 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Regularized Federated Learning for Cross-Domain Aspect Sentiment Triplet Extraction
Apr 10, 2026Aspect Sentiment Triplet Extraction (ASTE) aims to extract all sentiment triplets of aspect terms, opinion terms, and sentiment polarities from a sentence. Existing methods are typically trained on individual datasets in isolation, failing to jointly capture the common feature representations shared across domains. Moreover, data privacy constraints prevent centralized data aggregation. To address these challenges, we propose Prototype-based Cross-Domain Span Prototype extraction (PCD-SpanProto), a prototype-regularized federated learning framework to enable distributed clients to exchange class-level prototypes instead of full model parameters. Specifically, we design a weighted performance-aware aggregation strategy and a contrastive regularization module to improve the global prototype under domain heterogeneity and the promotion between intra-class compactness and inter-class separability across clients. Extensive experiments on four ASTE datasets demonstrate that our method outperforms baselines and reduces communication costs, validating the effectiveness of prototype-based cross-domain knowledge transfer.
LLM-assisted Semantic Option Discovery for Facilitating Adaptive Deep Reinforcement Learning
Mar 02, 2026Despite achieving remarkable success in complex tasks, Deep Reinforcement Learning (DRL) is still suffering from critical issues in practical applications, such as low data efficiency, lack of interpretability, and limited cross-environment transferability. However, the learned policy generating actions based on states are sensitive to the environmental changes, struggling to guarantee behavioral safety and compliance. Recent research shows that integrating Large Language Models (LLMs) with symbolic planning is promising in addressing these challenges. Inspired by this, we introduce a novel LLM-driven closed-loop framework, which enables semantic-driven skill reuse and real-time constraint monitoring by mapping natural language instructions into executable rules and semantically annotating automatically created options. The proposed approach utilizes the general knowledge of LLMs to facilitate exploration efficiency and adapt to transferable options for similar environments, and provides inherent interpretability through semantic annotations. To validate the effectiveness of this framework, we conduct experiments on two domains, Office World and Montezuma's Revenge, respectively. The results demonstrate superior performance in data efficiency, constraint compliance, and cross-task transferability.
PR-CapsNet: Pseudo-Riemannian Capsule Network with Adaptive Curvature Routing for Graph Learning
Dec 09, 2025Capsule Networks (CapsNets) show exceptional graph representation capacity via dynamic routing and vectorized hierarchical representations, but they model the complex geometries of real\-world graphs poorly by fixed\-curvature space due to the inherent geodesical disconnectedness issues, leading to suboptimal performance. Recent works find that non\-Euclidean pseudo\-Riemannian manifolds provide specific inductive biases for embedding graph data, but how to leverage them to improve CapsNets is still underexplored. Here, we extend the Euclidean capsule routing into geodesically disconnected pseudo\-Riemannian manifolds and derive a Pseudo\-Riemannian Capsule Network (PR\-CapsNet), which models data in pseudo\-Riemannian manifolds of adaptive curvature, for graph representation learning. Specifically, PR\-CapsNet enhances the CapsNet with Adaptive Pseudo\-Riemannian Tangent Space Routing by utilizing pseudo\-Riemannian geometry. Unlike single\-curvature or subspace\-partitioning methods, PR\-CapsNet concurrently models hierarchical and cluster or cyclic graph structures via its versatile pseudo\-Riemannian metric. It first deploys Pseudo\-Riemannian Tangent Space Routing to decompose capsule states into spherical\-temporal and Euclidean\-spatial subspaces with diffeomorphic transformations. Then, an Adaptive Curvature Routing is developed to adaptively fuse features from different curvature spaces for complex graphs via a learnable curvature tensor with geometric attention from local manifold properties. Finally, a geometric properties\-preserved Pseudo\-Riemannian Capsule Classifier is developed to project capsule embeddings to tangent spaces and use curvature\-weighted softmax for classification. Extensive experiments on node and graph classification benchmarks show PR\-CapsNet outperforms SOTA models, validating PR\-CapsNet's strong representation power for complex graph structures.
AssoCiAm: A Benchmark for Evaluating Association Thinking while Circumventing Ambiguity
Sep 18, 2025Recent advancements in multimodal large language models (MLLMs) have garnered significant attention, offering a promising pathway toward artificial general intelligence (AGI). Among the essential capabilities required for AGI, creativity has emerged as a critical trait for MLLMs, with association serving as its foundation. Association reflects a model' s ability to think creatively, making it vital to evaluate and understand. While several frameworks have been proposed to assess associative ability, they often overlook the inherent ambiguity in association tasks, which arises from the divergent nature of associations and undermines the reliability of evaluations. To address this issue, we decompose ambiguity into two types-internal ambiguity and external ambiguity-and introduce AssoCiAm, a benchmark designed to evaluate associative ability while circumventing the ambiguity through a hybrid computational method. We then conduct extensive experiments on MLLMs, revealing a strong positive correlation between cognition and association. Additionally, we observe that the presence of ambiguity in the evaluation process causes MLLMs' behavior to become more random-like. Finally, we validate the effectiveness of our method in ensuring more accurate and reliable evaluations. See Project Page for the data and codes.
Boundary-Driven Table-Filling with Cross-Granularity Contrastive Learning for Aspect Sentiment Triplet Extraction
Feb 04, 2025



The Aspect Sentiment Triplet Extraction (ASTE) task aims to extract aspect terms, opinion terms, and their corresponding sentiment polarity from a given sentence. It remains one of the most prominent subtasks in fine-grained sentiment analysis. Most existing approaches frame triplet extraction as a 2D table-filling process in an end-to-end manner, focusing primarily on word-level interactions while often overlooking sentence-level representations. This limitation hampers the model's ability to capture global contextual information, particularly when dealing with multi-word aspect and opinion terms in complex sentences. To address these issues, we propose boundary-driven table-filling with cross-granularity contrastive learning (BTF-CCL) to enhance the semantic consistency between sentence-level representations and word-level representations. By constructing positive and negative sample pairs, the model is forced to learn the associations at both the sentence level and the word level. Additionally, a multi-scale, multi-granularity convolutional method is proposed to capture rich semantic information better. Our approach can capture sentence-level contextual information more effectively while maintaining sensitivity to local details. Experimental results show that the proposed method achieves state-of-the-art performance on public benchmarks according to the F1 score.
Adaptive Few-shot Prompting for Machine Translation with Pre-trained Language Models
Jan 03, 2025Recently, Large language models (LLMs) with in-context learning have demonstrated remarkable potential in handling neural machine translation. However, existing evidence shows that LLMs are prompt-sensitive and it is sub-optimal to apply the fixed prompt to any input for downstream machine translation tasks. To address this issue, we propose an adaptive few-shot prompting (AFSP) framework to automatically select suitable translation demonstrations for various source input sentences to further elicit the translation capability of an LLM for better machine translation. First, we build a translation demonstration retrieval module based on LLM's embedding to retrieve top-k semantic-similar translation demonstrations from aligned parallel translation corpus. Rather than using other embedding models for semantic demonstration retrieval, we build a hybrid demonstration retrieval module based on the embedding layer of the deployed LLM to build better input representation for retrieving more semantic-related translation demonstrations. Then, to ensure better semantic consistency between source inputs and target outputs, we force the deployed LLM itself to generate multiple output candidates in the target language with the help of translation demonstrations and rerank these candidates. Besides, to better evaluate the effectiveness of our AFSP framework on the latest language and extend the research boundary of neural machine translation, we construct a high-quality diplomatic Chinese-English parallel dataset that consists of 5,528 parallel Chinese-English sentences. Finally, extensive experiments on the proposed diplomatic Chinese-English parallel dataset and the United Nations Parallel Corpus (Chinese-English part) show the effectiveness and superiority of our proposed AFSP.
Learning Semantic-Aware Representation in Visual-Language Models for Multi-Label Recognition with Partial Labels
Dec 14, 2024



Multi-label recognition with partial labels (MLR-PL), in which only some labels are known while others are unknown for each image, is a practical task in computer vision, since collecting large-scale and complete multi-label datasets is difficult in real application scenarios. Recently, vision language models (e.g. CLIP) have demonstrated impressive transferability to downstream tasks in data limited or label limited settings. However, current CLIP-based methods suffer from semantic confusion in MLR task due to the lack of fine-grained information in the single global visual and textual representation for all categories. In this work, we address this problem by introducing a semantic decoupling module and a category-specific prompt optimization method in CLIP-based framework. Specifically, the semantic decoupling module following the visual encoder learns category-specific feature maps by utilizing the semantic-guided spatial attention mechanism. Moreover, the category-specific prompt optimization method is introduced to learn text representations aligned with category semantics. Therefore, the prediction of each category is independent, which alleviate the semantic confusion problem. Extensive experiments on Microsoft COCO 2014 and Pascal VOC 2007 datasets demonstrate that the proposed framework significantly outperforms current state-of-art methods with a simpler model structure. Additionally, visual analysis shows that our method effectively separates information from different categories and achieves better performance compared to CLIP-based baseline method.
Dynamic Correlation Learning and Regularization for Multi-Label Confidence Calibration
Jul 09, 2024Modern visual recognition models often display overconfidence due to their reliance on complex deep neural networks and one-hot target supervision, resulting in unreliable confidence scores that necessitate calibration. While current confidence calibration techniques primarily address single-label scenarios, there is a lack of focus on more practical and generalizable multi-label contexts. This paper introduces the Multi-Label Confidence Calibration (MLCC) task, aiming to provide well-calibrated confidence scores in multi-label scenarios. Unlike single-label images, multi-label images contain multiple objects, leading to semantic confusion and further unreliability in confidence scores. Existing single-label calibration methods, based on label smoothing, fail to account for category correlations, which are crucial for addressing semantic confusion, thereby yielding sub-optimal performance. To overcome these limitations, we propose the Dynamic Correlation Learning and Regularization (DCLR) algorithm, which leverages multi-grained semantic correlations to better model semantic confusion for adaptive regularization. DCLR learns dynamic instance-level and prototype-level similarities specific to each category, using these to measure semantic correlations across different categories. With this understanding, we construct adaptive label vectors that assign higher values to categories with strong correlations, thereby facilitating more effective regularization. We establish an evaluation benchmark, re-implementing several advanced confidence calibration algorithms and applying them to leading multi-label recognition (MLR) models for fair comparison. Through extensive experiments, we demonstrate the superior performance of DCLR over existing methods in providing reliable confidence scores in multi-label scenarios.
Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima
Feb 17, 2024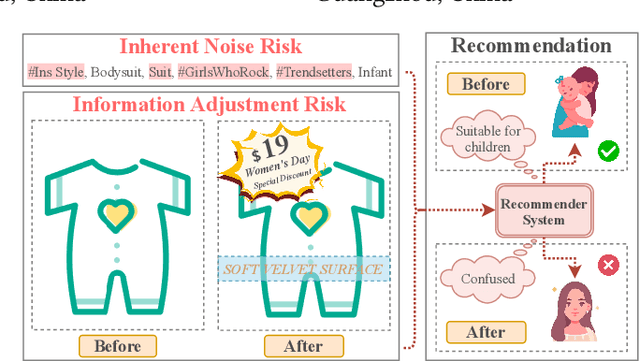
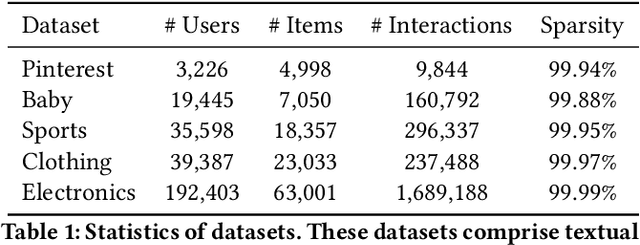
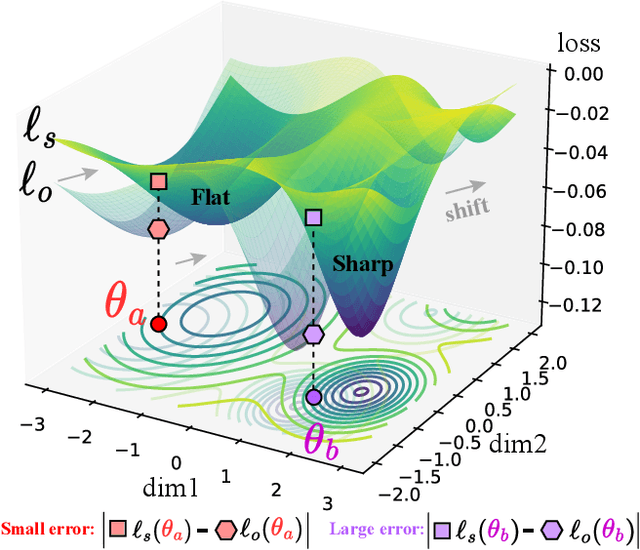
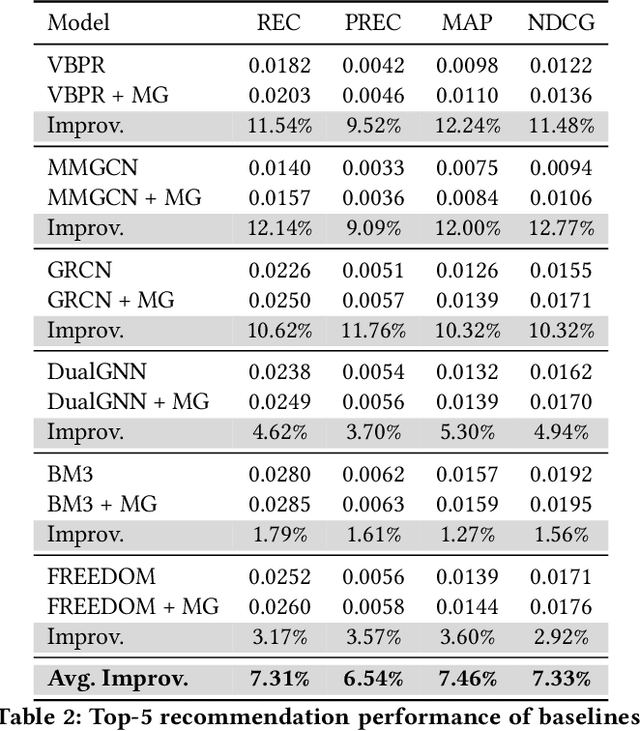
Multimodal recommender systems utilize various types of information to model user preferences and item features, helping users discover items aligned with their interests. The integration of multimodal information mitigates the inherent challenges in recommender systems, e.g., the data sparsity problem and cold-start issues. However, it simultaneously magnifies certain risks from multimodal information inputs, such as information adjustment risk and inherent noise risk. These risks pose crucial challenges to the robustness of recommendation models. In this paper, we analyze multimodal recommender systems from the novel perspective of flat local minima and propose a concise yet effective gradient strategy called Mirror Gradient (MG). This strategy can implicitly enhance the model's robustness during the optimization process, mitigating instability risks arising from multimodal information inputs. We also provide strong theoretical evidence and conduct extensive empirical experiments to show the superiority of MG across various multimodal recommendation models and benchmarks. Furthermore, we find that the proposed MG can complement existing robust training methods and be easily extended to diverse advanced recommendation models, making it a promising new and fundamental paradigm for training multimodal recommender systems. The code is released at https://github.com/Qrange-group/Mirror-Gradient.
ADASR: An Adversarial Auto-Augmentation Framework for Hyperspectral and Multispectral Data Fusion
Oct 11, 2023Deep learning-based hyperspectral image (HSI) super-resolution, which aims to generate high spatial resolution HSI (HR-HSI) by fusing hyperspectral image (HSI) and multispectral image (MSI) with deep neural networks (DNNs), has attracted lots of attention. However, neural networks require large amounts of training data, hindering their application in real-world scenarios. In this letter, we propose a novel adversarial automatic data augmentation framework ADASR that automatically optimizes and augments HSI-MSI sample pairs to enrich data diversity for HSI-MSI fusion. Our framework is sample-aware and optimizes an augmentor network and two downsampling networks jointly by adversarial learning so that we can learn more robust downsampling networks for training the upsampling network. Extensive experiments on two public classical hyperspectral datasets demonstrate the effectiveness of our ADASR compared to the state-of-the-art methods.