 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Hidden Profiles to Governable Personalization: Recommender Systems in the Age of LLM Agents
Apr 22, 2026Personalization has traditionally depended on platform-specific user models that are optimized for prediction but remain largely inaccessible to the people they describe. As LLM-based assistants increasingly mediate search, shopping, travel, and content access, this arrangement may be giving way to a new personalization stack in which user representation is no longer confined to isolated platforms. In this paper, we argue that the key issue is not simply that large language models can enhance recommendation quality, but that they reconfigure where and how user representations are produced, exposed, and acted upon. We propose a shift from hidden platform profiling toward governable personalization, where user representations may become more inspectable, revisable, portable, and consequential across services. Building on this view, we identify five research fronts for recommender systems: transparent yet privacy-preserving user modeling, intent translation and alignment, cross-domain representation and memory design, trustworthy commercialization in assistant-mediated environments, and operational mechanisms for ownership, access, and accountability. We position these not as isolated technical challenges, but as interconnected design problems created by the emergence of LLM agents as intermediaries between users and digital platforms. We argue that the future of recommender systems will depend not only on better inference, but on building personalization systems that users can meaningfully understand, shape, and govern.
Diving into Mitigating Hallucinations from a Vision Perspective for Large Vision-Language Models
Sep 17, 2025
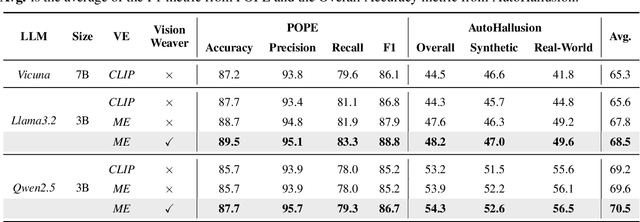
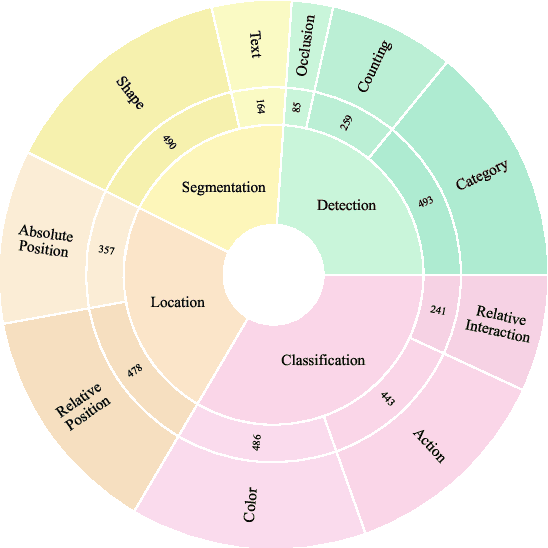
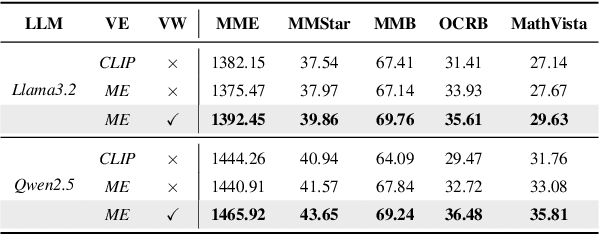
Object hallucination in Large Vision-Language Models (LVLMs) significantly impedes their real-world applicability. As the primary component for accurately interpreting visual information, the choice of visual encoder is pivotal. We hypothesize that the diverse training paradigms employed by different visual encoders instill them with distinct inductive biases, which leads to their diverse hallucination performances. Existing benchmarks typically focus on coarse-grained hallucination detection and fail to capture the diverse hallucinations elaborated in our hypothesis. To systematically analyze these effects, we introduce VHBench-10, a comprehensive benchmark with approximately 10,000 samples for evaluating LVLMs across ten fine-grained hallucination categories. Our evaluations confirm encoders exhibit unique hallucination characteristics. Building on these insights and the suboptimality of simple feature fusion, we propose VisionWeaver, a novel Context-Aware Routing Network. It employs global visual features to generate routing signals, dynamically aggregating visual features from multiple specialized experts. Comprehensive experiments confirm the effectiveness of VisionWeaver in significantly reducing hallucinations and improving overall model performance.
TextFlux: An OCR-Free DiT Model for High-Fidelity Multilingual Scene Text Synthesis
May 23, 2025


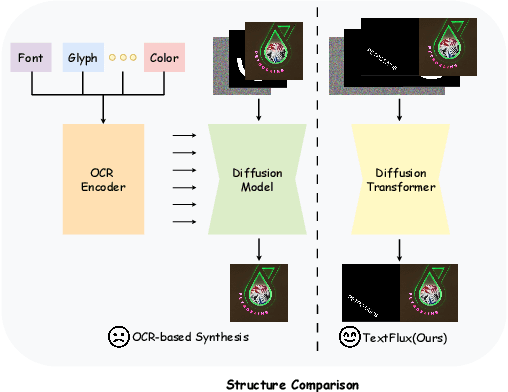
Diffusion-based scene text synthesis has progressed rapidly, yet existing methods commonly rely on additional visual conditioning modules and require large-scale annotated data to support multilingual generation. In this work, we revisit the necessity of complex auxiliary modules and further explore an approach that simultaneously ensures glyph accuracy and achieves high-fidelity scene integration, by leveraging diffusion models' inherent capabilities for contextual reasoning. To this end, we introduce TextFlux, a DiT-based framework that enables multilingual scene text synthesis. The advantages of TextFlux can be summarized as follows: (1) OCR-free model architecture. TextFlux eliminates the need for OCR encoders (additional visual conditioning modules) that are specifically used to extract visual text-related features. (2) Strong multilingual scalability. TextFlux is effective in low-resource multilingual settings, and achieves strong performance in newly added languages with fewer than 1,000 samples. (3) Streamlined training setup. TextFlux is trained with only 1% of the training data required by competing methods. (4) Controllable multi-line text generation. TextFlux offers flexible multi-line synthesis with precise line-level control, outperforming methods restricted to single-line or rigid layouts. Extensive experiments and visualizations demonstrate that TextFlux outperforms previous methods in both qualitative and quantitative evaluations.
MX-Font++: Mixture of Heterogeneous Aggregation Experts for Few-shot Font Generation
Mar 04, 2025Few-shot Font Generation (FFG) aims to create new font libraries using limited reference glyphs, with crucial applications in digital accessibility and equity for low-resource languages, especially in multilingual artificial intelligence systems. Although existing methods have shown promising performance, transitioning to unseen characters in low-resource languages remains a significant challenge, especially when font glyphs vary considerably across training sets. MX-Font considers the content of a character from the perspective of a local component, employing a Mixture of Experts (MoE) approach to adaptively extract the component for better transition. However, the lack of a robust feature extractor prevents them from adequately decoupling content and style, leading to sub-optimal generation results. To alleviate these problems, we propose Heterogeneous Aggregation Experts (HAE), a powerful feature extraction expert that helps decouple content and style downstream from being able to aggregate information in channel and spatial dimensions. Additionally, we propose a novel content-style homogeneity loss to enhance the untangling. Extensive experiments on several datasets demonstrate that our MX-Font++ yields superior visual results in FFG and effectively outperforms state-of-the-art methods. Code and data are available at https://github.com/stephensun11/MXFontpp.
Defining and Evaluating Visual Language Models' Basic Spatial Abilities: A Perspective from Psychometrics
Feb 20, 2025The Theory of Multiple Intelligences underscores the hierarchical nature of cognitive capabilities. To advance Spatial Artificial Intelligence, we pioneer a psychometric framework defining five Basic Spatial Abilities (BSAs) in Visual Language Models (VLMs): Spatial Perception, Spatial Relation, Spatial Orientation, Mental Rotation, and Spatial Visualization. Benchmarking 13 mainstream VLMs through nine validated psychometric experiments reveals significant gaps versus humans (average score 24.95 vs. 68.38), with three key findings: 1) VLMs mirror human hierarchies (strongest in 2D orientation, weakest in 3D rotation) with independent BSAs (Pearson's r<0.4); 2) Smaller models such as Qwen2-VL-7B surpass larger counterparts, with Qwen leading (30.82) and InternVL2 lagging (19.6); 3) Interventions like chain-of-thought (0.100 accuracy gain) and 5-shot training (0.259 improvement) show limits from architectural constraints. Identified barriers include weak geometry encoding and missing dynamic simulation. By linking psychometric BSAs to VLM capabilities, we provide a diagnostic toolkit for spatial intelligence evaluation, methodological foundations for embodied AI development, and a cognitive science-informed roadmap for achieving human-like spatial intelligence.
Dynamic Correlation Learning and Regularization for Multi-Label Confidence Calibration
Jul 09, 2024Modern visual recognition models often display overconfidence due to their reliance on complex deep neural networks and one-hot target supervision, resulting in unreliable confidence scores that necessitate calibration. While current confidence calibration techniques primarily address single-label scenarios, there is a lack of focus on more practical and generalizable multi-label contexts. This paper introduces the Multi-Label Confidence Calibration (MLCC) task, aiming to provide well-calibrated confidence scores in multi-label scenarios. Unlike single-label images, multi-label images contain multiple objects, leading to semantic confusion and further unreliability in confidence scores. Existing single-label calibration methods, based on label smoothing, fail to account for category correlations, which are crucial for addressing semantic confusion, thereby yielding sub-optimal performance. To overcome these limitations, we propose the Dynamic Correlation Learning and Regularization (DCLR) algorithm, which leverages multi-grained semantic correlations to better model semantic confusion for adaptive regularization. DCLR learns dynamic instance-level and prototype-level similarities specific to each category, using these to measure semantic correlations across different categories. With this understanding, we construct adaptive label vectors that assign higher values to categories with strong correlations, thereby facilitating more effective regularization. We establish an evaluation benchmark, re-implementing several advanced confidence calibration algorithms and applying them to leading multi-label recognition (MLR) models for fair comparison. Through extensive experiments, we demonstrate the superior performance of DCLR over existing methods in providing reliable confidence scores in multi-label scenarios.
StackSight: Unveiling WebAssembly through Large Language Models and Neurosymbolic Chain-of-Thought Decompilation
Jun 07, 2024WebAssembly enables near-native execution in web applications and is increasingly adopted for tasks that demand high performance and robust security. However, its assembly-like syntax, implicit stack machine, and low-level data types make it extremely difficult for human developers to understand, spurring the need for effective WebAssembly reverse engineering techniques. In this paper, we propose StackSight, a novel neurosymbolic approach that combines Large Language Models (LLMs) with advanced program analysis to decompile complex WebAssembly code into readable C++ snippets. StackSight visualizes and tracks virtual stack alterations via a static analysis algorithm and then applies chain-of-thought prompting to harness LLM's complex reasoning capabilities. Evaluation results show that StackSight significantly improves WebAssembly decompilation. Our user study also demonstrates that code snippets generated by StackSight have significantly higher win rates and enable a better grasp of code semantics.