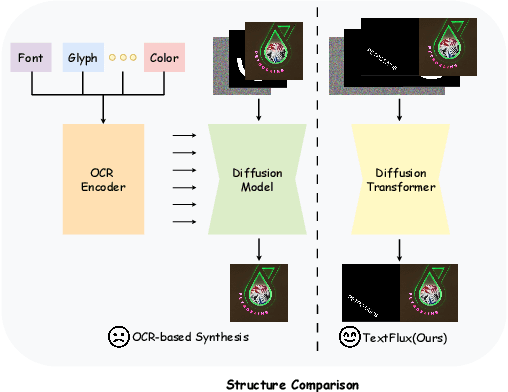
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
Intelligent Bear Prevention System Based on Computer Vision: An Approach to Reduce Human-Bear Conflicts in the Tibetan Plateau Area, China
Mar 29, 2025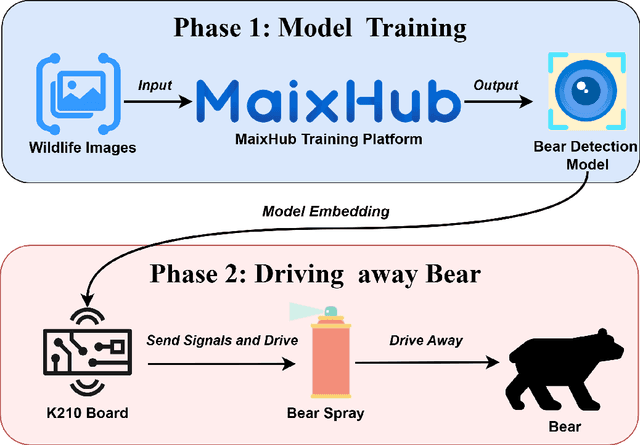
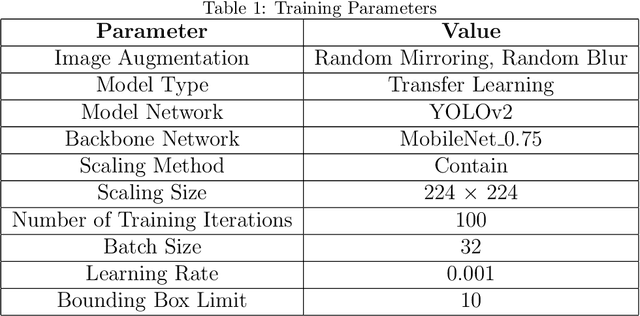

Conflicts between humans and bears on the Tibetan Plateau present substantial threats to local communities and hinder wildlife preservation initiatives. This research introduces a novel strategy that incorporates computer vision alongside Internet of Things (IoT) technologies to alleviate these issues. Tailored specifically for the harsh environment of the Tibetan Plateau, the approach utilizes the K210 development board paired with the YOLO object detection framework along with a tailored bear-deterrent mechanism, offering minimal energy usage and real-time efficiency in bear identification and deterrence. The model's performance was evaluated experimentally, achieving a mean Average Precision (mAP) of 91.4%, demonstrating excellent precision and dependability. By integrating energy-efficient components, the proposed system effectively surpasses the challenges of remote and off-grid environments, ensuring uninterrupted operation in secluded locations. This study provides a viable, eco-friendly, and expandable solution to mitigate human-bear conflicts, thereby improving human safety and promoting bear conservation in isolated areas like Yushu, China.
A GAN-Enhanced Deep Learning Framework for Rooftop Detection from Historical Aerial Imagery
Mar 29, 2025Accurate rooftop detection from historical aerial imagery is vital for examining long-term urban development and human settlement patterns. However, black-and-white analog photographs pose significant challenges for modern object detection frameworks due to their limited spatial resolution, lack of color information, and archival degradation. To address these limitations, this study introduces a two-stage image enhancement pipeline based on Generative Adversarial Networks (GANs): image colorization using DeOldify, followed by super-resolution enhancement with Real-ESRGAN. The enhanced images were then used to train and evaluate rooftop detection models, including Faster R-CNN, DETReg, and YOLOv11n. Results show that combining colorization with super-resolution substantially improves detection performance, with YOLOv11n achieving a mean Average Precision (mAP) exceeding 85%. This reflects an improvement of approximately 40% over original black-and-white images and 20% over images enhanced through colorization alone. The proposed method effectively bridges the gap between archival imagery and contemporary deep learning techniques, enabling more reliable extraction of building footprints from historical aerial photographs.
InterSliceBoost: Identifying Tissue Layers in Three-dimensional Ultrasound Images for Chronic Lower Back Pain (cLBP) Assessment
Mar 25, 2025Available studies on chronic lower back pain (cLBP) typically focus on one or a few specific tissues rather than conducting a comprehensive layer-by-layer analysis. Since three-dimensional (3-D) images often contain hundreds of slices, manual annotation of these anatomical structures is both time-consuming and error-prone. We aim to develop and validate a novel approach called InterSliceBoost to enable the training of a segmentation model on a partially annotated dataset without compromising segmentation performance. The architecture of InterSliceBoost includes two components: an inter-slice generator and a segmentation model. The generator utilizes residual block-based encoders to extract features from adjacent image-mask pairs (IMPs). Differential features are calculated and input into a decoder to generate inter-slice IMPs. The segmentation model is trained on partially annotated datasets (e.g., skipping 1, 2, 3, or 7 images) and the generated inter-slice IMPs. To validate the performance of InterSliceBoost, we utilized a dataset of 76 B-mode ultrasound scans acquired on 29 subjects enrolled in an ongoing cLBP study. InterSliceBoost, trained on only 33% of the image slices, achieved a mean Dice coefficient of 80.84% across all six layers on the independent test set, with Dice coefficients of 73.48%, 61.11%, 81.87%, 95.74%, 83.52% and 88.74% for segmenting dermis, superficial fat, superficial fascial membrane, deep fat, deep fascial membrane, and muscle. This performance is significantly higher than the conventional model trained on fully annotated images (p<0.05). InterSliceBoost can effectively segment the six tissue layers depicted on 3-D B-model ultrasound images in settings with partial annotations.
Embedding-based Approaches to Hyperpartisan News Detection
Jan 02, 2025


In this paper, we describe our systems in which the objective is to determine whether a given news article could be considered as hyperpartisan. Hyperpartisan news is news that takes an extremely polarized political standpoint with an intention of creating political divide among the public. We attempted several approaches, including n-grams, sentiment analysis, as well as sentence and document representation using pre-tained ELMo. Our best system using pre-trained ELMo with Bidirectional LSTM achieved an accuracy of 83% through 10-fold cross-validation without much hyperparameter tuning.